标签:osi lock add 结合 pad 实际应用 梯度 一个 blog
梯度下降是一个用于求解函数最小值的算法。在机器学习问题上,我们通常会得出模型的代价函数,用于评估模型与真实情况之间的差距。通常我们在确定模型时,会将代价函数取最小时的参数值作为我们模型的最终参数。而,在"找出使得代价函数取最小时的参数值"这一重要步骤的求解过程中,我们通常会见到梯度下降大法的身影。梯度下降法因其思想简单,易于实现,并且收敛效果也很不错的质地,使得它在机器学习领域混的那是相当好!
本文包含了我在学习梯度下降时的心路历程以及心得收获,希望可以给像我一样刚开始学习ML的小菜鸟提供一些帮助。
本文想要呈现的主要内容有:
1. 梯度下降的思想?
2. 梯度下降的数学表示?
3. 学习率的选择,如何选取最适合的学习率?
4. 为什么负梯度方向是下降最快的方向?
梯度下降的思想是相当简单,我们再举一个在介绍梯度下降的神文中都要举烂的一个例子,没错就是下山,呵呵。
催眠开始啦!现在请闭上眼,试着想象一下,不知什么原因使你现在出现在了一个漆黑阴森的山顶上,你环顾了一下四周,发现山下灯火通明热闹非凡,此时你最小做的事情是什么?因该是下山,而且是以最快的速度下山,没错吧。既然有了想法就开始行动吧,这时候你会想"山这么高,这么大,在山看来自己想尘埃一样渺小,所以我根本不可能一下子想到一个最佳的路线,所以只能走一步算一步,保证我每一步都是朝着下降最多的方向走就行啦"。具体做法就是,你站在山顶环顾一下四周,默默问一下自己在那个方向上下山最快呢,然后你朝着你认为下山最快的方向迈出你的第一步;现在又到了一个新的位置,再一次环顾一下四周,默默问一下自己在那个方向上下山最快呢,然后你朝着你认为下山最快的方向迈出你的第二步,一直重复这个过程,直到你到达山下位置。
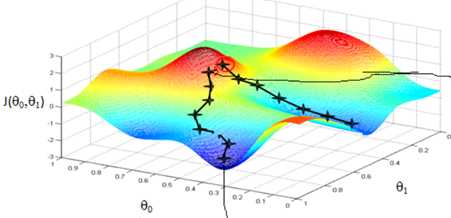
我们再结合这个例子看一下梯度下降的实际操作是什么样子的:开始时我们随机选择一个参数的组合(这就相当于让你在山的任一一个位置下山),计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合,我们持续的重复这个过程直到到达一个局部最小值!注:因为我们并没有尝试所有的参数组合,所以我们并不能确定得到的局部最小值是不是全局最小值,所以我们如果选择不同的参数组合,可能会找到不用的局部最小值(像上图一样)。
相信经过上面的催眠,我们已经对梯度下降有了一个大体上的把握,接下来就让我们细细品味梯度下降的算法公式吧:
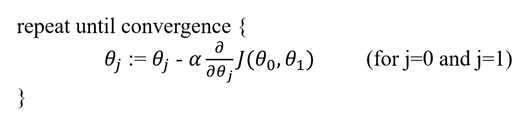
其中,![]() 是学习率(learning rate),它表示的是沿着下降最快的方向下降的步长有多长,相当于表示你下山迈的步子大小;既然这样那
是学习率(learning rate),它表示的是沿着下降最快的方向下降的步长有多长,相当于表示你下山迈的步子大小;既然这样那![]() 就应该是表示的下降方向了吧。这就是梯度下降参数的更新过程。还有一个需要我们注意的地方,我们平时所实现的梯度下降参数都是同步更新的(如下图),同步更新是梯度下降的一种常态!
就应该是表示的下降方向了吧。这就是梯度下降参数的更新过程。还有一个需要我们注意的地方,我们平时所实现的梯度下降参数都是同步更新的(如下图),同步更新是梯度下降的一种常态!
