标签:dex 2014年 href 静态 这一 更改 变量 权限 jdk
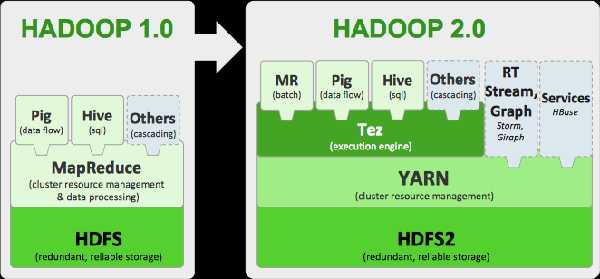
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列《Hadoop学习笔记系列》。其实,早在2014年Hadoop2.x版本就已经开始流行了起来,并且已经成为了现在的主流。当然,还有一些非离线计算的框架如实时计算框架Storm,近实时计算框架Spark等等。相信了解Hadoop2.x的童鞋都应该知道2.x相较于1.x版本的更新应该不是一丁半点,最显著的体现在两点:
(1)HDFS的NameNode可以以集群的方式布署,增强了NameNodes的水平扩展能力和高可用性,分别是:HDFS Federation与HA;
(2)MapReduce将JobTracker中的资源管理及任务生命周期管理(包括定时触发及监控),拆分成两个独立的组件,并更名为YARN(Yet Another Resource Negotiator);
因此,我决定趁着现在又变成了单身狗(满满的都是伤感)的时机,把Hadoop2.x学习一下,也顺带分享一些学习笔记的文章与园友们分享。
至于Hadoop2.x到底相较于1.x有哪些改变,如果你不太知道,那么你可以先阅读一下这篇文章《Hadoop2的改进内容简介》大概了解一下,本篇内容将不会介绍这些,直接上环境搭建与配置的内容。
(1)一台配置不错的电脑或笔记本(主要是内存、内存、内存,重要的事情说三遍)
(2)一个你使用过的虚拟机软件(可以是VMWare、Virtual Box或者其他的,我用的VMWare WorkStation)
(3)一个你使用过的SSH客户端软件(可以使XShell,XFtp、WinSCP等等,我用的XShell+XFtp)
(4)Hadoop2.4.1、JDK1.7的linux安装包(当然你也可以直接在线下载)
当然,体贴的我已为你准备了Hadoop2.4.1和JDK1.7的包,你可以通过这个链接下载:点我下载
安装完VMware Workstation之后,你的网络适配器会多出来两个,你要做的就是为多出来的第2个网卡设置静态IP地址,我这里是Ethernet 3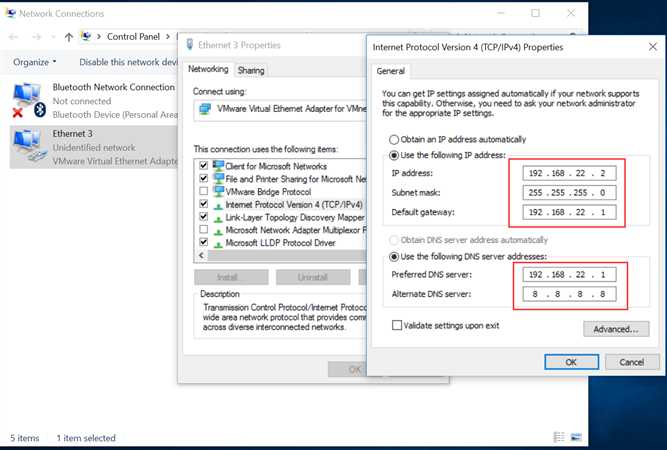 这里我们设置网关为192.168.22.1,为宿主机设置IP为192.168.22.2,也就是说我们的虚拟机必须要在192.168.22.x这个网段内。
这里我们设置网关为192.168.22.1,为宿主机设置IP为192.168.22.2,也就是说我们的虚拟机必须要在192.168.22.x这个网段内。
然后我们再为虚拟机设置网络连接方式,选择VMNET8(NAT模式),如果你不知道NAT是什么意思,请百度一下。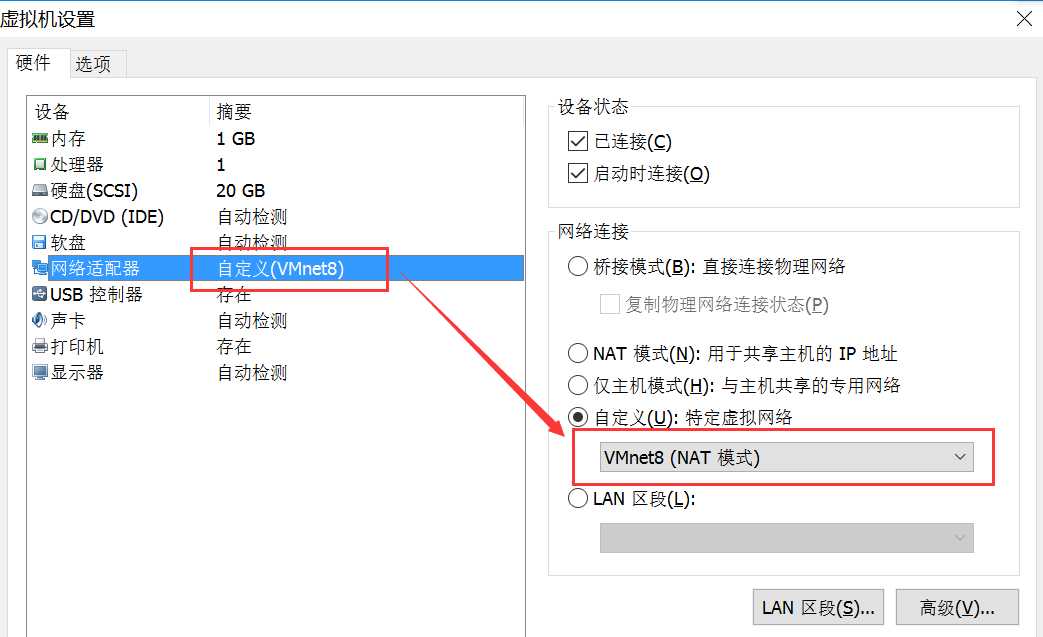
这里我们选择的是CentOS,你也可以选择其他的Linux发行版本。
输入命令 setup -> 进入Device Configuration -> 输入service network restart重启网卡
