标签:登陆 创建 country enc rom term div 数据 路径
1:Hive创建数据表:
CREATE TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT ‘IP Address of the User‘) COMMENT ‘This is the page view table‘ PARTITIONED BY(dt STRING, country STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ STORED AS SEQUENCEFILE;
创建数据表解释如下所示:
# page_view是数据表的名称,注意hive的数据类型和java的数据类型类似,和mysql和oracle等数据库的字段类型不一致。 CREATE TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT ‘IP Address of the User‘) #COMMENT描述,可有可无的。 COMMENT ‘This is the page view table‘ # PARTITIONED BY指定表的分区,可以先不管。 PARTITIONED BY(dt STRING, country STRING) # ROW FORMAT DELIMITED代表一行是一条记录,是自己创建的全部字段和文件的字段对应,一行对应一条记录。 ROW FORMAT DELIMITED #FIELDS TERMINATED BY ‘\001‘代表一行记录中的各个字段以什么隔开,方便创建的数据字段对应文件的一条记录的字段。 FIELDS TERMINATED BY ‘\001‘ # STORED AS SEQUENCEFILE;代表对应的文件类型。最常见的是SEQUENCEFILE(以键值对类型格式存储的)类型。TEXTFILE类型。 STORED AS SEQUENCEFILE;
创建如下所示,之前创建的不符合规范,删除了,然后创建一个标准的,查看一下,最后一个指定类型的,可以不指定,默认就是普通的文本类型的:
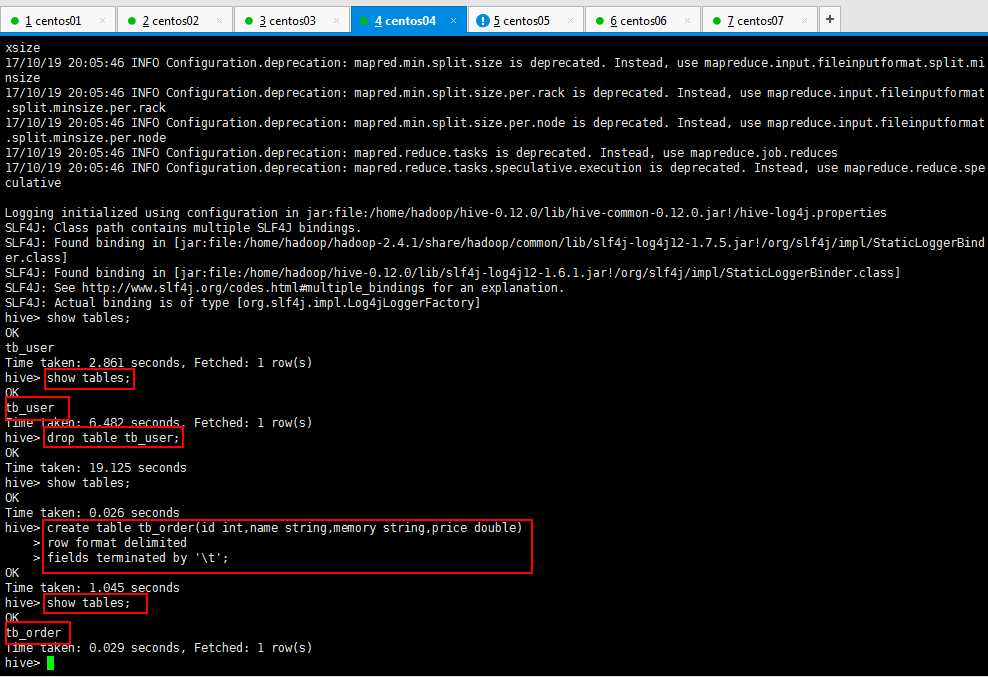
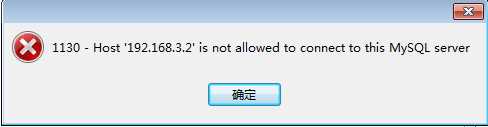
Hive将创建的数据类型写到元数据库,可以使用本地Navicat连接虚拟机的mysql查看数据;可是呢,出现下面的情况,百度呗,解决方法一大推,我贴一下子的解决方法:
错误(贴出来,方便被搜索到,哈哈哈哈。):1130 -Host ‘192.168.3.132‘ is not allowed to connect to this MySQL server
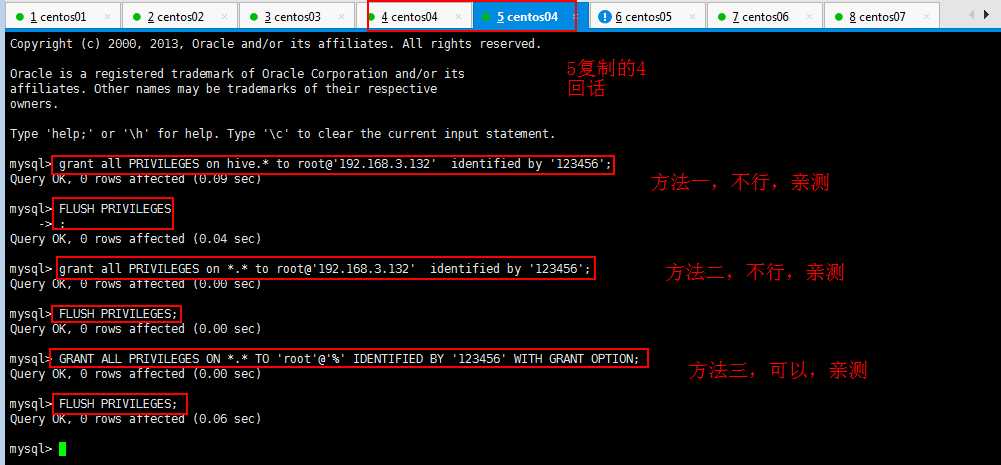
