标签:提升 lis 位置 例子 总结 数据结构 blog png 优势
考虑一个有序表:14->23->34->43->50->59->66->72
从该有序表中搜索元素 < 23, 43, 59 > ,需要比较的次数分别为 < 2, 4, 6 >,总共比较的次数
为 2 + 4 + 6 = 12 次。有没有优化的算法吗? 链表是有序的,但不能使用二分查找。类似二叉
搜索树,我们把一些节点提取出来,作为索引。
这里我们把 < 14, 34, 50, 72 > 提取出来作为一级索引,这样搜索的时候就可以减少比较次数了。
我们还可以再从一级索引提取一些元素出来,作为二级索引,变成如下结构:
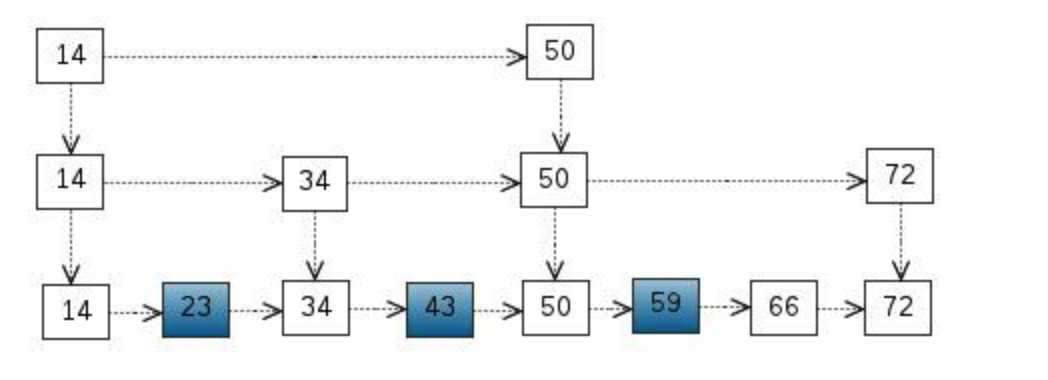
如果元素足够多,这种索引结构就能体现出优势来了。
跳表具有如下性质:
(1) 由很多层结构组成
(2) 每一层都是一个有序的链表
(3) 最底层(Level 1)的链表包含所有元素
(4) 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
其中 -1 表示 INT_MIN, 链表的最小值,1 表示 INT_MAX,链表的最大值。
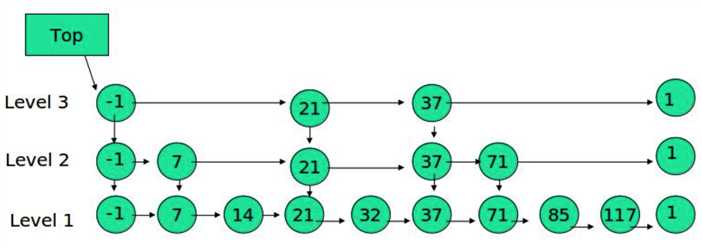
例子:查找元素 117
(1) 比较 21, 比 21 大,往后面找
(2) 比较 37, 比 37大,比链表最大值小,从 37 的下面一层开始找
(3) 比较 71, 比 71 大,比链表最大值小,从 71 的下面一层开始找
(4) 比较 85, 比 85 大,从后面找
(5) 比较 117, 等于 117, 找到了节点。
新节点和各层索引节点逐一比较,确定原链表的插入位置。O(logN)
把索引插入到原链表。O(1)
利用抛硬币的随机方式,决定新节点是否提升为上一级索引。结果为“正”则提升并继续抛硬币,结果为“负”则停止。O(logN)
总体上,跳跃表插入操作的时间复杂度是O(logN),而这种数据结构所占空间是2N,既空间复杂度是 O(N)。
自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。O(logN)
删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。O(logN)
总体上,跳跃表删除操作的时间复杂度是O(logN)。
跳跃表的优点在维持结构平衡的成本比较的,根据扔硬币,所以完全依靠随机。而二叉查找树在多次插入删除后,需要Rebalance来重新调整结构平衡。
标签:提升 lis 位置 例子 总结 数据结构 blog png 优势
原文地址:http://www.cnblogs.com/wade-luffy/p/7728542.html