标签:规模 img app 预测 删除 span 影响 效率 通过
一 . 文本聚类介绍
文本聚类是文本挖掘(Text Mining)的重要手段和方法,也是数据挖掘的一个重要分支。文本聚类是一种无监督的文档分类,它把一个文本集分成若干称为簇(Cluster) 的子集,每个簇的文本之间具有较大的相似性,而簇间的文本具有较小的相似性。
二 . 文本聚类过程
文本聚类的过程一般包括以下几个过程:
1.文本预处理(分词和停用词)。模式表示:包括特征抽取及选择,把数据对象表示成适合于算法的可计算形式。(关键)
2.定义模式之间的距离测量公式。
3.聚类算法实现。
4.评价输出的结果。
下面分别介绍每一步骤。
三. 文本聚类概述
3.1 分词
爬取或搜集到的一个txt文本里面是一系列词语拼凑而成的文章。分词就是根据语法结构把包含在句子里或文章里的词划分开来。例如“我是一名学霸” 分词为" 我 是 一名 学霸 "。 对于英文文本来说比较简单,因为英文以词作为基本单位,且词与词之间用空格分开。但是中文词与词之间分隔非常不明显,而中文又十分灵活,所以中文分词更复杂。
一般而言中文分词包括以下三类:
在实际操作中,可以利用中科院计算所的汉语语法分析系统ICTCLAS来分词,或者利用Python的库jieba(不得不服python的三方库)来实现。
3.2 停用词
分词得到的结果可能类似于如下:
“ 经济 的 增长 在 2004 年 就 达到 了 75 亿 元 ,年 均 复合 增长率 为 102.7 % 。艾 瑞 预测 2007 年 我国 网上 的 ...”
可以看到文本中许多类似于 ‘的’、数字、‘于是’、‘因为’、‘可能’、‘就’ 的词语以及各种各样的标点符号非常之多!不仅会影响文本特征的提取,而且使文本非常冗余。所以需要将所有这些应该被过滤掉的词(这些字或词即被称为Stop Words(停用词))放到一起生成一个停用词表。在得到一个分词后的文本后,再通过停用词过滤就可以得到较为干净的数据,接下来就可以从这些数据中提取特征。
3.3 文本特征提取 & 降维
由于文本中可能含有大量词,给文本处理造成很大困难。而特征抽取就是在不改变文本原有和信息系的情况下尽量减少要处理的单词数。以此降低空间维数,提高计算效率。特征项应该有独特性,能够与其他文本有区分能力:特征数不能太多,常用的方法有:
一般多用第一种方法, 简述如下: 词频(Term-Frequency,TF)是词语在文本中出现的频率,如果某一个词在一个文本中出现的越多,它的权重就越高。逆向文档频率(Inverse Dcumentation Frequency, IDF)是指在少数文本中出现的词的权值比在多数文本中出现的词的权重高,因为在聚类中这些词更具有区分能力。以下给出TF和IDF的计算公式:
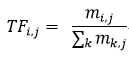 分子为第i个词条在第j个文档中出现的次数, 分母为所有词条在第j个文档中出现的次数之和
分子为第i个词条在第j个文档中出现的次数, 分母为所有词条在第j个文档中出现的次数之和
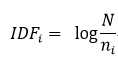 N表示全部的文档数,分母表示含有某词条i的文档树
N表示全部的文档数,分母表示含有某词条i的文档树
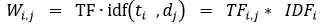 权重为TF与IDF的乘积。即为第i个词条在第j个文档中的权重
权重为TF与IDF的乘积。即为第i个词条在第j个文档中的权重
这个权重矩阵即为词汇-文本矩阵。它使得我们实现了文字到数字的向量化。通常机器学习中行数代表样本(文档),列数代表特征(词条)。所以通常对W进行转置。例如有1000个文档,300个词条,那么得到的是1000*300的权重矩阵。然后我们就可以通过这个矩阵来进行聚类:kmeans、k中心、层次聚类等等。
