标签:关系型数据库 www. 发展 经典的 入门 美的 hba 存储设备 计算

这是一个信息爆炸的时代。经过数十年的积累,很多企业都聚集了大量的数据。这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼数成金成为当务之急。但数据增长的速度往往比cpu和内存性能增长的速度还要快得多。要处理海量数据,如果求助于昂贵的专用主机甚至超级计算机,成本无疑很高,有时即使是保存数据,也需要面对高成本的问题,因为具有海量数据容量的存储设备,价格往往也是天文数字。成本和IT能力成为了海量数据分析的主要瓶颈。
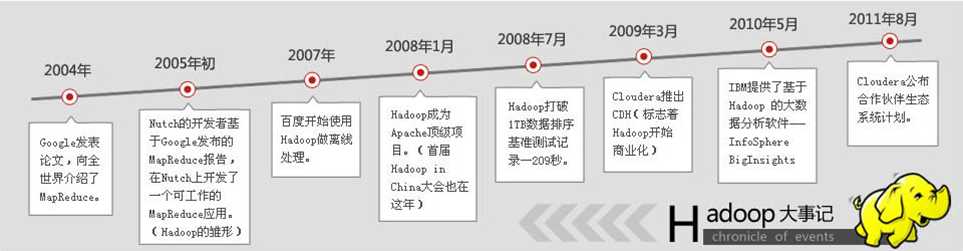
Hadoop这个开源产品的出现,打破了对数据力量的压制。Hadoop源于Nutch这个小型的搜索引擎项目。而Nutch则出自于著名的开源搜索引擎解决方案Lucene,而Lucene则来源于对Google的学习模仿。在Hadoop身上有着明显的Google的影子。HDFS是GFS的山寨版,Map-Reduce的思想来源于Goolge对Page rank的计算方法,HBase模仿的是Big Table,Zookeeper则学习了Chubby。Google巨人的力量尽管由于商业的原因被层层封锁,但在Hadoop身上得到了完美的重生和发展。
从2006年Apache基金会接纳Hadoop项目以来。Hadoop已经成为云计算软件的一个事实标准,以及开源云计算解决方案的几乎唯一选择。对于想用低成本(包括软硬件)实现云计算平台或海量数据分析平台的用户,Hadoop集群是首选的对象。由于Hadoop在各方面都打破了传统关系型数据库的思路和模式,对于新接触Hadoop平台的人,往往会觉得困惑和难以理解,进而转化为畏惧。

因此,为了赶上大数据时代的发展,迎接云计算的思维,尽管我做的是.NET的应用开发工作,但我仍然选择业余时间学习Hadoop。我会从Hadoop1.x版本开始学习经典的HDFS与MapReduce,然后了解Hadoop2.x版本与老版本的差异,熟悉一些常见的Hadoop应用场景,并学着实践一个最经典的项目(网站日志数据分析案例)来完成我给自己规划的学习任务。
(1)基础介绍与环境搭建
(13)分布式集群中节点的动态添加与下架
(4)初识MapReduce
(7)计数器与自定义计数器
(11)MapReduce中的排序和分组
(12)MapReduce中的常见算法
(14)ZooKeeper环境搭建
(15)HBase框架学习之基础知识篇
(15)HBase框架学习之基础实践篇
(16)Pig框架学习
(17)Hive框架学习
(18)Sqoop框架学习
(19)Flume框架学习
(20)网站日志分析项目(一)项目介绍
(20)网站日志分析项目(二)数据清洗
(20)网站日志分析项目(三)统计分析
(21)Hadoop2的改进内容简介
(22)Hadoop2.x环境搭建与配置
标签:关系型数据库 www. 发展 经典的 入门 美的 hba 存储设备 计算
原文地址:http://www.cnblogs.com/zzmmyy/p/7777459.html