标签:www. 分配 ble region rowid 设计 body 个数 约束
HBase是建立在Hadoop文件系统之上的分布式面向列的数据库。它是一个开源项目,是横向扩展的。
HBase是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数据。它利用了Hadoop的文件系统(HDFS)提供的容错能力。
它是Hadoop的生态系统,提供对数据的随机实时读/写访问,是Hadoop文件系统的一部分。
人们可以直接或通过HBase的存储HDFS数据。使用HBase在HDFS读取消费/随机访问数据。 HBase在Hadoop的文件系统之上,并提供了读写访问。
| HDFS | HBase |
|---|---|
| HDFS是适于存储大容量文件的分布式文件系统。 | HBase是建立在HDFS之上的数据库。 |
| HDFS不支持快速单独记录查找。 | HBase提供在较大的表快速查找 |
| 它提供了高延迟批量处理;没有批处理概念。 | 它提供了数十亿条记录低延迟访问单个行记录(随机存取)。 |
| 它提供的数据只能顺序访问。 | HBase内部使用哈希表和提供随机接入,并且其存储索引,可将在HDFS文件中的数据进行快速查找。 |
HBase是一个面向列的数据库,在表中它由行排序。表模式定义只能列族,也就是键值对。一个表有多个列族以及每一个列族可以有任意数量的列。后续列的值连续地存储在磁盘上。表中的每个单元格值都具有时间戳。总之,在一个HBase:
下面给出的表中是HBase模式的一个例子。
| Rowide | Column Family | Column Family | Column Family | Column Family | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
面向列的数据库是存储数据表作为数据列的部分,而不是作为行数据。总之它们拥有列族。
| 行式数据库 | 列式数据库 |
|---|---|
| 它适用于联机事务处理(OLTP)。 | 它适用于在线分析处理(OLAP)。 |
| 这样的数据库被设计为小数目的行和列。 | 面向列的数据库设计的巨大表。 |
下图显示了列族在面向列的数据库:

| HBase | RDBMS |
|---|---|
| HBase无模式,它不具有固定列模式的概念;仅定义列族。 | RDBMS有它的模式,描述表的整体结构的约束。 |
| 它专门创建为宽表。 HBase是横向扩展。 | 这些都是细而专为小表。很难形成规模。 |
| 没有任何事务存在于HBase。 | RDBMS是事务性的。 |
| 它反规范化的数据。 | 它具有规范化的数据。 |
| 它用于半结构以及结构化数据是非常好的。 | 用于结构化数据非常好。 |
在HBase中,表被分割成区域,并由区域服务器提供服务。区域被列族垂直分为“Stores”。Stores被保存在HDFS文件。下面显示的是HBase的结构。
注意:术语“store”是用于区域来解释存储结构。
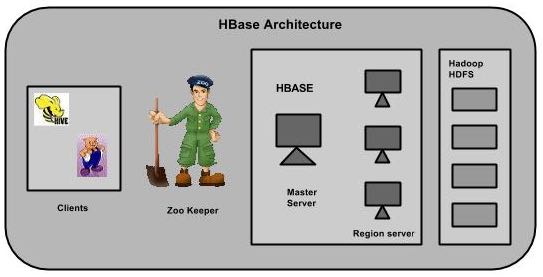
HBase有三个主要组成部分:客户端库,主服务器和区域服务器。区域服务器可以按要求添加或删除。
主服务器是 -
区域只不过是表被拆分,并分布在区域服务器。
区域服务器拥有区域如下 -
需要深入探讨区域服务器:包含区域和存储,如下图所示:
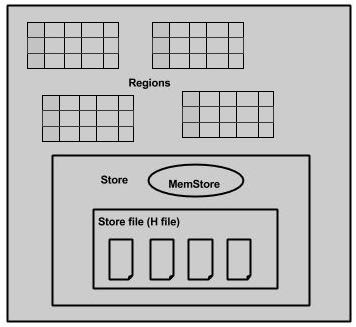
存储包含内存存储和HFiles。memstore就像一个高速缓存。在这里开始进入了HBase存储。数据被传送并保存在Hfiles作为块并且memstore刷新。
标签:www. 分配 ble region rowid 设计 body 个数 约束
原文地址:http://www.cnblogs.com/xinfang520/p/7716886.html