可以看到对于1000*300的矩阵来说,维度已经较高了,对于大量的文档来说维度太高,运算量大,噪声较多,所以可用PCA或SVD奇异值分解来降维。例如将1000*300降低至1000*200等等。具体实现也比较简单,不再赘述。
3.4 文本表示模型
这一小节其实在上一节实现了,即利用VSM方法得到了向量化的权重矩阵。为了处理文本,需要对其数字化。文本表示要求能真实准确反映文档内容,且对不同文档有区分能力。常用的方法有:
一般用向量模型,很好理解,想想一般的数据聚类方法都是将不同的数据向量化,然后通过计算向量之间的距离来判定其相似度。所以这里的VSM模型指:将每一个文本表示为向量空间的一个向量,并以每一个不同的特征项(词条)对应为向量空间的一个维度,而每一个维的值就是对应点特征项在文本中的权重,这里的权重由上文的TF-IDF算法得到。特征向量形式如下:
V(d) = (t1,w1(d) , t2,w2(d) ... ,tn,wn(d)) n为 n个词条,即n个特征 ti (i=1,2,...,n) 为文档d中的特征项,wi (i=1,2,...,n)为特征项得权值,可由TF-IDF算法得出。
注意这里的特征项代表词条,例如在所有得到的n=5个特征项(词条)为“ 坦克 军舰 自行车 篮球 公园 ” 。 那么对应于军事这一文档类别,通过TF-IDF算法可能得到的特征向量为 V = (0.86, 0.91, 0.15, 0.12, 0.09).即坦克、军舰占的权值更大。而对应于体育这一文档类别,显然篮球、自行车占比高些。
3.5 文本相似度计算
相似度用来衡量文本间相似程度的1一个标准。目前相似度计算方法分为距离度量和相似度度量。距离度量:计算样本在空间的距离,距离越远则差异性越大。而相似性度量中对绝对数值不敏感,更多是从方向上进行差异分析。
1)距离度量
2)相似度度量
3.6 主要聚类方法
常用的几种聚类方法和特点如下:
3.7 文本聚类质量评价
聚类评价的基本准则一般是簇内对象尽可能接近,簇间距离尽可能远离。目前聚类质量评价方法主要有:外在方法、内在方法和相对评价方法。
四. 具体实现
4.1 数据来源:搜狗实验室
数据属性:

图1 9个类别 图2 每个类别文件夹下有1990项txt 图3 txt文件内容
数据介绍: 这个数据集共有9个话题(类),分别对应:财经、IT、健康、体育、旅游、教育、招聘、文化、军事。每个类里有1990个txt文本。
4.2 python实现( 测试过程,数据量较小)
1)载入语料库
函数输入为含有文档文件夹的根目录root,输出为打印总文件夹数目(总类别数目)和打印总文件数(所有txt文件)、输出的allDirPath为所有文件的目录。
def PreprocessDoc(root): allDirPath = [] # 存放语料库数据集文件夹下面的文件夹路径,从allDirPath[1]开始 fileNumList = [] # 用来存放所有文件名 def processDirectory(args, dirname, filenames, fileNum=0): allDirPath.append(dirname) for filename in filenames: fileNum += 1 fileNumList.append(fileNum) os.path.walk(root, processDirectory, None) totalFileNum = sum(fileNumList) print ‘总文件夹(类别)数:‘ + str(len(allDirPath)-1) print ‘总文件数为: ‘ + str(totalFileNum) return allDirPath
以我的格式为例:我暂时取了5类,每类只取了15个文件。所以共有5个文件夹,每个文件夹下有15个txt:
所以 参数 root = ‘G:\wordstxt‘ 那么上面函数输出总文件夹数为5, 总文件数为5*15 = 75.所以总数据量为75.