百度方法很多,但是不是每一个都适合你,我就百度了很多没解决我的问题,所以我还是贴一下我的解决方法:
如何开启MySQL的远程帐号(Navicat远程连接自己的mysql数据库):
mysql> GRANT ALL PRIVILEGES ON *.* TO ‘root‘@‘%‘ IDENTIFIED BY ‘123456‘ WITH GRANT OPTION;
再执行下面的语句,方可立即生效(修改的权限即时生效)。
mysql> FLUSH PRIVILEGES;
上面的语句表示将 所有的 数据库的所有权限授权给 root 这个用户,允许 root 用户在 192.168.3.132 这个 IP 进行远程登陆,并设置 root 用户的密码为 123456 。
下面逐一分析所有的参数:
(1)all PRIVILEGES 表示赋予所有的权限给指定用户,这里也可以替换为赋予某一具体的权限,例如select,insert,update,delete,create,drop 等,具体权限间用“,”半角逗号分隔。
(2)*.* 表示上面的权限是针对于哪个表的,*指的是所有数据库,后面的 * 表示对于所有的表,由此可以推理出:对于全部数据库的全部表授权为“*.*”,对于某一数据库的全部表授权为“数据库名.*”,对于某一数据库的某一表授权为“数据库名.表名”。
(3)root 表示你要给哪个用户授权,这个用户可以是存在的用户,也可以是不存在的用户。
