标签:toolbar 说明 sum mit 返回 commit type 分组函数 显示
group by 后使用 rollup 子句总结
一、如何理解group by 后带 rollup 子句所产生的效果
group by 后带 rollup 子句的功能可以理解为:先按一定的规则产生多种分组,然后按各种分组统计数据(至于统计出的数据是求和还是最大值还是平均值等这就取决于SELECT后的聚合函数)。因此要搞懂group by 后带 rollup 子句的用法主要是搞懂它是如何按一定的规则产生多种分组的。另group by 后带 rollup 子句所返回的结果集,可以理解为各个分组所产生的结果集的并集且没有去掉重复数据。下面举例说明:
1、 对比没有带rollup 的goup by
例:Group by A ,B
产生的分组种数:1种;
即group by A,B
返回结果集:也就是这一种分组的结果集。
2、 带rollup 但 group by 与 rollup 之间没有任何内容
例1:Group by rollup(A ,B)
产生的分组种数:3 种;
第一种:group by A,B
第二种:group by A
第三种:group by NULL
(说明:本没有group by NULL 的写法,在这里指是为了方便说明,而采用之。含义是:没有分组,也就是所有数据做一个统计。例如聚合函数是SUM的话,那就是对所有满足条件的数据进行求和。此写法的含义下同)
返回结果集:为以上三种分组统计结果集的并集且未去掉重复数据。
例2:Group by rollup(A ,B,C)
产生的分组种数:4 种;
第一种:group by A,B,C
第二种:group by A,B
第三种:group by A
第四种:group by NULL
返回结果集:为以上四种分组统计结果集的并集且未去掉重复数据。
3、 带rollup 但 group by 与 rollup 之间还包含有列信息
例1:Group by A , rollup(A ,B)
产生的分组种数:3 种;
第一种:group by A,A,B 等价于 group by A,B
第二种:group by A,A 等价于 group by A
第三种:group by A,NULL 等价于 group by A
返回结果集:为以上三种分组统计结果集的并集且未去掉重复数据。
例2:Group by C , rollup(A ,B)
产生的分组种数:3 种;
第一种:group by C,A,B
第二种:group by C,A
第三种:group by C,NULL 等价于 group by C
返回结果集:为以上三种分组统计结果集的并集且未去掉重复数据。
4、 带rollup 且rollup子句括号内又使用括号对列进行组合
例1:Group by rollup((A ,B))
产生的分组种数:2 种;
第一种:group by A,B
第二种:group by NULL
返回结果集:为以上两种分组统计结果集的并集且未去掉重复数据。
例2:Group by rollup(A ,(B,C))
产生的分组种数:3 种;
第一种:group by A,B,C
第二种:group by A
第三种:group by NULL
返回结果集:为以上三种分组统计结果集的并集且未去掉重复数据。
注:对这种情况,可以理解为几个列被括号括在一起时,就只能被看成一个整体,分组时不需要再细化。因此也可推断rollup括号内也顶多加到一重括号,加多重了应该没有任何意义(这个推断我没有做验证的哦)。
二、与rollup组合使用的其它几个辅助函数
1、grouping()函数
必须接受一列且只能接受一列做为其参数。参数列值为空返回1,参数列值非空返回0。
2、grouping_id()函数
必须接受一列或多列做为其参数。
返回值为按参数排列顺序,依次对各个参数使用grouping()函数,并将结果值依次串成一串二进制数然后再转化为十进制所得到的值。
例如:grouping(A) = 0 ; grouping(B) = 1;
则:grouping_id(A,B) = (01)2 = 1;
grouping_id(B,A) = (10)2 =2;
3、group_id()函数
调用时不需要且不能传入任何参数。
返回值为某个特定的分组出现的重复次数(第一大点中的第3种情况中往往会产生重复的分组)。重复次数从0开始,例如某个分组第一次出现则返回值为0,第二次出现时返回值为1,……,第n次出现返回值为n-1。
注:使用以上三个函数往往是为了过滤掉一部分统计数据,而达到美化统计结果的作用。
三、group by 后带rollup子句与 group by 后带cube子句区别
group by 后带rollup子句与 group by 后带cube子句的唯一区别就是:
带cube子句的group by 会产生更多的分组统计数据。cube后的列有多少种组合(注意组合是与顺序无关的)就会有多少种分组。
例:Group by cube(A ,B,C)
产生的分组种数:8 种;
第一种:group by A,B,C
第二种:group by A,B
第三种:group by A,C
第四种:group by B,C
第五种:group by C
第六种:group by B
第七种:group by A
第八种:group by NULL
返回结果集:为以上八种分组统计结果集的并集且未去掉重复数据。
四、group by 后带grouping sets子句
group by 后带grouping sets子句效果就是只返回小记记录,即只返回按单个列分组后的统计数据,不返回多个列组合分组的统计数据。
例1:Group by grouping sets(A )
产生的分组种数:1 种;
第一种:group by A
返回结果集:即为以上一种分组的统计结果集。
例2:Group by grouping sets(A ,B)
产生的分组种数:2 种;
第一种:group by A
第二种:group by B
返回结果集:为以上两种分组统计结果集的并集且未去掉重复数据。
例3:Group by grouping sets (A ,B,C)
产生的分组种数:3 种;
第一种:group by A
第二种:group by B
第三种:group by C
返回结果集:为以上三种分组统计结果集的并集且未去掉重复数据。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
转载:http://www.cnblogs.com/fangyz/p/5813916.html
2.grouping( )
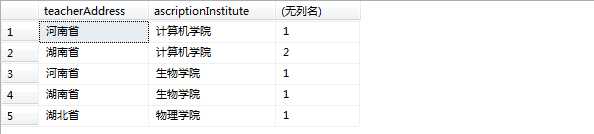
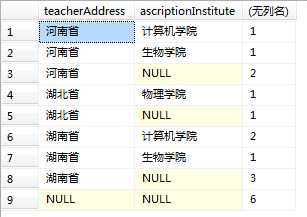
grouping函数用来区分NULL值,这里NULL值有2种情况,一是原本表中的数据就为NULL,二是由rollup、cube、grouping sets生成的NULL值。
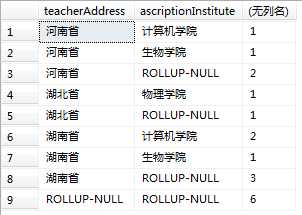
当为第一种情况中的空值时,grouping(NULL)返回0;当为第二种情况中的空值时,grouping(NULL)返回1。实例如下,从结果中可以看到第二个结果集中原本为null的数据由于grouping函数为1,故显示ROLLUP-NULL字符串。

select teacherAddress,ascriptionInstitute,COUNT(teacherId ) from teacher group by teacherAddress,ascriptionInstitute
select teacherAddress,ascriptionInstitute,COUNT(teacherId ) from teacher group by rollup(teacherAddress,ascriptionInstitute)
select ISNULL(teacherAddress,case when GROUPING(teacherAddress)=1 then ‘ROLLUP-NULL‘ end) as teacherAddress,
ISNULL(ascriptionInstitute,case when GROUPING(ascriptionInstitute)=1 then ‘ROLLUP-NULL‘ end) as ascriptionInstitute,
COUNT(teacherId )
from teacher group by rollup(teacherAddress,ascriptionInstitute)
标签:toolbar 说明 sum mit 返回 commit type 分组函数 显示
原文地址:http://www.cnblogs.com/jingRegina/p/7730028.html