2)删除停用词
函数输入为要进行处理的一个txt文件, stopWords为停词表, 输出为分好词,且过滤掉停用词的列表。
def DeleteStopWords(data, stopWords): #stopWords是你的停词表,即txt文件 ,data是你的txt文档 wordList = [] cutWords = jieba.cut(data) # 利用jieba对输入的文档进行分词操作 for item in cutWords: if item not in stopWords: # 检查分词结果中有没有哪些词在停词表里,不在的话则添加至新的列表 wordList.append(item) return wordList
对于我的来说: stopWords = open(‘G:\stopwords\stopwords_utf-8.txt‘, ‘r‘).read() 我的停词表名为:stopwords_utf-8.txt,见下图:
注意每次输入一个文档,输出都为一个列表,最终的处理将每一个txt文件作为一行,也即最终得到的txt为75行。
3)合成语料文档
输入:步骤1)中返回的所有文件的路径、待生成的语料文本、停词表
# 合成语料文档 def SaveDoc(allDirPath, docPath, stopWords): print ‘开始合成语料文档:‘ category = 0 # 文档的类别 f = open(docPath, ‘w‘) # 把所有的文本都集合在这个文档里 for dirParh in allDirPath[1:]: # 从第一个文件夹开始,因为第0个为根路径 for filePath in glob.glob(dirParh + ‘/*.txt‘): # 遍历该文件夹下的所有文件 data = open(filePath, ‘r‘).read() texts = DeleteStopWords(data, stopWords) # 调用了上面的函数 line = ‘‘ for word in texts: if word == u‘\u3000‘: # 是空格的话跳过continue line += word.encode(‘utf-8‘) line += ‘ ‘ # 词与词之间用空格隔开 f.write(line + ‘\n‘) # 把这行写进文件 category += 1 f.close() # 记得关闭 return 0
对于我的来说,docPath = ‘G:\docwords\docwords_utf-8.txt‘ ,即最终生成的语料文件为docwords_utf-8.txt
可以看到最终生成的文件中还有许多无意义的词汇,例如“面临、自己、好、刚刚”等词汇,这些词汇也应当加到停词表里。可以在网上搜集中文停词表,而我的停词表是自己用来测试的,不全面。
4) 利用TF-IDF算法得到权重矩阵
输入:上文生成的语料文件的路径,输出:生成的权重矩阵
def TFIDF(docPath):
corpus = [] # 文档语料 # 读取语料,一行语料为一个文档 lines = open(docPath, ‘r‘).readlines() for line in lines: corpus.append(line.strip()) # 去掉首尾空格 # 将文本中的词语转换成词频矩阵,矩阵元素 a[i][j] 表示j词在i类文本下的词频 vectorizer = CountVectorizer() # 该类会统计每个词语tfidf权值 transformer = TfidfTransformer() # 第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵 tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus)) # 获取词袋模型中的所有词语 word = vectorizer.get_feature_names() # 将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重 weight = tfidf.toarray() return weight
终于得到权重矩阵了,理论上可以直接进行聚类了,但是维度太高,下面进行降维。
5)PCA降维
输入:权重矩阵、降维后的维度。 输出:降维后的权重矩阵
def PCA(weight, dimension): from sklearn.decomposition import PCA print ‘原有维度: ‘, len(weight[0]) print ‘开始降维:‘ pca = PCA(n_components=dimension) # 初始化PCA X = pca.fit_transform(weight) # 返回降维后的数据 print ‘降维后维度: ‘, len(X[0]) print X return X
好了,将得到的权重矩阵存为txt里就可以利用博客里其他的聚类方法来进行聚类了。
np.savetxt("G:\weightswords\weights_words.txt", X)
总的代码:

1 # coding:utf-8 2 import logging 3 import time 4 import os 5 import codecs 6 import jieba 7 import glob 8 import numpy as np 9 import jieba.analyse 10 from sklearn import feature_extraction 11 from sklearn.feature_extraction.text import TfidfTransformer 12 from sklearn.feature_extraction.text import CountVectorizer 13 14 15 # 载入语料库 16 def PreprocessDoc(root): 17 allDirPath = [] # 存放语料库数据集文件夹下面的文件夹路径,从allDirPath[1]开始 18 fileNumList = [] # 用来存放所有文件名 19 20 def processDirectory(args, dirname, filenames, fileNum=0): 