标签:来源 关键字 key enc get items print com bre
《 对广州商学院新闻网中的国内动态新闻栏目进行爬取》
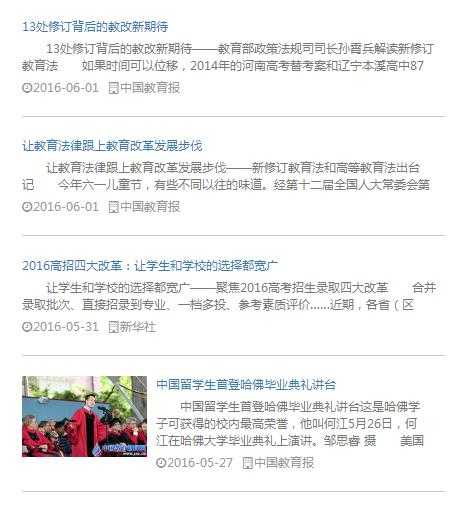
在前不久十九大刚召开完毕,国家主席做了重要讲话并提出不少新的国家政策,因此我提取了我校内过去的新闻页面,网址为(http://news.gzcc.cn/html/gnyw/index.html)。

import requests from bs4 import BeautifulSoup gzccurl = ‘http://news.gzcc.cn/html/gnyw/‘ res = requests.get(gzccurl) res.encoding=‘utf-8‘ soup = BeautifulSoup(res.text,‘html.parser‘) for news in soup.select(‘li‘): if len(news.select(‘.news-list-title‘))>0: title = news.select(‘.news-list-title‘)[0].text #标题 url = news.select(‘a‘)[0][‘href‘] #路径 time = news.select(‘.news-list-info‘)[0].contents[0].text #时间 source = news.select(‘.news-list-info‘)[0].contents[1].text #来源 #正文 resd = requests.get(url) resd.encoding=‘utf-8‘ soupd = BeautifulSoup(resd.text,‘html.parser‘) detail = soupd.select(‘.show-content‘)[0].text print(time,title,url,source) print(detail) break
提取的内容如下:


对以上提取的内容我进行了文本解析:
import jieba xfsn=open("a.txt","r",encode= ‘utf-8‘ ).read() words=jieba.lcut(xfsn) counts={} for word in words: if len(word)==1: continue else: counts[word]=counts.get(word,0)+1 items=list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i in range(50): word,count=items[i] print("{0:<10}{1:>5}".format(word,count))

从以上文本可见我提取网页新闻的关键字大多是关于论文学术方面的,这符合学校新闻网页,在关键字出现的频率中经济学和人文学出现的较多,而我在读的专业计算机出现的次数则为0,这也体现了过去经济文学上的新闻动态较多等等。
生成的词云如下:

标签:来源 关键字 key enc get items print com bre
原文地址:http://www.cnblogs.com/s6134093/p/7762401.html