标签:不为 解析 back 内容 统计 image 前缀 结构 并且
特别声明:
博文主要是学习过程中的知识整理,以便之后的查阅回顾。部分内容来源于网络(如有摘录未标注请指出)。内容如有差错,也欢迎指正!
一、基本概念(来源于网络)
Trie树又称字典树、单词查找树、前缀树等,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
优点:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
缺点:基于空间换时间的思想,所以系统中若存在大量的没有公共前缀的字符串则会消耗大量内存。(使用左儿子右兄弟的方法建树的话,可能相对会好一些,有兴趣的小伙伴可以自己研究下。)
核心思想:空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
三个特性:
1.根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2.从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3.每个节点的所有子节点包含的字符都不相同。
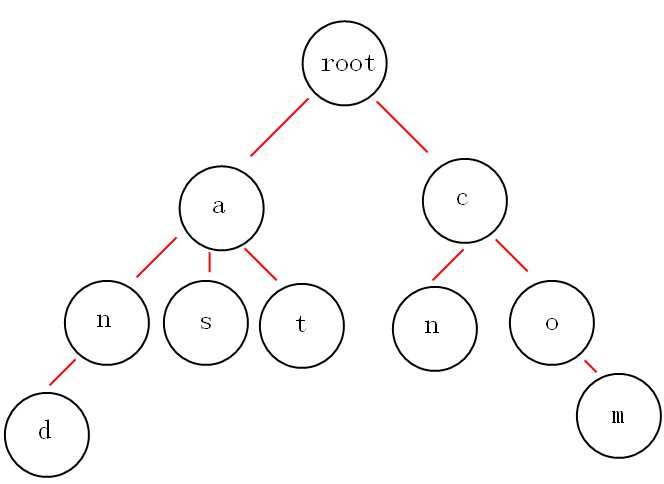
例:and, as, at, cn, com构建的Trie树如下,
二、Trie树的基本操作
假设存在字符串str,Trie树的根结点为root,i=0,p=root
1.插入
3.删除
可以递归删除整棵树
三、Trie树的复杂度
1. 插入、查找的时间复杂度均为O(N), N为字符串的长度。
2.英文字符为例,空间复杂度是26^n, 可采用<双数组实现>来改善。
四、Trie树的应用场景
1.字符串检索、词频统计
将已知的一些字符串(字典)的有关信息实现保存到trie树里,查找另外一些未知字符串是否出现过或者出现频率。
例如:
将要匹配词作为词典,再给出一段文本或者文章。匹配判断文本或文章中是否存在词典中的词。
2.字符串最长公共前缀
Trie树利用多个字符串的公共前缀来节省存储空间,反之,当我们把大量字符串存储到一棵trie树上时,我们可以快速得到某些字符串的公共前缀。
3.排序
只要先序遍历整棵树,输出相应的字符串便是按字典排序的结果
参考:
标签:不为 解析 back 内容 统计 image 前缀 结构 并且
原文地址:http://www.cnblogs.com/konrad/p/7746030.html