21 allDirPath.append(dirname) 22 for filename in filenames: 23 fileNum += 1 24 fileNumList.append(fileNum) 25 26 os.path.walk(root, processDirectory, None) 27 totalFileNum = sum(fileNumList) 28 print ‘总文件夹(类别)数:‘ + str(len(allDirPath)-1) 29 print ‘总文件数为: ‘ + str(totalFileNum) 30 31 return allDirPath 32 33 # 合成语料文档 34 def SaveDoc(allDirPath, docPath, stopWords): 35 print ‘开始合成语料文档:‘ 36 37 category = 0 # 文档的类别 38 f = open(docPath, ‘w‘) # 把所有的文本都集合在这个文档里 39 40 for dirParh in allDirPath[1:]: # 从第一个开始,因为第0个为根路径 41 42 for filePath in glob.glob(dirParh + ‘/*.txt‘): 43 44 data = open(filePath, ‘r‘).read() 45 texts = DeleteStopWords(data, stopWords) 46 line = ‘‘ # 把这些词缩成一行,第一个位置是文档类别,用空格分开 47 for word in texts: 48 if word == u‘\u3000‘ or word.encode(‘utf-8‘) == ‘nbsp‘ or word.encode(‘utf-8‘) == ‘\r\n‘: 49 continue 50 line += word.encode(‘utf-8‘) 51 line += ‘ ‘ 52 f.write(line + ‘\n‘) # 把这行写进文件 53 category += 1 # 扫完一个文件夹,类别+1 54 f.close() 55 56 return 0 # 生成文档,不用返回值 57 58 59 60 def DeleteStopWords(data, stopWords): 61 wordList = [] 62 63 # 先分一下词 64 cutWords = jieba.cut(data) 65 for item in cutWords: 66 if item not in stopWords: # 分词编码要和停用词编码一致 67 wordList.append(item) 68 69 return wordList 70 71 72 def TFIDF(docPath): 73 print ‘开始tfidf:‘ 74 75 corpus = [] # 文档语料 76 77 # 读取语料,一行语料为一个文档 78 lines = open(docPath, ‘r‘).readlines() 79 for line in lines: 80 corpus.append(line.strip()) # strip()前后空格都没了,但是中间空格还保留 81 82 # 将文本中的词语转换成词频矩阵,矩阵元素 a[i][j] 表示j词在i类文本下的词频 83 vectorizer = CountVectorizer() 84 85 # 该类会统计每个词语tfidf权值 86 transformer = TfidfTransformer() 87 88 # 第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵 89 tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus)) 90 91 # 获取词袋模型中的所有词语 92 word = vectorizer.get_feature_names() 93 94 # 将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重 95 weight = tfidf.toarray() 96 97 return weight 98 99 100 def PCA(weight, dimension): 101 from sklearn.decomposition import PCA 102 103 print ‘原有维度: ‘, len(weight[0]) 104 print ‘开始降维:‘ 105 106 pca = PCA(n_components=dimension) # 初始化PCA 107 X = pca.fit_transform(weight) # 返回降维后的数据 108 print ‘降维后维度: ‘, len(X[0]) 109 print X 110 111 return X 112 113 114 if __name__ == ‘__main__‘: 115 116 root = ‘G:\wordstxt‘ 117 stopWords = open(‘G:\stopwords\stopwords_utf-8.txt‘, ‘r‘).read() 118 docPath = ‘G:\docwords\docwords_utf-8.txt‘ 119 k = 3 120 121 122 allDirPath = PreprocessDoc(root) 123 SaveDoc(allDirPath, docPath, stopWords) 124 125 weight = TFIDF(docPath) #(75L, 8040L) 126 X = PCA(weight, dimension=200) # 将原始权重数据降维 127 128 np.savetxt("G:\weightswords\weights_words.txt", X)
6)评估
参见: 文本聚类教程
参考:
标签:规模 img app 预测 删除 span 影响 效率 通过
原文地址:http://www.cnblogs.com/king-lps/p/7788919.html
