标签:span 2-2 分布式开发 节点 children 系统 空间 fast blog
Zookeeper用途场景:
1:zookeeper分布式服务框架:是Apache Hadoop的一个子项目,主要是用来解决分布式应用场景中经常遇到的一些数据管理问题。
2:如:集群管理、统一命名服务、分布式配置管理、分布式消息队列、分布式锁、分布式通知协调等。
3:越来越多的分布式计算开始强依赖ZK,比如Storm、Hbase.
4:Zookeeper对分布式开发带来很多便利,用ZK的独有特性巧妙的解决了很多难题:很多分布式技术用到Zookeeper或多或少特性,尤其是新生代分布式技术几乎都会依赖Zookeeper特性,如Hbase、火爆的Storm。
为什么后来深入学习Zookeeper?
随着分布式应用的不断深入,需要对集群管理逐步透明化,监控集群和作业状态:可以充分利用ZK的独有特性。熟悉程度决定应用高度。
ZK体系结构:
Server端具有fast fail特性,非常健壮。无单点。不超过半数Server挂掉不影响提供服务。Master/slave主流模式。(fast fail特性:“快速失败”也就是fail-fast,它是Java集合的一种错误检测机制。当多个线程对集合进行结构上的改变的操作时,有可能会产生fail-fast机制。记住是有可能,而不是一定。例如:假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生fail-fast机制。 Master/slave模式:)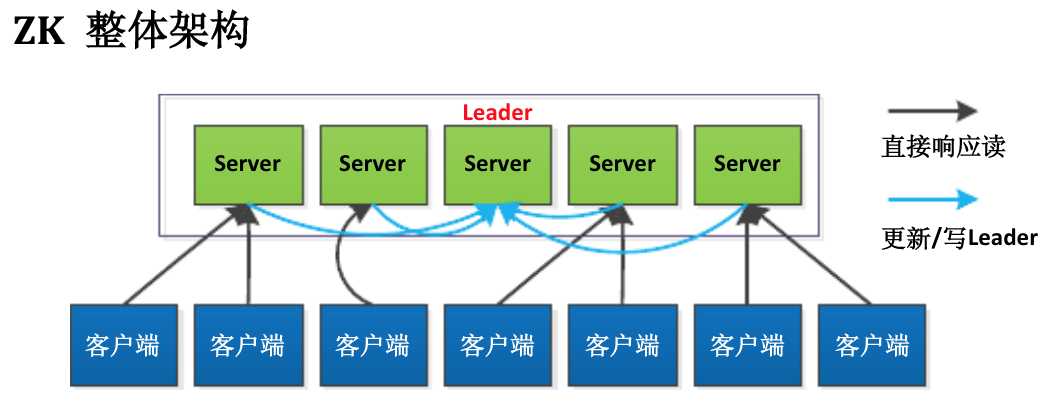
ZK是一套高吞吐的分布式协调系统,同一时刻可以同时响应上万个客户端请求。ZK服务由若干个服务器构成,每台服务器内存中维护相同的类似于文件系统的树形数据结构。其中的一台通过ZAB原子广播协议选举作为主控服务器,其它的作为从属服务器。客户端可以通过TCP协议连接任意一台服务器,如果客户端是读操作请求,任意一个服务器都可以直接响应请求;如果是更新数据操作(写数据或更新数据),则只能由主控服务器来协调更新操作;如果客户端连接的是从属服务器,则从属服务器会将更新数据请求转发到主控服务器,由其完成更新操作。
ZK的主控服务器将所有更新操作序列化(客户端通过TCP协议连接,所以可以保证客户端请求的顺序性,同时系统内所有更新操作都需要经过主控服务器,这两点可以保证更新操作的全局序列性)。
Zookeeper数据结构(类似于文件系统的树形数据结构): 节点:/NameService/Service1 : 唯一路径(node),且携带数据。
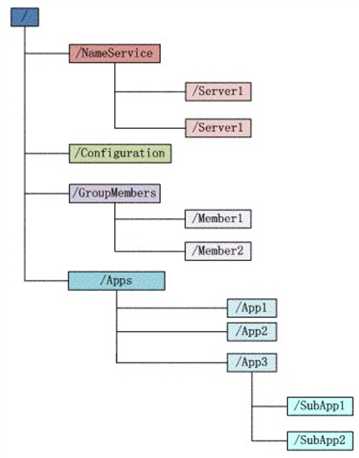
zookeeper名字空间由节点znode构成,其组织方式类似文件系统,其中各个节点相当于目录和文件,通过路径作为唯一标识。与系统文件不同的是,每个节点具有与之对应的数据内容,同时也可以具有子节点。
zookeeper用于存储协调数据,如状态、配置、位置等信息,每个节点存储的数据量很小,KB级别。
节点维护一个状态stat结构(包含数据变化的版本号、ACL变化、时间戳),已允许缓存验证与协调更新。每个节点数据内容改变,多一个版本号,类似Hbase。客户端获取数据的同时也会获取数据版本号。节点的数据内容以原子的方式读写。
节点具有一个访问控制列表(Access Control List - ACL)来约束访问控制操作,即具有权限控制。
Watch:
所有的Zookeeper读操作,包括getData()、getChildren()和exists(),都有一个开关,可以在操作的同时再设置一个watch。在ZooKeeper中,Watch是一个一次性触发器,会在被设置watch的数据发生变化的时候,发送给设置watch的客户端。watch的定义中有三个关键点:
一次性触发器
一个watch事件将会在数据发生变更时发送给客户端。例如,如果客户端执行操作getData(“/znode1″, true),而后/znode1 发生变更或是删除了,客户端都会得到一个/znode1 的watch事件。如果/znode1 再次发生变更,则在客户端没有设置新的watch的情况下,是不会再给这个客户端发送watch事件的。
发送给客户端
这就是说,一个事件会发送给客户端,但可能在操作成功的返回值到达发起变动的客户端之前,这个事件还没有送达watch的客户端。Watch是异步发送的。但ZooKeeper保证了一个顺序:一个客户端在收到watch事件之前,一定不会看到它设置过watch的值的变动。网络时延和其他因素可能会导致不同的客户端看到watch和更新返回值的时间不同。但关键点是,每个客户端所看到的每件事都是有顺序的。
被设置了watch的数据
这是指节点发生变动的不同方式。你可以认为ZooKeeper维护了两个watch列表:data watch和child watch。getData()和exists()设置data watch,而getChildren()设置child watch。或者,可以认为watch是根据返回值设置的。getData()和exists()返回节点本身的信息,而getChildren()返回子节点的列表。因此,setData()会触发znode上设置的data watch(如果set成功的话)。一个成功的create() 操作会触发被创建的znode上的数据watch,以及其父节点上的child watch。而一个成功的?delete()操作将会同时触发一个znode的data watch和child watch(因为这样就没有子节点了),同时也会触发其父节点的child watch。
Watch由client连接上的ZooKeeper服务器在本地维护。这样可以减小设置、维护和分发watch的开销。当一个客户端连接到一个新的服务器上时,watch将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到watch的。而当client重新连接时,如果需要的话,所有先前注册过的watch,都会被重新注册。通常这是完全透明的。只有在一个特殊情况下,watch可能会丢失:对于一个未创建的znode的exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个watch事件可能会被丢失。
Zookeeper比较流行的应用场景:



标签:span 2-2 分布式开发 节点 children 系统 空间 fast blog
原文地址:http://www.cnblogs.com/luosongjun/p/7785050.html