(4)192.168.3.132 表示允许远程连接的 IP 地址,如果想不限制链接的 IP 则设置为“%”即可。
(5)123456 为用户的密码。
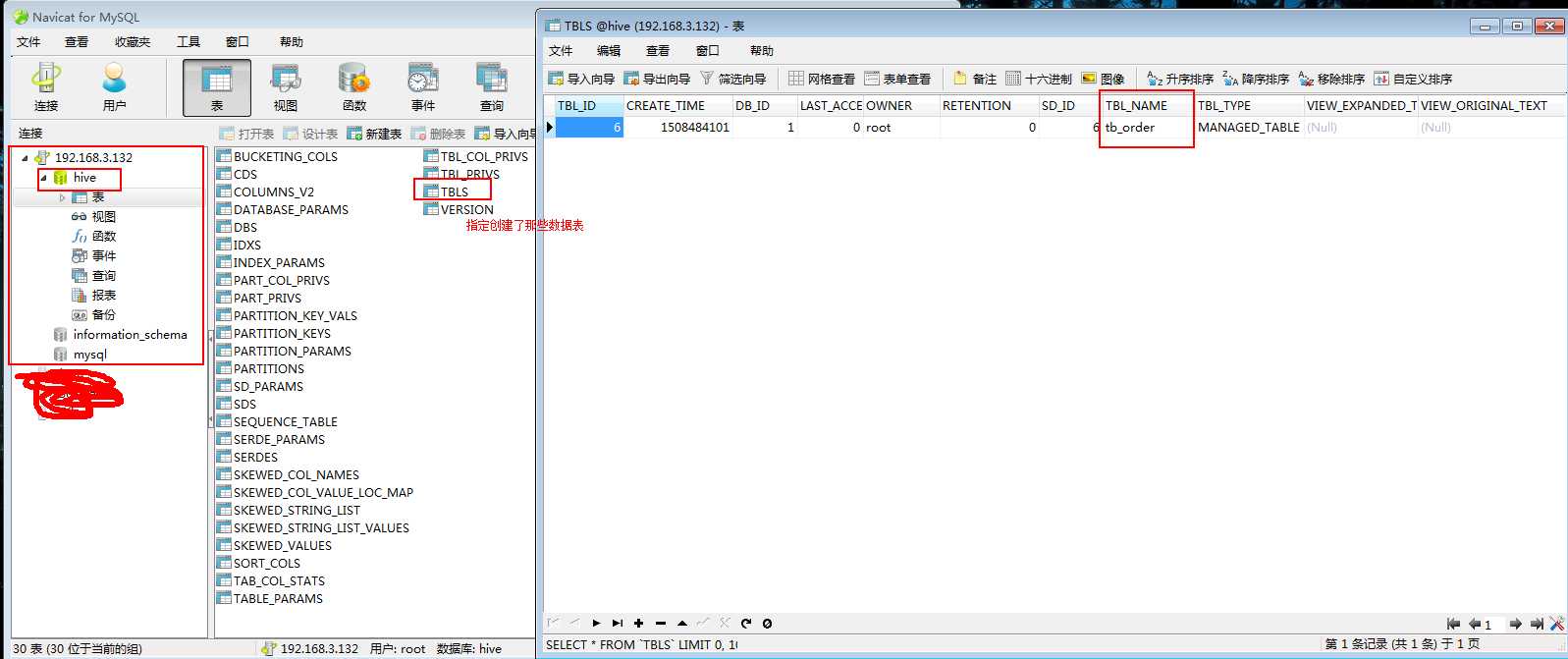
可以使用Navicat工具查看一下自己的创建的数据表(tabs是保存了创建了那些表名):
可以看看自己创建了那些列(在COLUMNS_V2数据表里面):
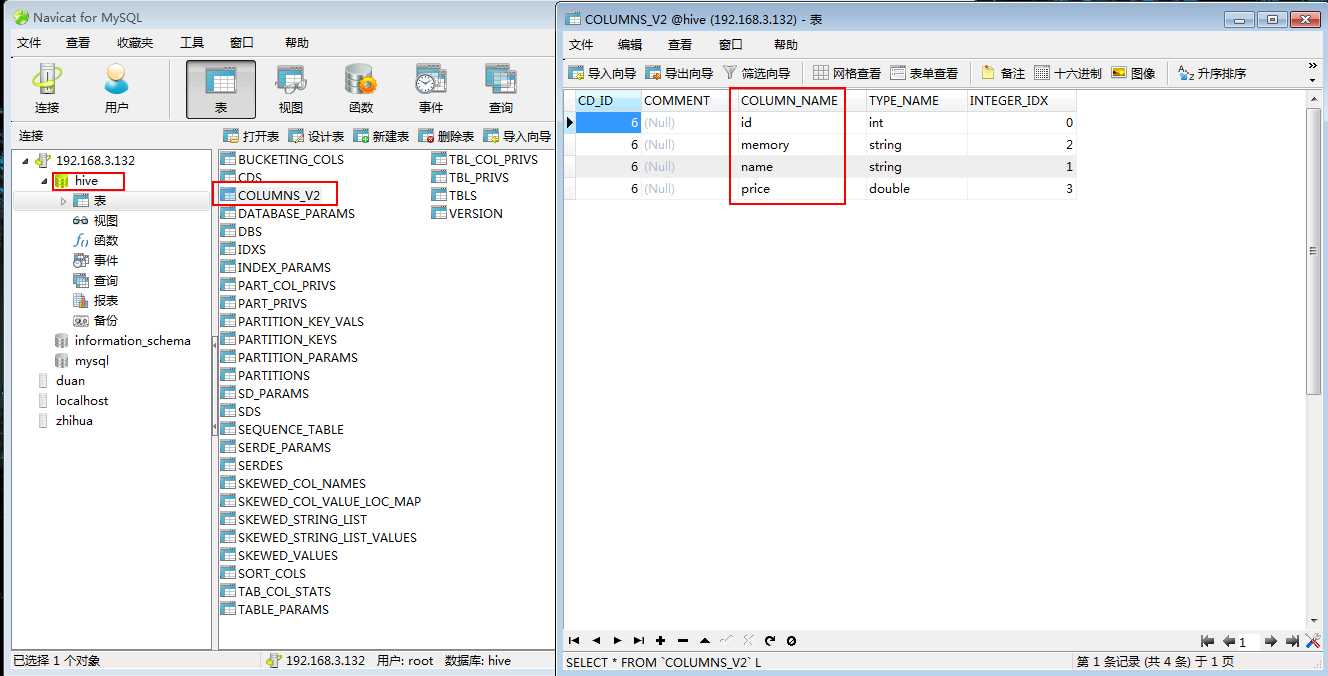
可以看到有DBS里面保存了哪些数据库:
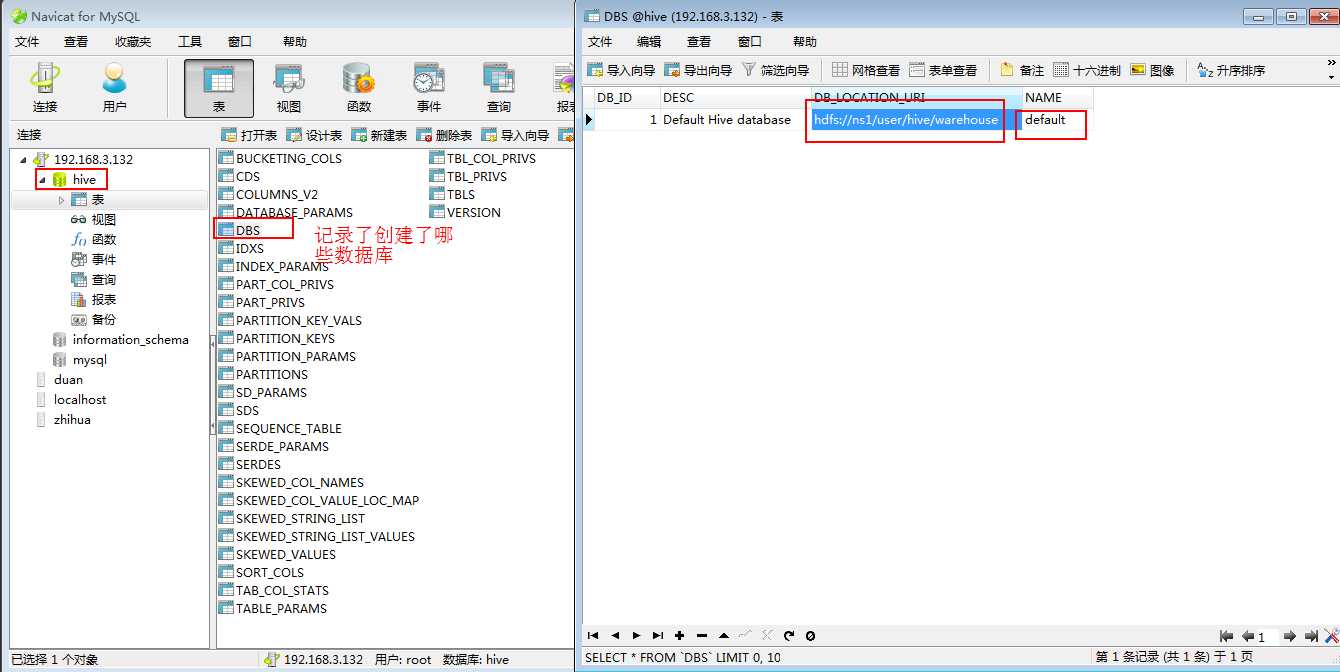
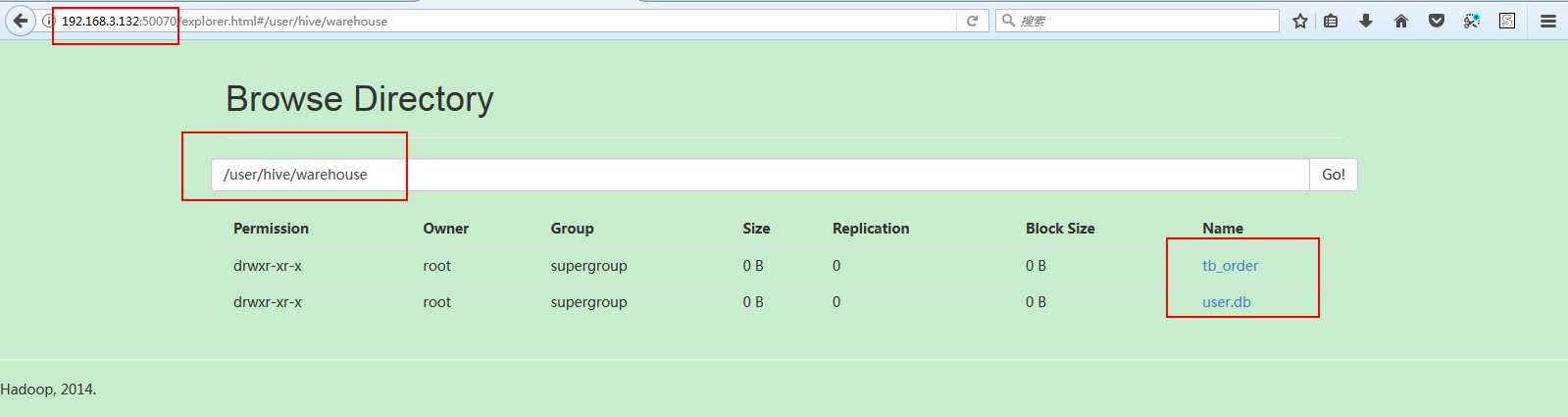
DBS数据表的DB_LOCATION_URI字段保存了路径:hdfs://ns1/user/hive/warehouse
可以去hdfs里看一眼,里面确实保存着数据库(突然发现有点意思了,只可意会,言传不了了,哈哈哈哈~~~~):
2:创建好数据表,了解了一些基本知识以后,开始插入数据,了解更多的知识:
//create & load(创建好数据表以后导入数据的操作如):
hive> create table tb_order(id int,name string,memory string,price double)
