标签:date() out log 通过 函数 exce 遇到 源码 默认
在我们执行scrapy爬取字段中,会有大量的和下面的代码,当要爬取的网站多了,要维护起来很麻烦,为解决这类问题,我们可以根据scrapy提供的loader机制
def parse_detail(self, response): """ 获取文章详情页 :param response: :return: """ article_item = JoBoleArticleItem() #封面图,使用get方法有个好处,如果图片不存在。不会抛异常。 front_image_url = response.meta.get("front_image_url","") ret_str = response.xpath(‘//*[@class="dht_dl_date_content"]‘) title = response.css("div.entry-header h1::text").extract_first() create_date = response.css("p.entry-meta-hide-on-mobile::text").extract_first().strip().replace("·", "").strip() content = response.xpath("//*[@id=‘post-112239‘]/div[3]/div[3]/p[1]") article_item["title"] = title
首先,导入 ItemLoader
from scrapy.loader import ItemLoader
可以查看源码,这里先关注的是item和response两入参
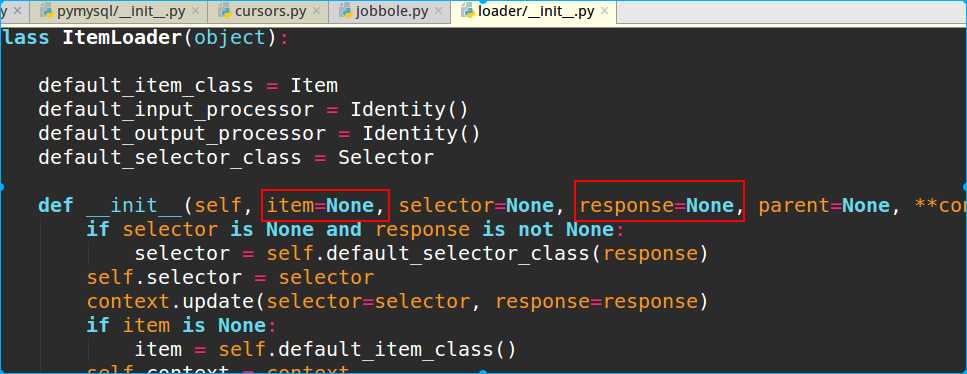
#通过item loader加载item item_loader = ItemLoader(item=JoBoleArticleItem(),response=response) #针对直接取值的情况 item_loader.add_value(‘front_image_url‘,‘front_image_url‘) #针对css选择器 item_loader.add_css(‘title‘,‘div.entry-header h1::text‘) item_loader.add_css(‘create_date‘,‘p.entry-meta-hide-on-mobile::text‘) item_loader.add_css(‘praise_num‘,‘#112547votetotal::text‘) #针对xpath的情况 item_loader.add_xpath(‘content‘,‘//*[@id="post-112239"]/div[3]/div[3]/p[1]‘) #把结果返回给item对象 article_item = item_loader.load_item()