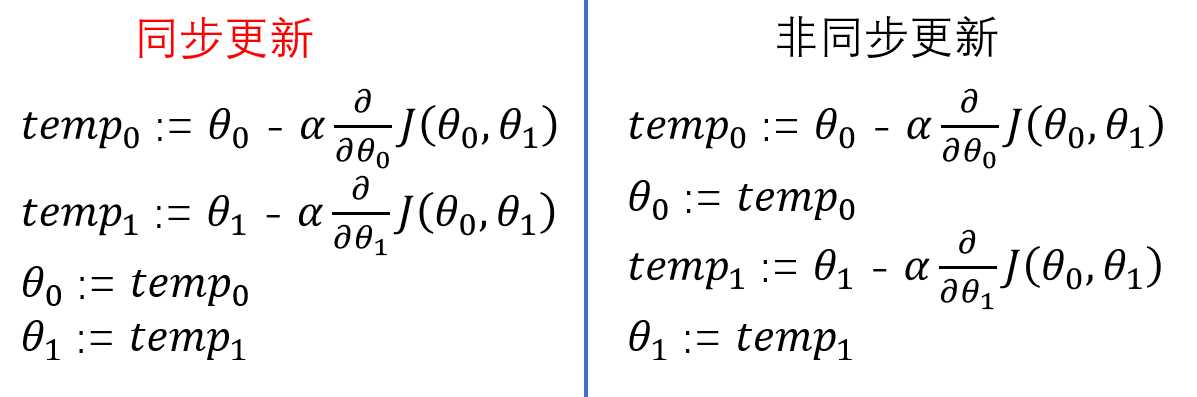
现在我们对梯度下降有了一个整体把握(下山)也知道了它的数学表示。你看到这,可能会想“为啥损失函数的偏导指向下降最快的方向呢?”还有“步长a是怎么确定的呢或者说a的选择有啥讲究?”,是不是这么想的,哈哈,这可是梯度下降的精华所在!下面我们一一解答:
Q: 步长a这么确定的呢或者说a的选择有啥讲究?
![]() 是学习率(learning rate),它控制着我们将以多大的幅度来更新我们参数
是学习率(learning rate),它控制着我们将以多大的幅度来更新我们参数![]() 。中庸之道-“凡事有个度”。凡事都是这样,有个度,取大不好,取小不好,取的合适才是最好。我们先来看看如果
。中庸之道-“凡事有个度”。凡事都是这样,有个度,取大不好,取小不好,取的合适才是最好。我们先来看看如果![]() 太大或太小会出现什么情况:
太大或太小会出现什么情况:
如果![]() 太小,这样我们参数的更新幅度就会非常小(就像你下山每次走个1mm那你猴年马月才能到达山下呀),再说了更新幅度也不只是和学习率有关,还和后面偏导项有关,我看看左图当我们越接近最低点时,是不是曲线的切线斜率也逐渐变得平稳了,偏导项的绝对值也变得越来越小。这就说明更新的学习率虽然不变,但是更新的幅度也会自动的变小,这样就会需要很多步才能到达最低点,这就带来了时间上的浪费,是不是。
太小,这样我们参数的更新幅度就会非常小(就像你下山每次走个1mm那你猴年马月才能到达山下呀),再说了更新幅度也不只是和学习率有关,还和后面偏导项有关,我看看左图当我们越接近最低点时,是不是曲线的切线斜率也逐渐变得平稳了,偏导项的绝对值也变得越来越小。这就说明更新的学习率虽然不变,但是更新的幅度也会自动的变小,这样就会需要很多步才能到达最低点,这就带来了时间上的浪费,是不是。
如果![]() 太大呢,这样它就可能挣脱“地心引力”(右侧图),为什么会这样呢,实际上随着迭代步数的增加,偏导项的绝对值会逐渐变大,这就使得这种梯度下降法完美的越过了最低点,并且里最低点会越来越远,导致无法收敛的情况发生。
太大呢,这样它就可能挣脱“地心引力”(右侧图),为什么会这样呢,实际上随着迭代步数的增加,偏导项的绝对值会逐渐变大,这就使得这种梯度下降法完美的越过了最低点,并且里最低点会越来越远,导致无法收敛的情况发生。
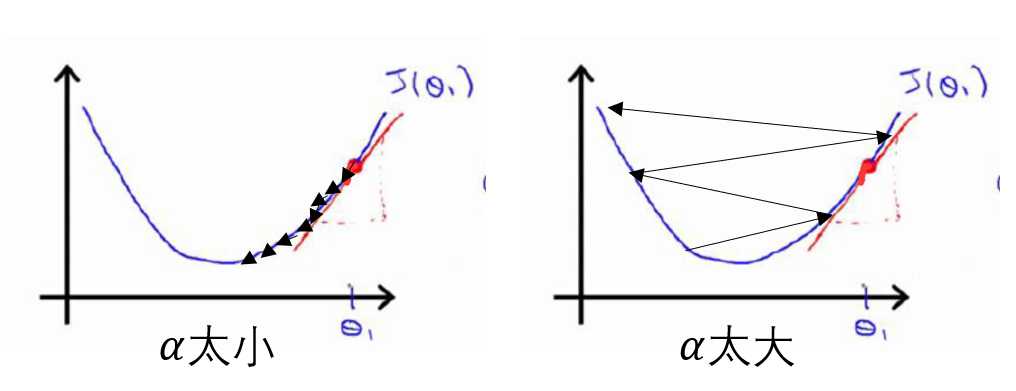
总结:学习率对梯度下降算法的收敛性和收敛速度有着至关重要的影响。此外,我们发现即使在学习率固定的情况下,梯度下降法也会自动的采取更小的幅度以确保其可以收敛到局部最低点,因此在实际工作中,我们没有必要在另外减小![]() 的值!
的值!
上面我们了解到了学习率对梯度下降的影响了,那么我们怎么才能选择合适的学习率呢?
