标签:blank line str spi _id 例子 self strip() 数据存储
其实很简单,就是想要存储的位置发生改变。直接看例子,然后触类旁通。
以大众点评 评论的内容为例 ,位置:http://www.dianping.com/shop/77489519/review_more?pageno=1
数据存储形式由A 变成B
A:
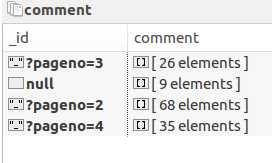
展开的话这样子:

B:
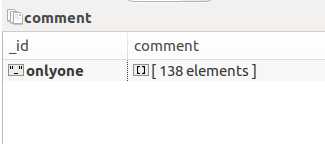
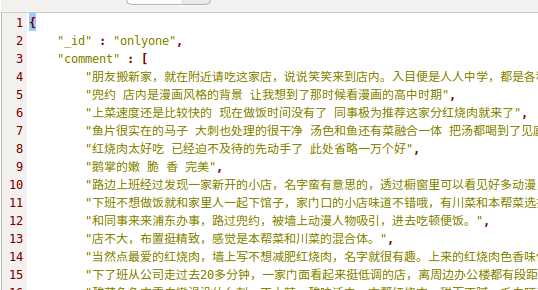
本质上看,就是多个相同类型的item可以合并,不需要那么多,分别来看下各自的代码:
A:
class GengduopinglunSpider(scrapy.Spider): name = ‘gengduopinglun‘ start_urls = [‘http://www.dianping.com/shop/77489519/review_more?pageno=1‘] def parse(self, response): item=PinglunItem() comment = item[‘comment‘] if "comment" in item else [] for i in response.xpath(‘//div[@class="content"]‘): for j in i.xpath(‘.//div[@class="J_brief-cont"]/text()‘).extract(): comment.append(j.strip()) item[‘comment‘]=comment next_page = response.xpath( ‘//div[@class="Pages"]/div[@class="Pages"]/a[@class="NextPage"]/@href‘).extract_first() item[‘_id‘]=next_page # item[‘_id‘]=‘onlyone‘ if next_page != None: next_page = response.urljoin(next_page) # yield Request(next_page, callback=self.shop_comment,meta={‘item‘: item}) yield Request(next_page, callback=self.parse,) yield item
B:
class GengduopinglunSpider(scrapy.Spider): name = ‘gengduopinglun‘ start_urls = [‘http://www.dianping.com/shop/77489519/review_more?pageno=1‘] def parse(self, response): item=PinglunItem() comment = item[‘comment‘] if "comment" in item else [] for i in response.xpath(‘//div[@class="content"]‘): for j in i.xpath(‘.//div[@class="J_brief-cont"]/text()‘).extract(): comment.append(j.strip()) item[‘comment‘]=comment next_page = response.xpath( ‘//div[@class="Pages"]/div[@class="Pages"]/a[@class="NextPage"]/@href‘).extract_first() # item[‘_id‘]=next_page item[‘_id‘]=‘onlyone‘ if next_page != None: next_page = response.urljoin(next_page) yield Request(next_page, callback=self.shop_comment,meta={‘item‘: item}) # yield Request(next_page, callback=self.parse,) # yield item def shop_comment(self, response): item = response.meta[‘item‘] comment = item[‘comment‘] if "comment" in item else [] for i in response.xpath(‘//div[@class="content"]‘): for j in i.xpath(‘.//div[@class="J_brief-cont"]/text()‘).extract(): comment.append(j.strip()) item[‘comment‘]=comment next_page = response.xpath( ‘//div[@class="Pages"]/div[@class="Pages"]/a[@class="NextPage"]/@href‘).extract_first() if next_page != None: next_page = response.urljoin(next_page) yield Request(next_page, callback=self.shop_comment,meta={‘item‘: item}) yield item
B里面是有重复代码的,这个无关紧要,只是演示,注意看两个yield 的区别
以上只是演示scrapy中yield的用法,用来控制item,其余pipline,setting未展示.
标签:blank line str spi _id 例子 self strip() 数据存储
原文地址:http://www.cnblogs.com/dahu-daqing/p/7769040.html