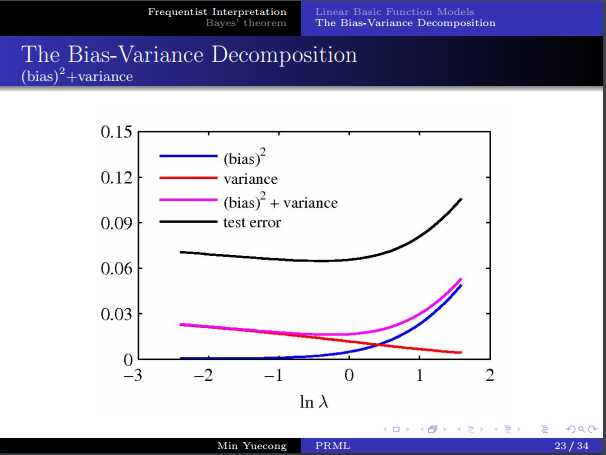
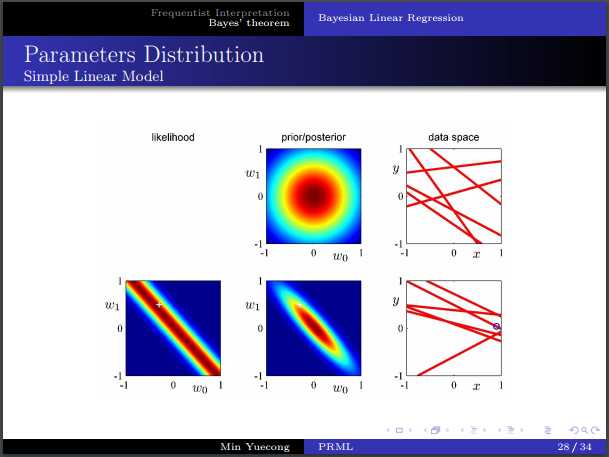
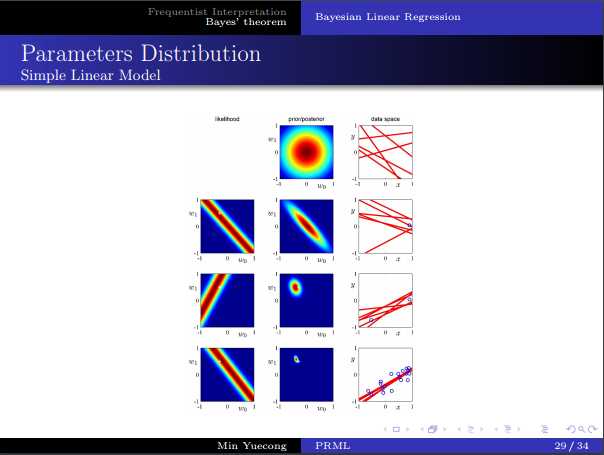
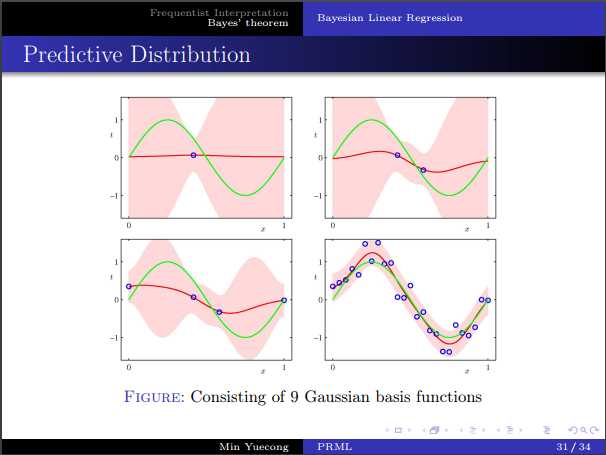
标签:logs 最大 有关 reg log loss 转换 贝叶斯 es2017
讨论课提纲:
大致整理了一下思路,希望明天晚上讲的时候语速慢一点,条例清晰一点,之后再更。
Chapter3_Linear Models for Regression(讨论课)
原文地址:http://www.cnblogs.com/blueprintf/p/7749205.html