首先我们要知道,如何才能确定你的梯度下降是否正确工作?通常的做法就是在执行梯度下降时,顺带着画出代价函数随着迭代次数增加而变化的曲线(如图),由曲线的表现来判断我们的梯度下降是否收敛以及收敛速度是快是慢。
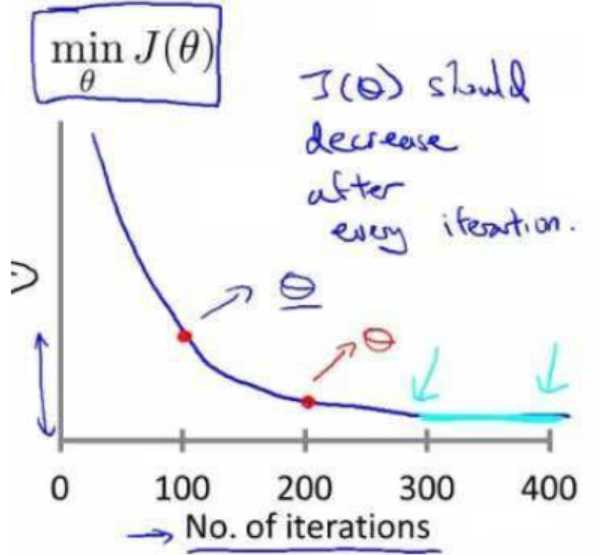
有了可以检测梯度下降工作效果的方法后,接下来我们可以尝试一系列的![]() 值:
值:
……, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10, …… (大约间隔3倍)
然后结合这代价函数![]() 与迭代次数的变化曲线看在此学习率下梯度下降能否正常工作,确定了可以使得梯度下降正常工作的学习率后,我们通常会选择其中尽可能大的那个
与迭代次数的变化曲线看在此学习率下梯度下降能否正常工作,确定了可以使得梯度下降正常工作的学习率后,我们通常会选择其中尽可能大的那个![]() (比最大小点的也可行,视情况而定),这是因为我们希望在保证梯度下降正确工作的前提下我们希望它的收敛速度尽可能的快。这是吴恩达老师视频中提到的方法,很实用。学习率的知识也差不多只有这些了。
(比最大小点的也可行,视情况而定),这是因为我们希望在保证梯度下降正确工作的前提下我们希望它的收敛速度尽可能的快。这是吴恩达老师视频中提到的方法,很实用。学习率的知识也差不多只有这些了。
Q: 为啥损失函数的偏导指向下降最快的方向呢?
就函数上某一确定点x来说,通常我们认为负梯度方向是使函数f在点x附近下降最快的方向。为什么会这么说呢?这就要从那些年我们一起记过的泰勒展式说起。
![]()
再就是函数![]() 在
在![]() 点的泰勒展开式,
点的泰勒展开式,![]() 为泰勒公式余项。
为泰勒公式余项。
结合这个场景我们只保留一级导数项,其就变成了:
![]()
我们假设用![]() 表示步长,那么
表示步长,那么![]() ,
,![]() 表示变化的方向,故现在上面公式就可以写成:
表示变化的方向,故现在上面公式就可以写成:
![]()
现在我们的问题就变成了:![]() 固定并且大于0,试确定
固定并且大于0,试确定![]() 的值使得
的值使得![]() 最大。
最大。
要解决这个问题,我们就要用到柯西不等式了:
(a1b1+a2b2+?+anbn)2≤(a21+a22+?+a2n)(b21+b22+?+b2n)
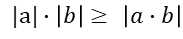
|ab|什么时候取最大值呢?就是a = b 的时候。同理
![]()
当且仅当![]() , 取得最大,上升最快;当然,
, 取得最大,上升最快;当然,![]() 时,取得最小,下降最快。
时,取得最小,下降最快。
故,在局部来看,函数在某点的负梯度方向是当前下降最快的方向。
我们在这篇本章中,用一种比较形象的方式介绍了什么是梯度下降,梯度下降的思想是啥样的。然后我们对梯度下降的数学公式做了一点的刨析,在这个刨析过程中,我们还讨论了学习率对梯度下降的影响,即我们得出了这样的结论:学习率过小,可以保证算法的收敛性,但是收敛速度的话就差强人意了;学习率太大,就会使得梯度下降“完美”的跨过最低点,使得算法不收敛,甚至于发散。基于此,我们给出了实际应用中我们是如何确定最合适的学习率的。最后我们对“为什么负梯度方向是函数在该点局部变化最大的方向”这个问题展开了论述和证明。
最后,感谢大家花出时间查看这篇文档,衷心希望这篇文档对你有所帮助!若文档中有什么不当之处,希望大家能够毫不吝啬的批评指正,相互交流一起成长!
标签:osi lock add 结合 pad 实际应用 梯度 一个 blog
原文地址:http://www.cnblogs.com/lianyingteng/p/7679825.html