> row format delimited
> fields terminated by ‘\t‘;
//从本地导入数据到hive的表中(实质就是将文件上传到hdfs中hive管理目录下)
load data local inpath ‘/home/hadoop/ip.txt‘ into table 要导入的表名称;
//从hdfs上导入数据到hive表中(实质就是将文件从原始目录移动到hive管理的目录下)
load data inpath ‘hdfs://ns1/aa/bb/data.log‘ into table 要导入的表名称;
//使用select语句来批量插入数据
insert overwrite table tab_ip_seq select * from 要导入的表名称;
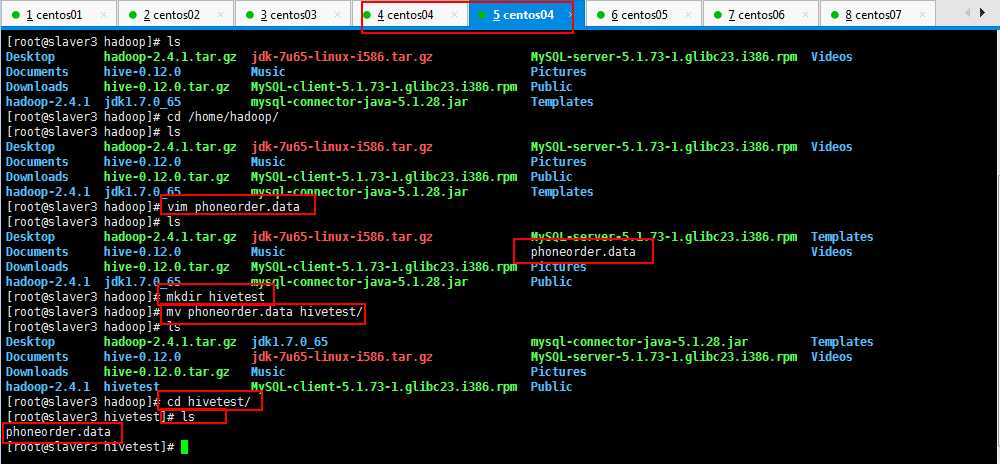
自己造一组数据,保存一下,如我的,在/home/hadoop/目录下面phoneorder.data,内容如下所示:
[root@slaver3 hadoop]# vim phoneorder.data
想了一下,由于学习hive,会有很多测试数据,自己创建一个hivetest目录,专一用于存放hive测试数据,如下所示:
10010 小米1 2G 1999 10011 小米2 4G 1999 10012 小米3 4G 1999 10013 小米4 6G 2999 10014 小米5 6G 2999 10015 小米6 8G 2999 10016 小米7 8G 3999
