标签:com ima 判断 坐标 htm 文件夹 获取 src int
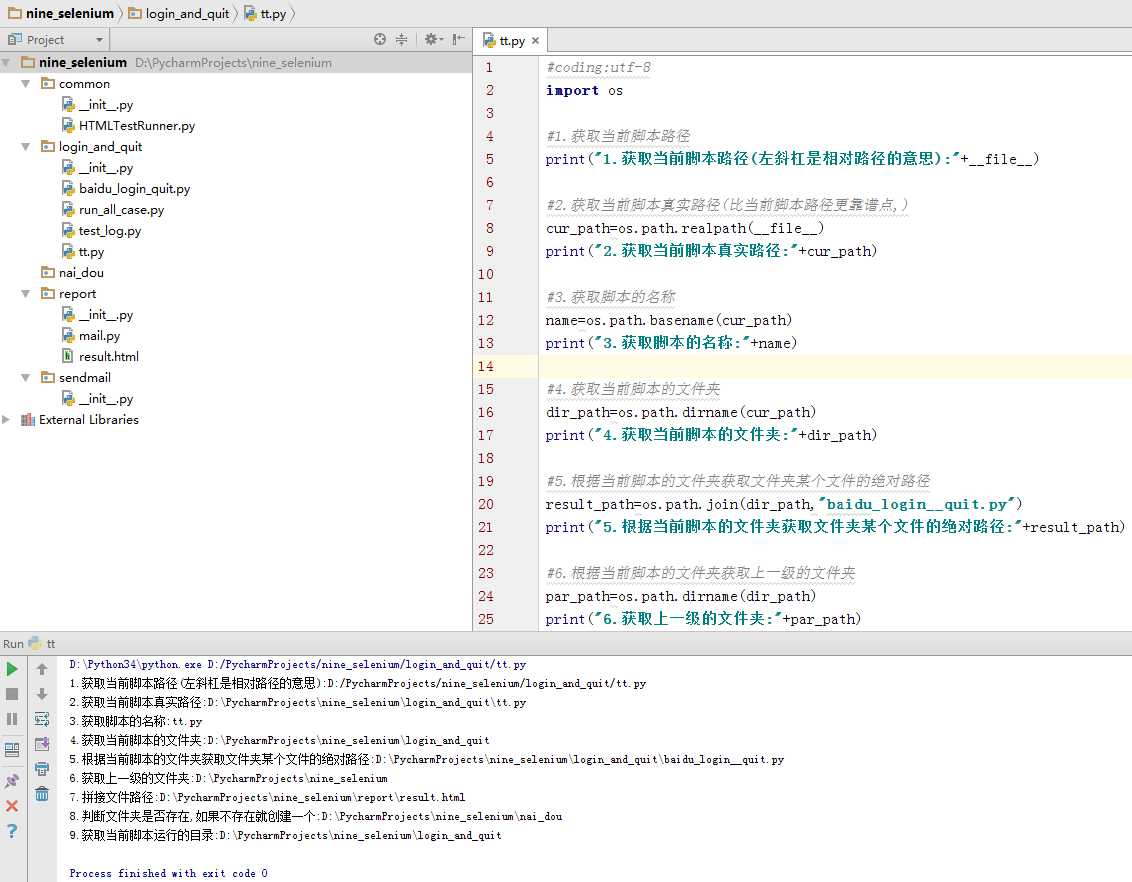
代码:
#coding:utf-8
import os
#1.获取当前脚本路径
print("1.获取当前脚本路径(左斜杠是相对路径的意思):"+__file__)
#2.获取当前脚本真实路径(比当前脚本路径更靠谱点)
cur_path=os.path.realpath(__file__)
print("2.获取当前脚本真实路径:"+cur_path)
#3.获取脚本的名称
name=os.path.basename(cur_path)
print("3.获取脚本的名称:"+name)
#4.获取当前脚本的文件夹
dir_path=os.path.dirname(cur_path)
print("4.获取当前脚本的文件夹:"+dir_path)
#5.根据当前脚本的文件夹获取文件夹某个文件的绝对路径
result_path=os.path.join(dir_path,"baidu_login__quit.py")
print("5.根据当前脚本的文件夹获取文件夹某个文件的绝对路径:"+result_path)
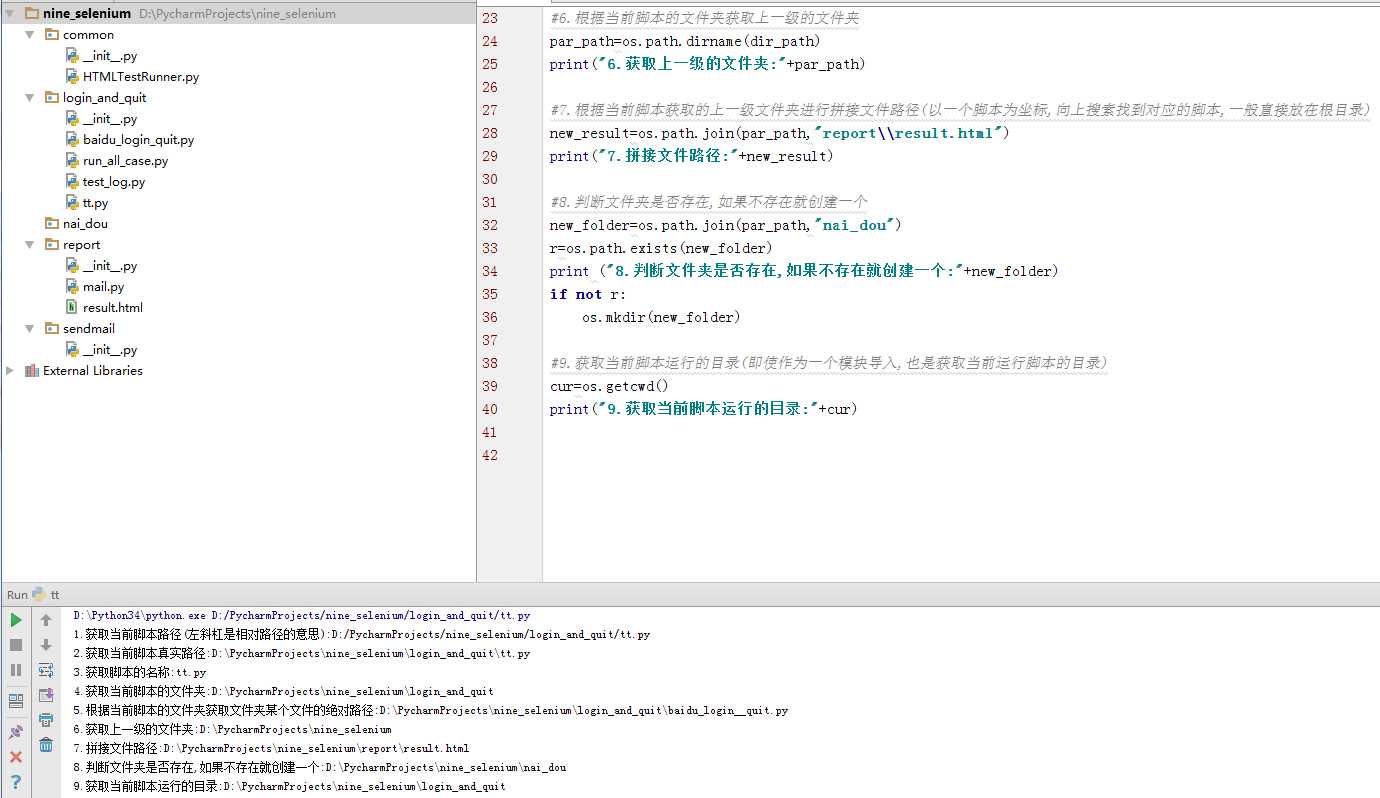
#6.根据当前脚本的文件夹获取上一级的文件夹
