标签:reads edr emc 结果 sizeof 分享 nbsp 提升 red
使用 clock() 函数在CUDA核函数内部进行计时。
源代码:
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <time.h> 4 #include "cuda_runtime.h" 5 #include "device_launch_parameters.h" 6 #include <helper_cuda.h> 7 #include <helper_functions.h> 8 9 __global__ static void timedReduction(const float *input, float *output, clock_t *timer) 10 { 11 extern __shared__ float shared[];// 共享内存数组大小为 blockDim.x 的2倍 12 13 const int tid = threadIdx.x; 14 const int bid = blockIdx.x; 15 16 if (tid == 0) timer[bid] = clock();// 零号线程负责计时,所有线程块都做一模一样的规约工作 17 18 shared[tid] = input[tid]; 19 shared[tid + blockDim.x] = input[tid + blockDim.x]; 20 21 // 二分规约求最小值 22 for (int d = blockDim.x; d > 0; d /= 2) 23 { 24 __syncthreads(); 25 26 if (tid < d) 27 { 28 float f0 = shared[tid]; 29 float f1 = shared[tid + d]; 30 if (f1 < f0) 31 shared[tid] = f1; 32 } 33 } 34 35 if (tid == 0) output[bid] = shared[0]; 36 __syncthreads(); 37 38 if (tid == 0) timer[bid + gridDim.x] = clock(); 39 } 40 41 #define NUM_BLOCKS 1 42 #define NUM_THREADS 1024 43 44 int main(int argc, char **argv) 45 { 46 printf("CUDA Clock sample\n"); 47 48 int dev = findCudaDevice(argc, (const char **)argv); 49 50 float *dinput = NULL; 51 float *doutput = NULL; 52 clock_t *dtimer = NULL; 53 54 clock_t timer[NUM_BLOCKS * 2]; 55 float input[NUM_THREADS * 2]; 56 57 for (int i = 0; i < NUM_THREADS * 2; i++) 58 input[i] = (float)i; 59 60 cudaMalloc((void **)&dinput, sizeof(float) * NUM_THREADS * 2); 61 cudaMalloc((void **)&doutput, sizeof(float) * NUM_BLOCKS); 62 cudaMalloc((void **)&dtimer, sizeof(clock_t) * NUM_BLOCKS * 2); 63 64 cudaMemcpy(dinput, input, sizeof(float) * NUM_THREADS * 2, cudaMemcpyHostToDevice); 65 66 timedReduction << <NUM_BLOCKS, NUM_THREADS, sizeof(float) * 2 * NUM_THREADS >> >(dinput, doutput, dtimer); 67 68 cudaMemcpy(timer, dtimer, sizeof(clock_t) * NUM_BLOCKS * 2, cudaMemcpyDeviceToHost); 69 70 cudaFree(dinput); 71 cudaFree(doutput); 72 cudaFree(dtimer); 73 74 long double avgElapsedClocks = 0; 75 76 for (int i = 0; i < NUM_BLOCKS; i++) 77 avgElapsedClocks += (long double)(timer[i + NUM_BLOCKS] - timer[i]); 78 79 avgElapsedClocks = avgElapsedClocks / NUM_BLOCKS; 80 printf("Average clocks/block = %Lf\n", avgElapsedClocks); 81 82 getchar(); 83 return EXIT_SUCCESS; 84 }
? 输出结果。一共有 NUM_BLOCKS 个线程块,每个线程块利用 NUM_THREADS 个线程查找其两倍长度向量中的最小值,给出平均计算时间:
CUDA Clock sample GPU Device 0: "GeForce GTX 1070" with compute capability 6.1 Average clocks/block = 44046.328125
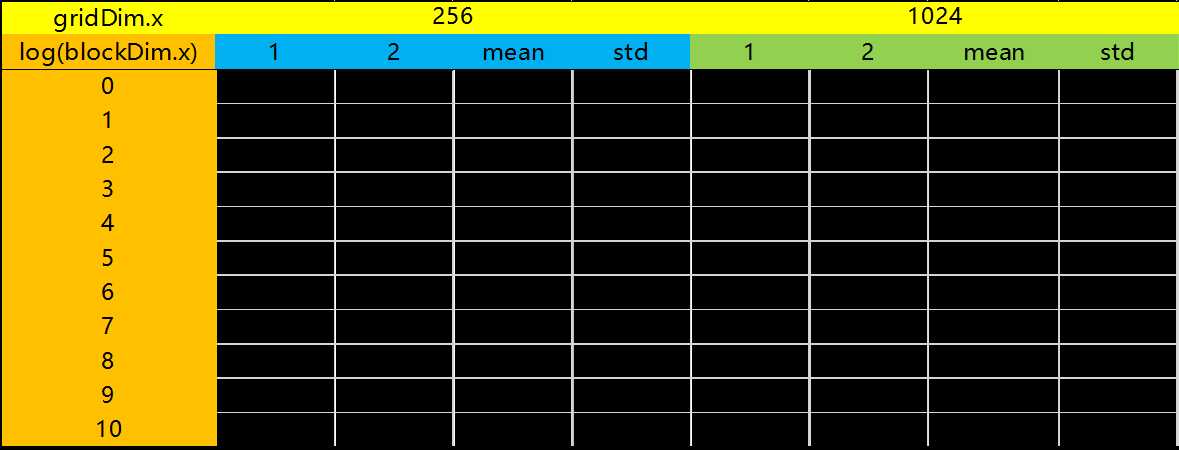
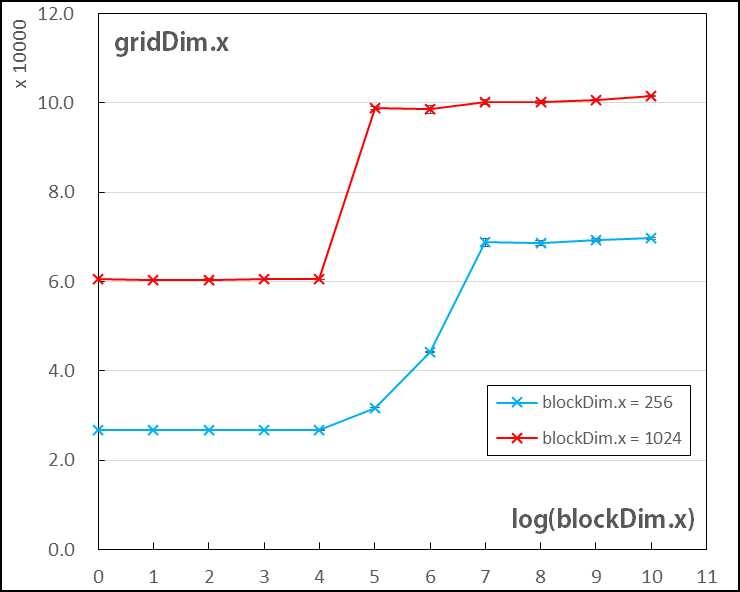
比较不同的 blockDim.x 和 threadDim.x 情况结果如下图表所示。
? 涨姿势:
● 在核函数中也能使用 <time.h>中的 clock_t 变量、clock() 函数等进行计时。
● 当使用的 block 数量少于一定的阈值时,计算效率处于较低水平。随着使用的 block 数量的上升,计算效率现有较大提升、后保持不变。
标签:reads edr emc 结果 sizeof 分享 nbsp 提升 red
原文地址:http://www.cnblogs.com/cuancuancuanhao/p/7739608.html