标签:map 出错 程序 作者 cer 功能 问题 cat blog
问题提出:
众所周知,Hadoop框架使用Mapper将数据处理成一个<key,value>键值对,再网络节点间对其进行整理(shuffle),然后使用Reducer处理数据并进行最终输出。 在上述过程中,我们看到至少两个性能瓶颈:(引用)
目标:
Mapreduce中的Combiner就是为了避免map任务和reduce任务之间的数据传输而设置的,Hadoop允许用户针对map task的输出指定一个合并函数。即为了减少传输到Reduce中的数据量。它主要是为了削减Mapper的输出从而减少网络带宽和Reducer之上的负载。
数据格式转换:
map: (K1, V1) → list(K2,V2)
combine: (K2, list(V2)) → list(K3, V3)
reduce: (K3, list(V3)) → list(K4, V4)
注意:combine的输入和reduce的完全一致,输出和map的完全一致
使用注意:
对于Combiner有几点需要说明的是:
1)有很多人认为这个combiner和map输出的数据合并是一个过程,其实不然,map输出的数据合并只会产生在有数据spill出的时候,即进行merge操作。
2)与mapper与reducer不同的是,combiner没有默认的实现,需要显式的设置在conf中才有作用。
3)并不是所有的job都适用combiner,只有操作满足结合律的才可设置combiner。combine操作类似于:opt(opt(1, 2, 3), opt(4, 5, 6))。如果opt为求和、求最大值的话,可以使用,但是如果是求中值的话,不适用。
4)一般来说,combiner和reducer它们俩进行同样的操作。
但是:特别值得注意的一点,一个combiner只是处理一个结点中的的输出,而不能享受像reduce一样的输入(经过了shuffle阶段的数据),这点非常关键。具体原因查看下面的数据流解释:
融合combiner的数据流
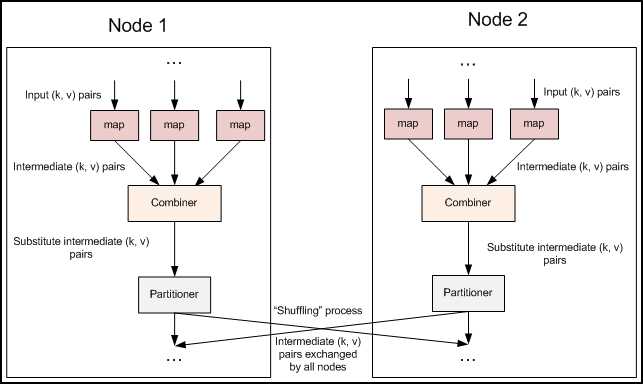
插入了Combiner的MapReduce数据流
Combiner:前面展示的流水线忽略了一个可以优化MapReduce作业所使用带宽的步骤,这个过程叫Combiner,它在Mapper之后Reducer之前运行。Combiner是可选的,如果这个过程适合于你的作业,Combiner实例会在每一个运行map任务的节点上运行。Combiner会接收特定节点上的Mapper实例的输出作为输入,接着Combiner的输出会被发送到Reducer那里,而不是发送Mapper的输出。Combiner是一个“迷你reduce”过程,它只处理单台机器生成的数据(特别重要,作者在做一个矩阵乘法的时候,没有领会到这点,把它当成一个完全的reduce的输入数据来处理,结果出错。)。
词频统计是一个可以展示Combiner的用处的基础例子,上面的词频统计程序为每一个它看到的词生成了一个(word,1)键值对。所以如果在同一个文档内“cat”出现了3次,(”cat”,1)键值对会被生成3次,这些键值对会被送到Reducer那里。通过使用Combiner,这些键值对可以被压缩为一个送往Reducer的键值对(”cat”,3)。现在每一个节点针对每一个词只会发送一个值到reducer,大大减少了shuffle过程所需要的带宽并加速了作业的执行。这里面最爽的就是我们不用写任何额外的代码就可以享用此功能!如果你的reduce是可交换及可组合的,那么它也就可以作为一个Combiner。你只要在driver中添加下面这行代码就可以在词频统计程序中启用Combiner。
参考资料:
http://blog.csdn.net/guoery/article/details/8529004
http://blog.csdn.net/guoery/article/details/8529004
【Hadoop】Combiner的本质是迷你的reducer,不能随意使用
标签:map 出错 程序 作者 cer 功能 问题 cat blog
原文地址:http://www.cnblogs.com/junneyang/p/7685839.html