标签:blog http os 数据 div 问题 sp log on
临时研究了下机器视觉两个基本算法的算法原理 ,可能有理解错误的地方,希望发现了告诉我一下
主要是了解思想,就不写具体的计算公式之类的了
(一) ICP算法(Iterative Closest Point迭代最近点)
ICP(Iterative Closest Point迭代最近点)算法是一种点集对点集配准方法,如下图1
如下图,假设PR(红色块)和RB(蓝色块)是两个点集,该算法就是计算怎么把PB平移旋转,使PB和PR尽量重叠,建立模型的
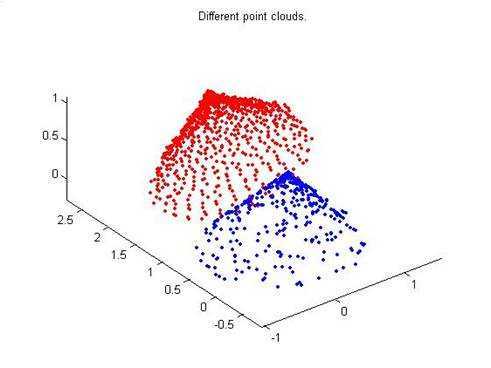 (图1)
(图1)
ICP是改进自对应点集配准算法的
对应点集配准算法是假设一个理想状况,将一个模型点云数据X(如上图的PB)利用四元数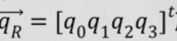 旋转,并平移
旋转,并平移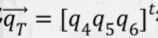 得到点云P(类似于上图的PR)。而对应点集配准算法主要就是怎么计算出qR和qT的,知道这两个就可以匹配点云了。
得到点云P(类似于上图的PR)。而对应点集配准算法主要就是怎么计算出qR和qT的,知道这两个就可以匹配点云了。
但是对应点集配准算法的前提条件是计算中的点云数据PB和PR的元素一一对应,这个条件在现实里因误差等问题,不太可能实线,所以就有了ICP算法
ICP算法是从源点云上的(PB)每个点 先计算出目标点云(PR)的每个点的距离,使每个点和目标云的最近点匹配,(记得这种映射方式叫满射吧)
这样满足了对应点集配准算法的前提条件、每个点都有了对应的映射点,则可以按照对应点集配准算法计算,但因为这个是假设,所以需要重复迭代运行上述过程,直到均方差误差小于某个阀值。
也就是说 每次迭代,整个模型是靠近一点,每次都重新找最近点,然后再根据对应点集批准算法算一次,比较均方差误差,如果不满足就继续迭代
(二)RANSAC算法(RANdom SAmple Consensus随机抽样一致)
它可以从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数。它是一种不确定的算法——它有一定的概率得出一个合理的结果;为了提高概率必须提高迭代次数。该算法最早由Fischler和Bolles于1981年提出。
光看文字还是太抽象了,我们再用图描述
RANSAC的基本假设是:
(1)数据由“局内点”组成,例如:数据的分布可以用一些模型参数来解释;
(2)“局外点”是不能适应该模型的数据;
(3)除此之外的数据属于噪声。
而下图二里面、蓝色部分为局内点,而红色部分就是局外点,而这个算法要算出的就是蓝色部分那个模型的参数
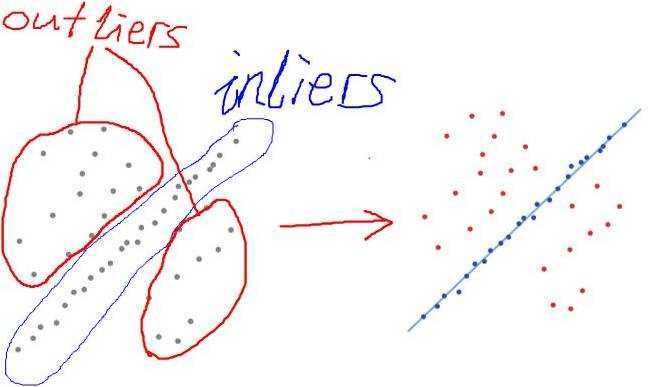 (图二)
(图二)
RANSAC算法的输入是一组观测数据,一个可以解释或者适应于观测数据的参数化模型,一些可信的参数。
在上图二中 左半部分灰色的点为观测数据,一个可以解释或者适应于观测数据的参数化模型 我们可以在这个图定义为一条直线,如y=kx + b;
一些可信的参数指的就是指定的局内点范围。而k,和b就是我们需要用RANSAC算法求出来的
RANSAC通过反复选择数据中的一组随机子集来达成目标。被选取的子集被假设为局内点,并用下述方法进行验证:
1.有一个模型适应于假设的局内点,即所有的未知参数都能从假设的局内点计算得出。
2.用1中得到的模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是局内点。
3.如果有足够多的点被归类为假设的局内点,那么估计的模型就足够合理。
4.然后,用所有假设的局内点去重新估计模型,因为它仅仅被初始的假设局内点估计过。
5.最后,通过估计局内点与模型的错误率来评估模型。
这个过程被重复执行固定的次数,每次产生的模型要么因为局内点太少而被舍弃,要么因为比现有的模型更好而被选用。
这个算法用图二的例子说明就是先随机找到内点,计算k1和b1,再用这个模型算其他内点是不是也满足y=k1x+b2,评估模型
再跟后面的两个随机的内点算出来的k2和b2比较模型评估值,不停迭代最后找到最优点
我再用图一的模型说明一下RANSAC算法
(图1)
RANSAC算法的输入是一组观测数据,一个可以解释或者适应于观测数据的参数化模型,一些可信的参数。
旋转,并平移
标签:blog http os 数据 div 问题 sp log on
原文地址:http://www.cnblogs.com/zhizhan/p/3966760.html