标签:基本 img style nbsp ... log 返回 指定 一个
1.去除重复数据。
函数:duplicated(x, incomparables = FALSE, MARGIN = 1,fromLast = FALSE, ...),返回一个布尔值向量,重复数据的第一个为FALSE,其他为TRUE。
x可以是vector或data.frame。为data.frame时,数据的基本单位是行。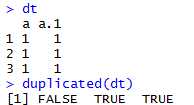
2.把一行数据或一列数据传递给指定的函数。
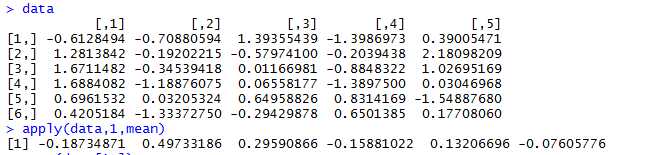
函数:apply(X, MARGIN, FUN, ...),返回一个结果向量。
x是数据,可以是矩阵,数据框。margin是维度,在矩阵或数据框中,1表示行,2表示列。FUN是指定的函数。
3.把数据分组,然后用指定函数对每组进行统计操作。
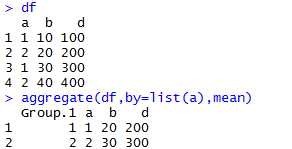
函数:aggregate(x,by,fun),返回一个结果数据框。
x是数据框数据。by是按什么分类的list。fun是指定的函数。
标签:基本 img style nbsp ... log 返回 指定 一个
原文地址:http://www.cnblogs.com/timeisbiggestboss/p/7778001.html