另外,想要在宿主机访问虚拟机,需要开放端口,为了方便,我们直接将虚拟机的防火墙关闭:sudo service iptables stop
检查状态:sudo chkconfig iptables off
输入命令 sudo vi /etc/inittab -> 修改id:3 -> 输入reboot重启虚拟机
这个时候你就可以使用XShell而不再需要在VMware里直接敲命令了,你会发现XShell用起来很爽!
由于linux下root用户的权限太大,经常使用root用户会很不安全,所以我们一般使用一个一般用户去操作,在用到需要高权限时使用sudo命令去执行。因此,我们这里需要将hadoop用户加入sudo用户组。
输入命令 su -> vi /etc/sudoers -> 找到这一行:root ALL=(ALL) ALL
然后在它下面一行加上一行:hadoop ALL=(ALL) ALL
最后保存退出。
(1) sudo vi /etc/sysconfig/network -> hadoop-master.manulife -> reboot
(2) sudo vi /etc/hosts -> 加一行: 192.168.22.100 hadoop-master.manulife
(1) rm -rf P* D* Music/ Videos/ Templates/
(2) mkdir app -> 安装后的地方
(3) mkdir local -> 放置安装包的地方
(1)上传jdk到虚拟机,这里借助SFtp软件
(2)解压jdk:tar -zvxf jdk -C ../app/
(3)设置环境变量:
sudo vi /etc/profile
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export PATH=$PATH:$JAVA_HOME/bin;
source /etc/profile
(1)上传jdk到虚拟机,这里借助SFtp软件
(2)解压jdk:tar -zvxf hadoop -C ../app/
(3)删除hadoop中share文件夹中的多余doc文件(非必要):rm -rf doc
(4)设置hadoop中etc文件夹中的一些重要配置文件:cd etc -> hadoop-env.sh,core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml
hadoop-env.sh
vim hadoop-env.sh
#第27行
export JAVA_HOME=/home/hadoop/app/jdk
core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master.manulife:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop/tmp</value>
</property>
hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master.manulife</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