然后开始导入数据(或者使用hadoop的命令将正确格式数据上传到对应的目录),如下所示:
hive> load data local inpath ‘/home/hadoop/hivetest/phoneorder.data‘ into table tb_order;
或者[root@slaver3 hivetest]# hadoop fs -put phoneorder2.data /user/hive/warehouse/tb_order
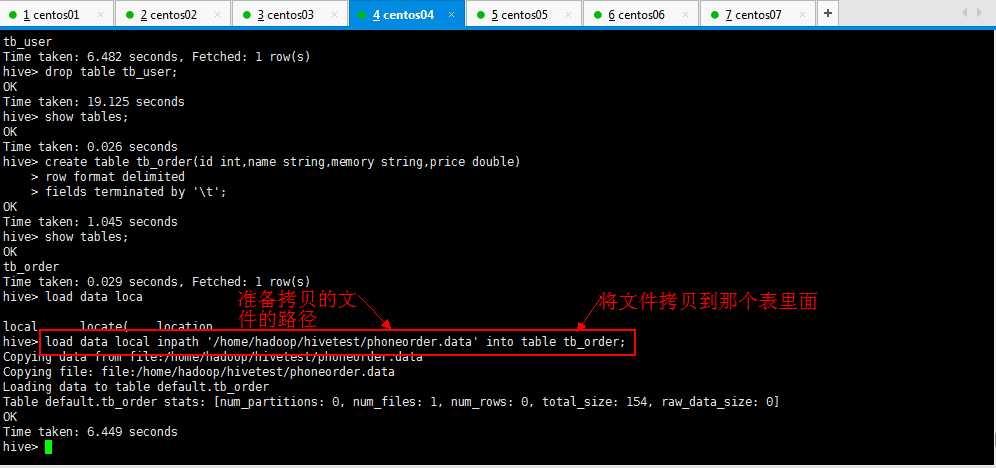
可以去hdfs看到数据已经上传成功了,如下所示,可以看到一些简单信息:
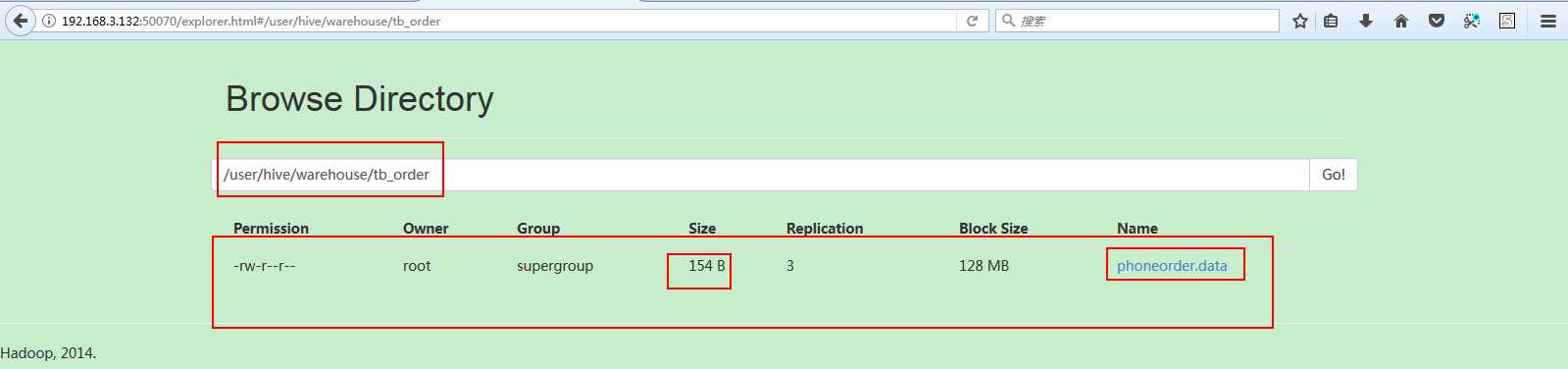
下面可以使用hive的查询语句进行查询操作;
3:Hive的查询语句进行查询操作,统计多少条记录的时候发现很慢很慢,那是启动集群的时候就很慢,最后可以看到一共7条记录,用了一百多秒:
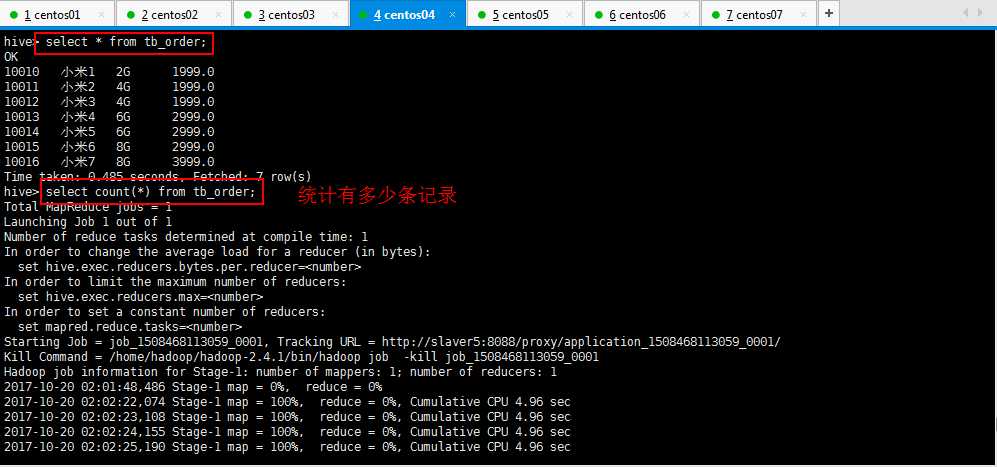
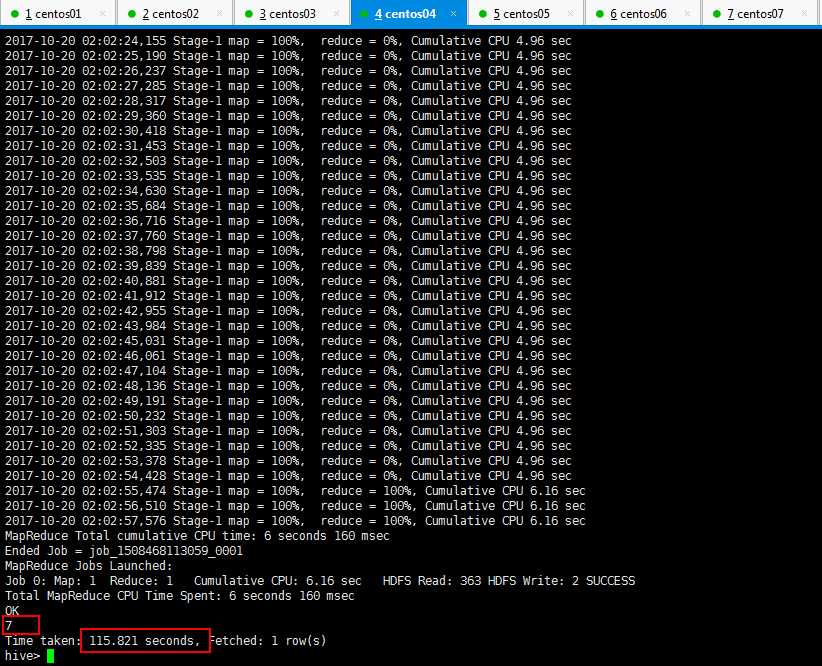
4:external外部表,优点,做数据分析的时候,有的数据是业务系统产生的,或者读或者写这个文件,如果的默认的路径,即在配置文件里面写好了,如果做分析的时候数据表导数据,如果将数据表移动了,,业务系统再读这个文件就不存在了,这个时候使用外部表,外部表不要求数据非到默认的路径下面去,数据可以摆放到任意的hdfs路径下面;
创建外部表的语法:
//external外部表 CREATE EXTERNAL TABLE tab_ip_ext(id int, name string, ip STRING, country STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘ STORED AS TEXTFILE LOCATION ‘/external/user‘;
//external外部表 //使用关键字EXTERNAL CREATE EXTERNAL TABLE 数据表名称(id int, name string, ip STRING, country STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ STORED AS TEXTFILE #location指定所在的位置:切记,重点。 LOCATION ‘/external/user‘;
标签:登陆 创建 country enc rom term div 数据 路径
原文地址:http://www.cnblogs.com/biehongli/p/7699578.html