标签:应用 密码登录 置配 独立 jdk 1.5 查看 ack 通过
开篇:在本笔记系列的第一篇中,我们介绍了如何搭建伪分布与分布模式的Hadoop集群。现在,我们来了解一下在一个Hadoop分布式集群中,如何动态(不关机且正在运行的情况下)地添加一个Hadoop节点与下架一个Hadoop节点。
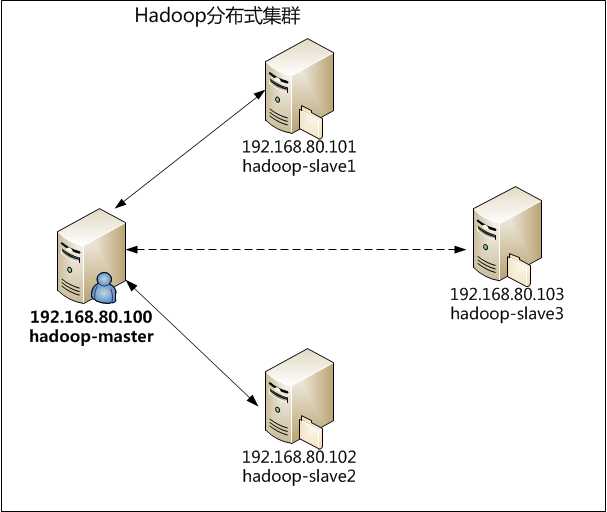
本次试验,我们构建的集群是一个主节点,三个从节点的结构,其中三个从节点的性能配置各不相同,这里我们主要在虚拟机中的内存设置这三个从节点分别为:512MB、512MB与256MB。首先,我们暂时只设置两个从节点,另外一个作为动态添加节点的时候使用。主节点与从节点所扮演的角色如下所示:
主节点(1个,主机名:hadoop-master):NameNode、JobTracker、SecondaryNameNode
从节点(3个,主机名:hadoop-slave1、hadoop-slave2、hadoop-slave3):DataNode、TaskTracker
TIPS:当然,我们也可以将SecondaryNameNode作为一个独立的节点分离出去,只需要增加一台服务器,并在主节点中修改hadoop中的配置文件:masters,将新节点的主机名添加进去即可。
在实际生产应用中,很多时候因为现有集群的性能问题需要增加服务器节点以提高整体性能(一般是增加从节点,在Hadoop2.x之后解决了主节点的单点问题,可以增加主节点以保持HA高可用性),这就涉及到动态添加节点的问题。还好,Hadoop早就提供了很好的解决方法,我们只需要如下几步就可以轻松地添加一个节点:
(1)准备工作:配置新节点的各种环境
主要包括:设置IP地址、主机名、绑定IP地址与主机名的映射、生成SSH与各节点之间的无密码登录、安装JDK与Hadoop、设置配置文件;当然,都可以通过复制解决;
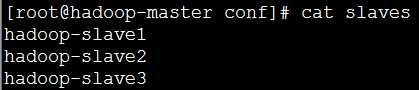
(2)在主节点中的slaves配置文件中添加要新加入的节点的主机名hadoop-slave3(在hadoop目录下/conf/slaves)
(3)在新节点hadoop-slave3中,通过Hadoop Shell启动datanode与tasktracker进程:

这两句shell命令分别是:
hadoop-daemon.sh start datanode
hadoop-daemon.sh start tasktracker
(4)在主节点中通过Hadoop Shell刷新从节点列表,获取新加入的节点信息:hadoop dfsadmin -refreshNodes
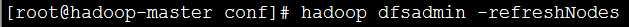
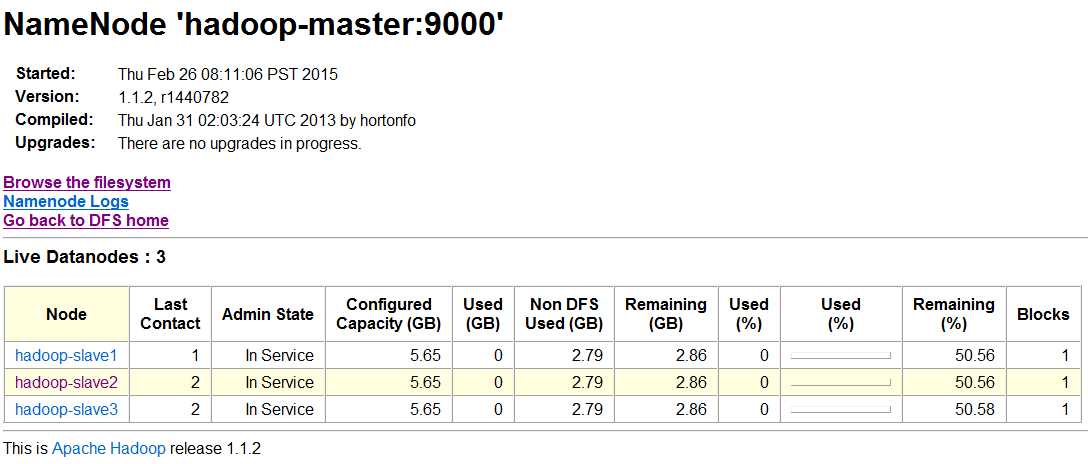
(5)在主节点的Web接口中查看Live Nodes数量变为了3,代表动态添加从节点成功
在实际生产应用中,也会存在某个节点或某些节点因为某种原因而停止服务或者宕机的情况,Hadoop会通知一定的感知机制得到这些停止服务的节点的信息,从而通过其他节点获取文件(前提是我们所设置的副本数量>=2,默认为3)。
(1)通过关闭hadoop-slave3的电源或者输入一个shell命令停止datanode进程:hadoop-daemon.sh stop datanode
->这里我们可以通过后者,这个shell命令来看看
(2)我们现在再通过主节点的Web接口来看看运行情况:
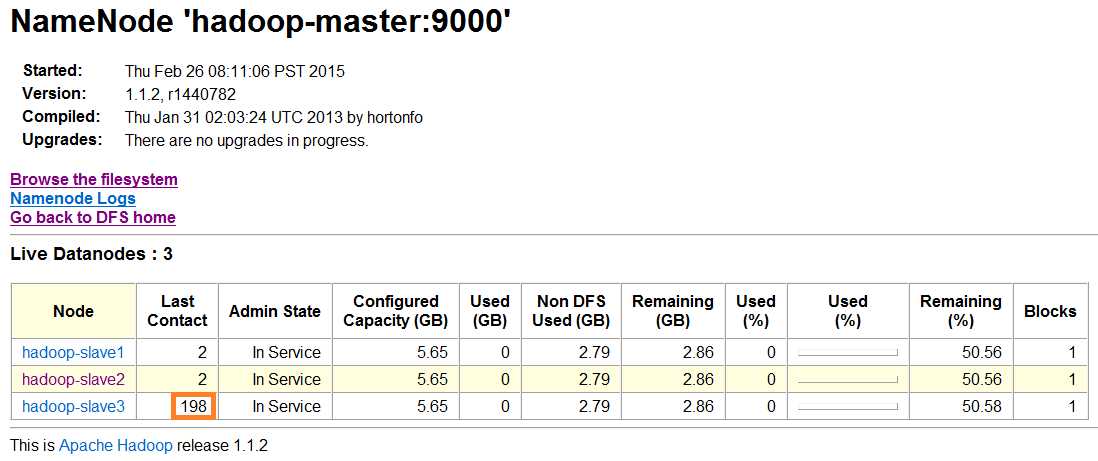
PS:停止hadoop-slave3的datanode进程后发现,NameNode的Web接口上hadoop-slave节点的LastContact字段的值会不断地增大。这是因为DataNode每次启动时都会向NameNode汇报,NameNode会记录下它的访问时间,然后NameNode用当前访问时间减去上次访问时间,就得出LastContact的值,也就是多长时间未访问。又由于实际环境中经常存在网络问题造成短暂掉线,所以NameNode会等待一段时间(默认等10分钟)之后,才会将它视为死节点。所以,为了防止数据丢失所以在实际中副本数一般会设为2以上(默认为3),当某个节点死掉以后,可以通过副本找回数据。
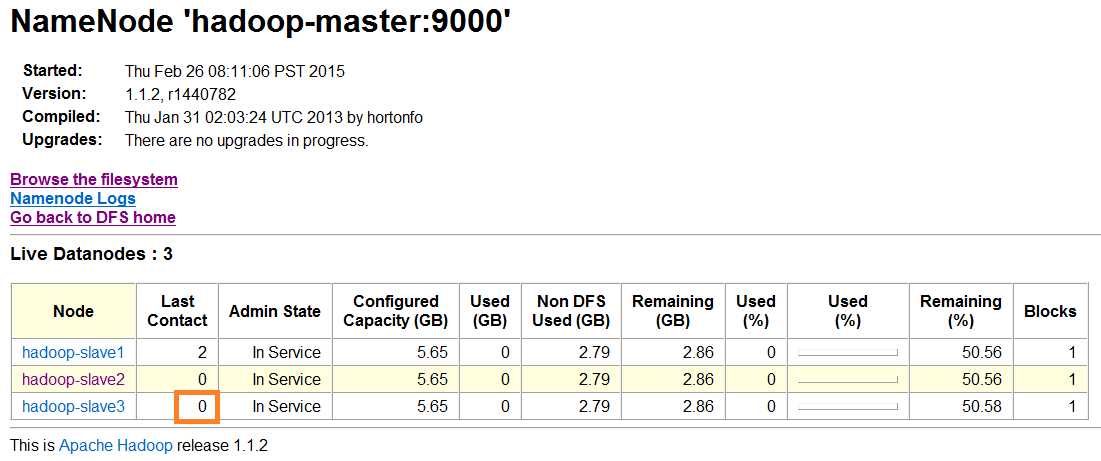
(3)重新启动hadoop-slave3的datanode进程:hadoop-daemon.sh start datanode