mapred-site.xml (需要首先换个名字:mv mapred-site.xml.template mapred-site.xml)
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5)设置环境变量
sudo vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_65
export HADOOP_HOME=/itcast/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile
(6)格式化NameNode
hadoop namenode -format
(7)启动Hadoop两大核心功能:HDFS与YARN
首先编辑slaves配置文件(这里我们的主节点既是DataNode又是NameNode):vi slaves -> add hadoop-master.manulife
启动HDFS:sbin/start-dfs.sh
启动YARN:sbin/start-yarn.sh
验证是否启动:jps
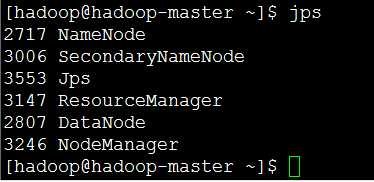
(8)在宿主机中访问Hadoop Manager
首先将虚拟机的IP地址和主机名加入Windows Hosts:windows/system32/etc -> 加一行 : 192.168.22.100 hadoop-master.manulife
打开浏览器输入:http://hadoop-master.manulife:50070
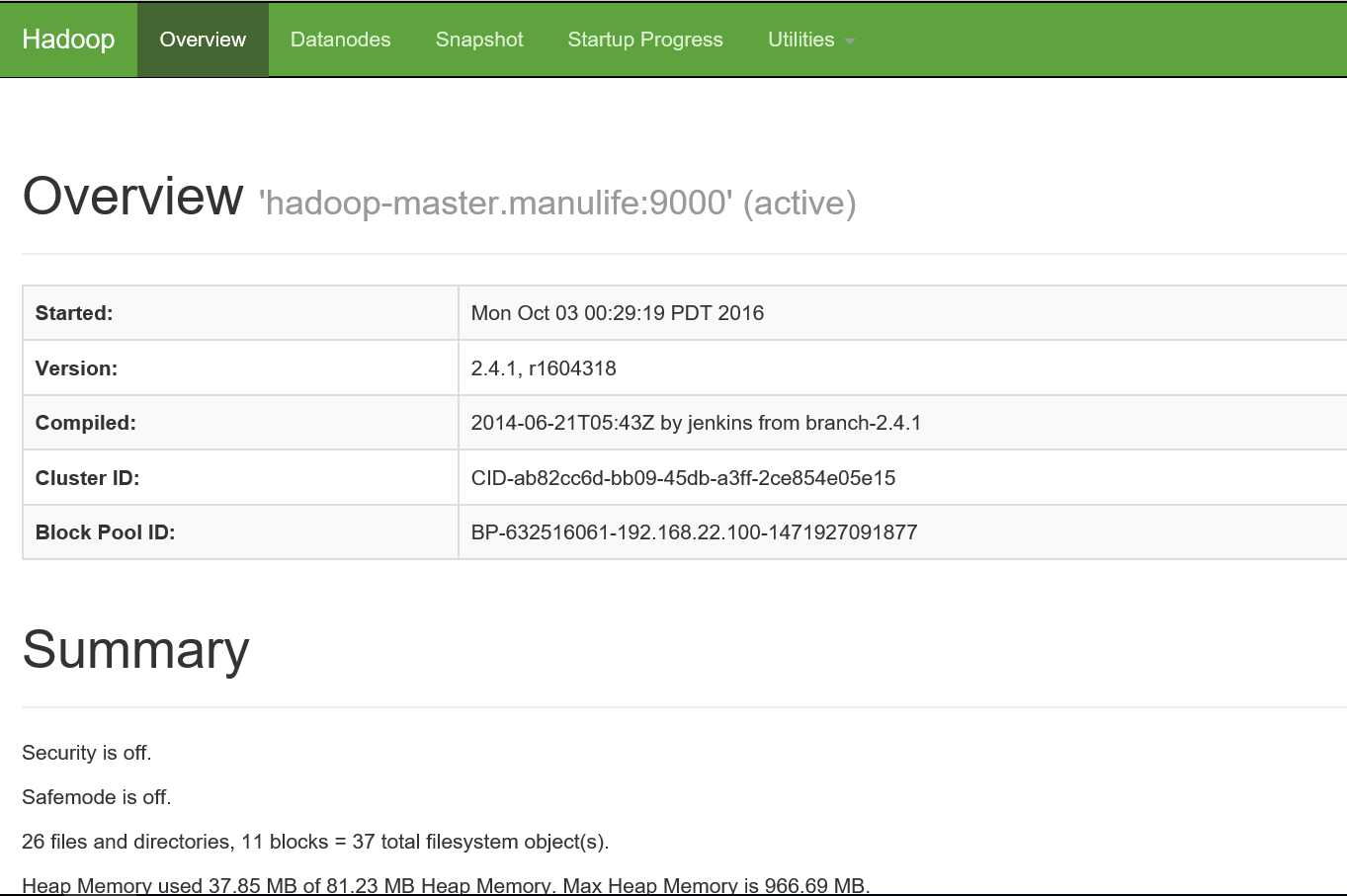

上传一个文件至HDFS : hadoop fs -put xxxx.tar.gz hdfs://hadoop-master.manulife:9000/
从HDFS下载一个文件 : hadoop fs -get hdfs://hadoop-master.manulife:9000/xxxx.tar.gz
这里直接运行一个hadoop自带的求圆周率的example:
(1)cd /home/hadoop/app/hadoop/share/hadoop/mapreduce/
(2)hadoop jar hadoop-mapreduce-examples-2.4.1.jar pi 5 5
一般linux分布式集群中都会设置ssh免密码登录,这里我们首先将主节点设置为ssh免密码登录:
(1)ssh-keygen -t rsa
(2)cd .ssh -> cp id_rsa.pub authorized_keys
(3)ssh localhost
Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
标签:dex 2014年 href 静态 这一 更改 变量 权限 jdk
原文地址:http://www.cnblogs.com/zzmmyy/p/7777456.html