debug调试,可以看到拿到的信息
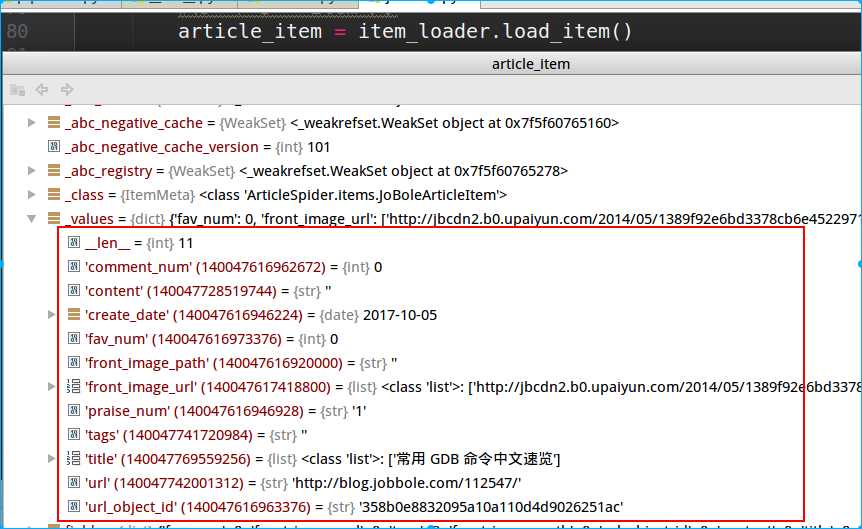
不过实际情况,可能1、我们只取返回结果的某个元素。2、拿到返回结果后还需要执行某些函数。 这个scrapy也提供了方法:
在items.py文件里操作
from scrapy.loader.processors import MapCompose
这个类我们可以传递任意多的函数进来处理
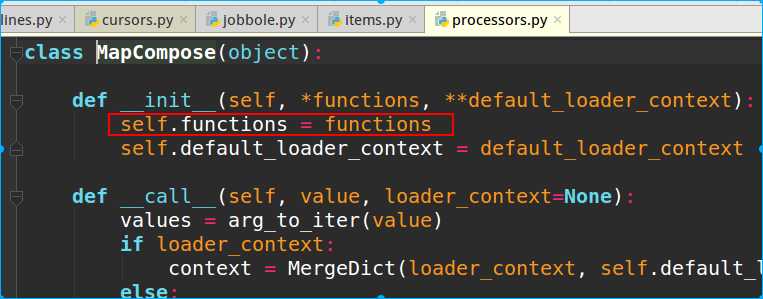
导入模块后,
在Field的入参里可以传入这个函数,方式如下,其中MapCompose里填的是函数名,而调用的这个alter_title函数的入参,就是title的拿到的值。
def alter_title(value): return value + "-白菜被猪拱了" class JoBoleArticleItem(scrapy.Item): #标题 title = scrapy.Field( input_processor = MapCompose(alter_title) )
debug调试下,
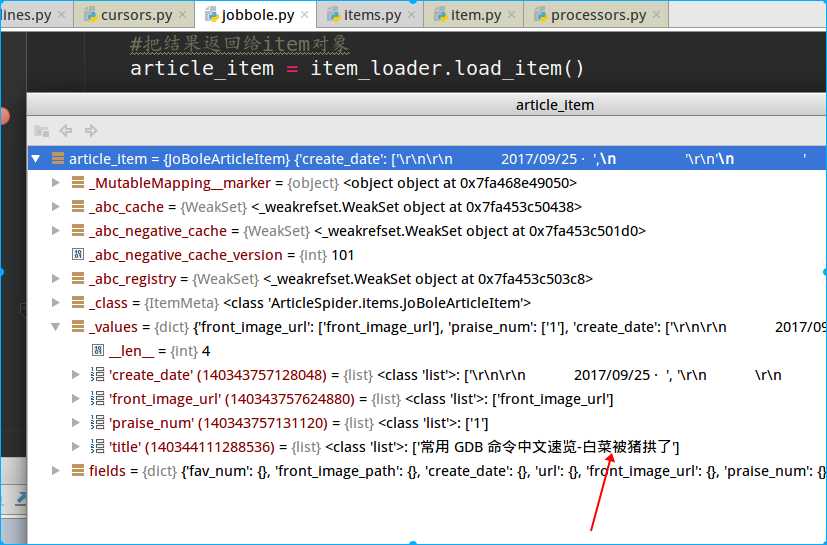
在loader机制中也有类似extract_firest的方法:TakeFirst
from scrapy.loader.processors import MapCompose,TakeFirst
然后在下面的:
经测试 input_processor和output_processor同时存在时,会把input进行预处理拿到的返回值继续给output处理,返回最终结果给item
import datetime def date_convert(value): try : create_date = datetime.datetime.strftime(value,"%Y/%m/%d").date() except Exception as e: create_date = datetime.datetime.now().date() return create_date class JoBoleArticleItem(scrapy.Item): #标题 title = scrapy.Field( input_processor = MapCompose(alter_title) ) #创建日期 create_date = scrapy.Field( # = MapCompose(date_convert), input_processor = MapCompose(date_convert), output_processor = TakeFirst() )
