标签:style blog http io 使用 ar strong 数据 2014
本文是《LoadRunner没有告诉你的》系列文章的第四篇,在这篇短文中,我将尽可能用简洁清晰的文字写下我对“性能”的看法,并澄清几个容易混淆的概念,帮助大家更好的理解“性能”的含义。
如何评价性能的优劣: 用户视角 vs. 系统视角
对于最终用户(End-User)来说,评价系统的性能好坏只有一个字——“快”。最终用户并不需要关心系统当前的状态——即使系统这时正在处理着成千上万的请求,对于用户来说,由他所发出的这个请求是他唯一需要关心的,系统对用户请求的响应速度决定了用户对系统性能的评价。
而对于系统的运营商和开发商来说,期望的是能够让尽可能多的用户在任意时刻都拥有最好的体验,这就要确保系统能够在同一时间内处理更多的用户请求。正如在《理发店模型》一文中所描述的:系统的负载(并发用户数)与吞吐量(每秒事务数)、响应时间以及资源利用率(包括软硬件资源)之间存在着一个“此消彼长”的关系。因此,从系统的运营商和开发商的角度来看,所谓的“性能”是一个整体的概念,是系统的负载与吞吐量、可接受的响应时间以及资源利用率之间的平衡。
换句话说,“好的性能”意味着更大的最佳并发用户数(The Optimum Number of Concurrent Users)和 最大并发用户数(The Maximum Number of Concurrent Users)。有关“最佳/最大并发用户数”的概念请参见《理发店模型》一文。
另外,从系统的视角来看,所需要关注的还包括三个与“性能”有关的属性:可靠性(Reliability),可伸缩性(Scalability)和 可恢复性(Recoverability)——我将会在本系列文章的第五篇“无处不在的性能测试”中专门讨论这三个属性的含义和相关的实践经验。
响应时间
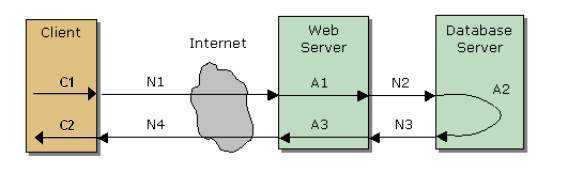
上面这张图引自段念兄的一份讲义,不过我略作了些修改。从图中我们可以清楚的看到一个请求的响应时间是由几部分时间组成的,包括
C1:用户请求发出前在客户端需要完成的预处理所需要的时间;
C2:客户端收到服务器返回的响应后,对数据进行处理并呈现所需要的时间;
A1:Web/App Server 对请求进行处理所需要的时间;
A2:DB Server 对请求进行处理所需的时间;
A3:Web/App Server 对 DB Server 返回的结果进行处理所需的时间;
N1:请求由客户端发出并达到Web/App Server 所需要的时间;
N2:如果需要进行数据库相关的操作,由Web/App Server 将请求发送至DB Server 所需要的时间;
N3:DB Server 完成处理并将结果返回Web/App Server 所需的时间;
N4:Web/App Server 完成处理并将结果返回给客户端所需的时间;
从用户的角度来看,响应时间=(C1+C2)+(A1+A2+A3)+(N1+N2+N3+N4);但是从系统的角度来看,响应时间只包括(A1+A2+A3)+(N1+N2+N3+N4)。
在理解了响应时间的组成之后,可以帮助我们通过对响应时间的分析来更好的识别和定位系统的性能瓶颈。
吞吐量 vs. 吞吐量
在不同的测试工具中,对于吞吐量(Throughput)会有不同的解释。例如,在LoadRunner中,这个指标是以字节数为单位来衡量网络吞吐量的,而在JMeter中则是以事务数/秒为单位来衡量系统的响应能力的。不过在大多数英文的性能测试方面的书籍或资料中,吞吐量的定义使用的是后者。
并发用户数 ≠ 每秒请求数
这是两个容易让初学者混淆的概念。
简单说,当你在性能测试工具或者脚本中设置了100并发用户数后,并不能期望着一定会有每秒100个请求发给服务器。事实上,对于一个虚拟用户来说,每秒发出多少请求只跟服务器返回响应的速度有关。如果虚拟用户在0.5秒内就收到了响应,那么它会立即发出第二个请求;而如果要一直等待3秒才能得到响应,它将会一直等到收到响应后才发出第二个请求。也就是说,并发用户数的设置只是保证服务器在任一时刻都有100个请求需要处理,而并不一定是保证每秒中发送100个请求给服务器。
所以,只有当响应时间恰好是1秒时,并发用户数才会等于每秒请求数;否则,每秒请求数可能大于并发用户数或小于并发用户数。
标签:style blog http io 使用 ar strong 数据 2014
原文地址:http://www.cnblogs.com/hcat/p/3967378.html