(4)现在再次通过主节点的Web接口来看看运行情况:变为了0
当Hadoop的NameNode节点启动时,会进入安全模式阶段。
(1)在此阶段,DataNode会向NameNode上传它们数据块的列表,让 NameNode得到块的位置信息,并对每个文件对应的数据块副本进行统计。当最小副本条件满足时,即一定比例的数据块都达到最小副本数,系统就会退出安全模式,而这需要一定的延迟时间。
(2)当最小副本条件未达到要求时,就会对副本数不足的数据块安排DataNode进行复制,直至达到最小副本数。而在安全模式下,系统会处于只读状态,NameNode不会处理任何块的复制和删除命令。
那么,如何判断HDFS是否处于安全模式呢?hadoop dfsadmin -safemode get

如何手动进入和离开安全模式呢?hadoop dfsadmin -safemode enter/leave

进入安全模式后,再向HDFS上传或修改文件会出现什么情况?一个提示“正在处于安全模式”的异常

org.apache.hadoop.dfs.SafeModeException: Cannotdelete/user/hadoop/input. Name node is in safe mode.从字面上来理解:“Name nodeis in safe mode.”hadoop的namenode处于安全模式。
(1)吴超,《Hadoop深入浅出》:http://www.superwu.cn
(2)Suddenly,《Hadoop日记Day19-分布式安装》:http://www.cnblogs.com/sunddenly/p/4011455.html
(3)michael_zhu,《Hadoop安全模式的理解》:http://blog.csdn.net/michael_zhu_2004/article/details/8268728
原文链接:http://www.cnblogs.com/edisonchou/
Hadoop学习笔记—13.分布式集群中节点的动态添加与下架
标签:应用 密码登录 置配 独立 jdk 1.5 查看 ack 通过
原文地址:http://www.cnblogs.com/zzmmyy/p/7777370.html