标签:zip ima from .com alt art sele link img
from bs4 import BeautifulSoup import requests import time url=‘https://knewone.com/?page=5‘ def get_page(url,data=None): wb_data = requests.get(url) soup = BeautifulSoup(wb_data.text,‘lxml‘) # print(soup) imgs = soup.select(‘a.cover-inner > img‘) titles = soup.select(‘section.content > h4 > a‘) links = soup.select(‘section.content > h4 > a‘) for img, title, link in zip(imgs, titles, links): data = { ‘img‘: img.get(‘src‘), ‘title‘: title.get(‘title‘), ‘link‘: link.get(‘href‘) } print(data) def get_more_pages(start,end): for one in range(start,end): get_page(url+str(one)) time.sleep(2) get_more_pages(1, 10)
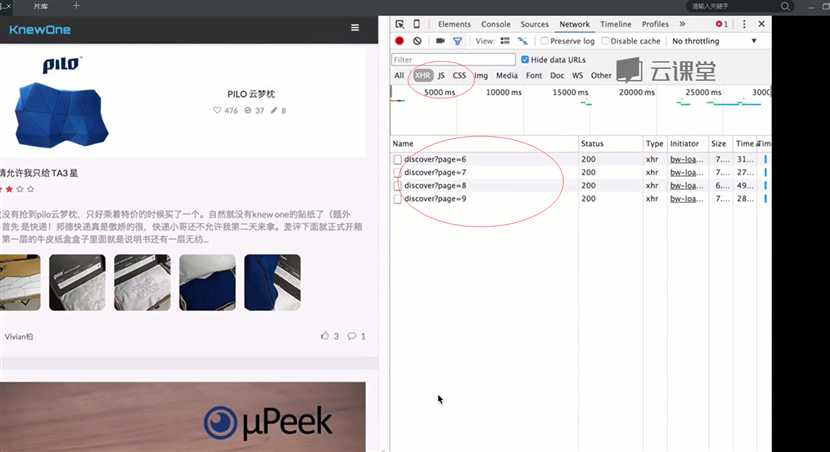
该网站动态表现在不知道页码有多少个,页面往下翻,页面就会自动加载上来
标签:zip ima from .com alt art sele link img
原文地址:http://www.cnblogs.com/Michael2397/p/7748105.html