如果要每个字段都要单独调用这个TakeFirst方法,会有些麻烦,可以通过自定义ItemLoader,首先导入ItemLoader进行重载
from scrapy.loader import ItemLoader
点开ItemLoader源码,可以查看到有个default_output_processor
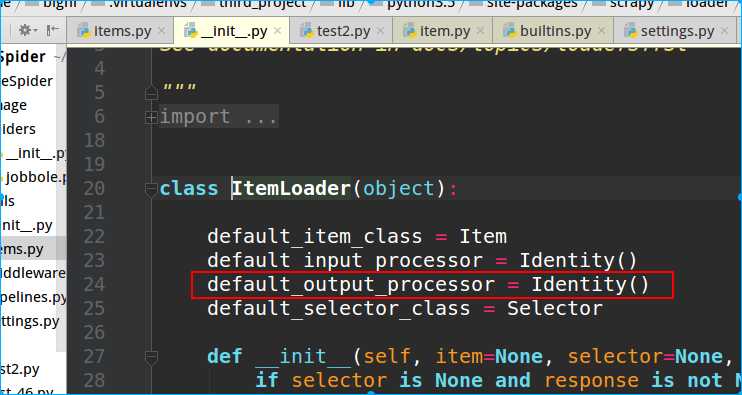
然后我们给ItemLoader重载这个default_output_processor
class ArticleItemLoader(ItemLoader): #自定义ItemLoader default_output_processor = TakeFirst()
然后在创建itemloader对象时使用自定义的loader:ArticleItemLoader
item_loader = ArticleItemLoader(item=JoBoleArticleItem(),response=response) #针对直接取值的情况 item_loader.add_value(‘front_image_url‘,‘front_image_url‘) item_loader.add_value(‘front_image_path‘,‘‘) item_loader.add_value(‘url‘,response.url) item_loader.add_value(‘url_object_id‘,get_md5(response.url)) item_loader.add_value(‘content‘,‘‘)
debug调试,可以看到获取到的value由list变成str
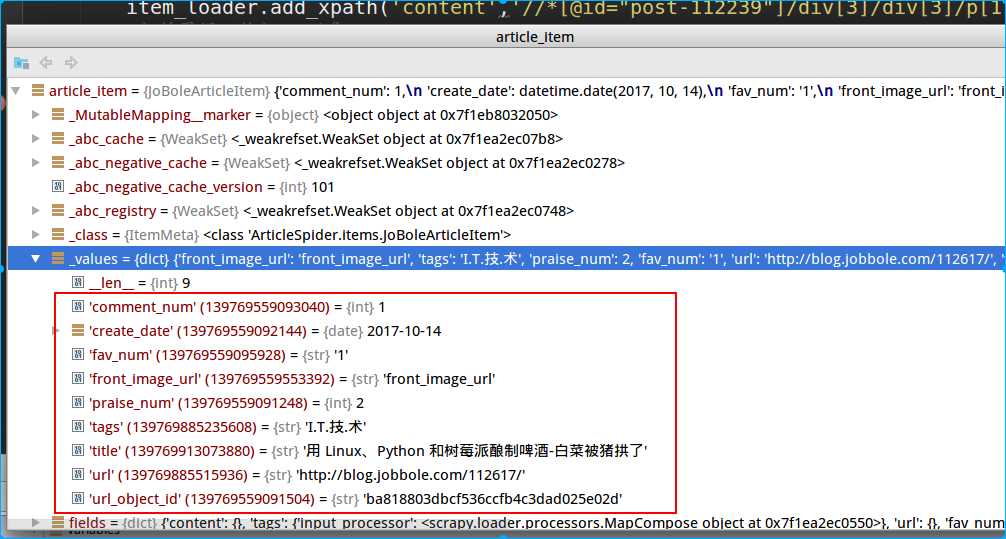
PS:这里只是把默认的output_processor制定了一个方法,所以如果存在某些item 不想调用默认的output_processor,可以继续在add_value方法里单独传output方法。
问题:
1、调试时遇到下面这错误,一般是由于传递给items.py的数据里缺少了字段、传递的字段和数据表里的字段的类型不符等
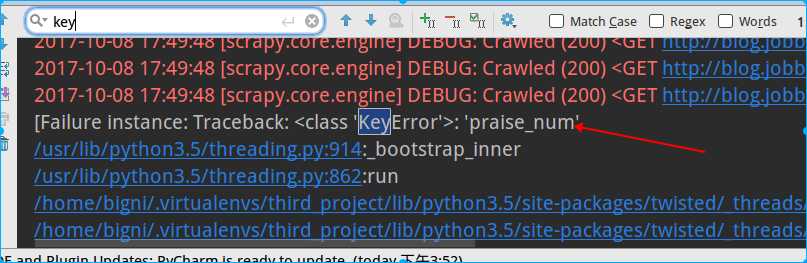
2
标签:date() out log 通过 函数 exce 遇到 源码 默认
原文地址:http://www.cnblogs.com/laonicc/p/7629478.html