par_path=os.path.dirname(dir_path)
print("6.获取上一级的文件夹:"+par_path)
#7.根据当前脚本获取的上一级文件夹进行拼接文件路径(以一个脚本为坐标,向上搜索找到对应的脚本,一般直接放在根目录)
new_result=os.path.join(par_path,"report\\result.html")
print("7.拼接文件路径:"+new_result)
#8.判断文件夹是否存在,如果不存在就创建一个
new_folder=os.path.join(par_path,"nai_dou")
r=os.path.exists(new_folder)
print ("8.判断文件夹是否存在,如果不存在就创建一个:"+new_folder)
if not r:
os.mkdir(new_folder)
#9.获取当前脚本运行的目录(即使作为一个模块导入,也是获取当前运行脚本的目录)
cur=os.getcwd()
print("9.获取当前脚本运行的目录:"+cur
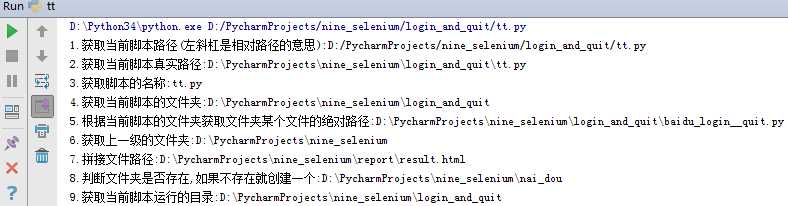
运行结果:
标签:com ima 判断 坐标 htm 文件夹 获取 src int
原文地址:http://www.cnblogs.com/linbao/p/7742340.html