标签:mod 标准 port 输出 func test erro ptime open
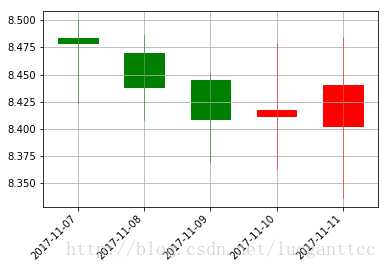
1 from matplotlib.dates import DateFormatter, WeekdayLocator, DayLocator, MONDAY,YEARLY 2 from matplotlib.finance import quotes_historical_yahoo_ohlc, candlestick_ohlc 3 #import matplotlib 4 import tushare as ts 5 import pandas as pd 6 import matplotlib.pyplot as plt 7 from matplotlib.pylab import date2num 8 import datetime 9 import numpy as np 10 from pandas import DataFrame 11 from numpy import row_stack,column_stack 12 13 df=ts.get_hist_data(‘601857‘,start=‘2016-06-15‘,end=‘2017-11-06‘) 14 dd=df[[‘open‘,‘high‘,‘low‘,‘close‘]] 15 16 #print(dd.values.shape[0]) 17 18 dd1=dd .sort_index() 19 20 dd2=dd1.values.flatten() 21 22 g1=dd2[::-1] 23 24 g2=g1[0:120] 25 26 g3=g2[::-1] 27 28 gg=DataFrame(g3) 29 30 gg.T.to_excel(‘gg.xls‘) 31 32 33 34 #dd3=pd.DataFrame(dd2) 35 #dd3.T.to_excel(‘d8.xls‘) 36 37 g=dd2[0:140] 38 for i in range(dd.values.shape[0]-34): 39 40 s=dd2[i*4:i*4+140] 41 g=row_stack((g,s)) 42 43 fg=DataFrame(g) 44 45 print(fg) 46 fg.to_excel(‘fg.xls‘) 47 48 49 #-*- coding: utf-8 -*- 50 #建立、训练多层神经网络,并完成模型的检验 51 #from __future__ import print_function 52 import pandas as pd 53 54 55 inputfile1=‘fg.xls‘ #训练数据 56 testoutputfile = ‘test_output_data.xls‘ #测试数据模型输出文件 57 data_train = pd.read_excel(inputfile1) #读入训练数据(由日志标记事件是否为洗浴) 58 data_mean = data_train.mean() 59 data_std = data_train.std() 60 data_train1 = (data_train-data_mean)/5 #数据标准化 61 62 y_train = data_train1.iloc[:,120:140].as_matrix() #训练样本标签列 63 x_train = data_train1.iloc[:,0:120].as_matrix() #训练样本特征 64 #y_test = data_test.iloc[:,4].as_matrix() #测试样本标签列 65 66 from keras.models import Sequential 67 from keras.layers.core import Dense, Dropout, Activation 68 69 model = Sequential() #建立模型 70 model.add(Dense(input_dim = 120, output_dim = 240)) #添加输入层、隐藏层的连接 71 model.add(Activation(‘relu‘)) #以Relu函数为激活函数 72 model.add(Dense(input_dim = 240, output_dim = 120)) #添加隐藏层、隐藏层的连接 73 model.add(Activation(‘relu‘)) #以Relu函数为激活函数 74 model.add(Dense(input_dim = 120, output_dim = 120)) #添加隐藏层、隐藏层的连接 75 model.add(Activation(‘relu‘)) #以Relu函数为激活函数 76 model.add(Dense(input_dim = 120, output_dim = 20)) #添加隐藏层、输出层的连接 77 model.add(Activation(‘sigmoid‘)) #以sigmoid函数为激活函数 78 #编译模型,损失函数为binary_crossentropy,用adam法求解 79 model.compile(loss=‘mean_squared_error‘, optimizer=‘adam‘) 80 81 model.fit(x_train, y_train, nb_epoch = 100, batch_size = 8) #训练模型 82 model.save_weights(‘net.model‘) #保存模型参数 83 84 inputfile2=‘gg.xls‘ #预测数据 85 pre = pd.read_excel(inputfile2) 86 87 pre_mean = data_mean[0:120] 88 pre_std = pre.std() 89 pre1 = (pre-pre_mean)/5 #数据标准化 90 91 pre2 = pre1.iloc[:,0:120].as_matrix() #预测样本特征 92 r = pd.DataFrame(model.predict(pre2)) 93 rt=r*5+data_mean[120:140].as_matrix() 94 print(rt.round(2)) 95 96 97 98 rt.to_excel(‘rt.xls‘) 99 100 #print(r.values@data_train.iloc[:,116:120].std().values+data_mean[116:120].as_matrix()) 101 102 103 104 a=list(df.index[0:-1]) 105 106 b=a[0] 107 108 c= datetime.datetime.strptime(b,‘%Y-%m-%d‘) 109 110 d = date2num(c) 111 112 113 c1=[d+i+1 for i in range(5)] 114 c2=np.array([c1]) 115 116 r1=rt.values.flatten() 117 r2=r1[0:4] 118 for i in range(4): 119 120 r3=r1[i*4+4:i*4+8] 121 r2=row_stack((r2,r3)) 122 123 c3=column_stack((c2.T,r2)) 124 r5=DataFrame(c3) 125 126 if len(c3) == 0: 127 raise SystemExit 128 129 fig, ax = plt.subplots() 130 fig.subplots_adjust(bottom=0.2) 131 132 #ax.xaxis.set_major_locator(mondays) 133 #ax.xaxis.set_minor_locator(alldays) 134 #ax.xaxis.set_major_formatter(mondayFormatter) 135 #ax.xaxis.set_minor_formatter(dayFormatter) 136 137 #plot_day_summary(ax, quotes, ticksize=3) 138 candlestick_ohlc(ax, c3, width=0.6, colorup=‘r‘, colordown=‘g‘) 139 140 ax.xaxis_date() 141 ax.autoscale_view() 142 plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment=‘right‘) 143 144 ax.grid(True) 145 #plt.title(‘000002‘) 146 plt.show()
标签:mod 标准 port 输出 func test erro ptime open
原文地址:http://www.cnblogs.com/xuyuan77/p/7794875.html