标签:ber work 公司 cdata 匹配 parent jsoup 添加元素 span
XML基础知识
声明:
告诉别人我是一个xml文件 <?xml version="1.0" encoding="UTF-8" ?>
必须放在第一行
必须顶格写
元素 (标签):
格式:<xx></xx>和<xx/>
要求:
1.必须关闭
2.标签名不能 xml Xml XML 等等开头
3.标签名中不能出现空格或者":"等等特殊字符
属性:
格式:<xx 属性名="属性值"/>
要求:属性值必须引起来
注释:
和html一样<!---->
CDATA:
由于xml文件中的特殊字符必须需要转义,但是如果需要转义的地方很多,就比较麻烦,通过CDATA可以保证数据的原样输出
格式:
<![CDATA[
原样输出的内容
]]>
XML的解析技术
dom4j的使用步骤
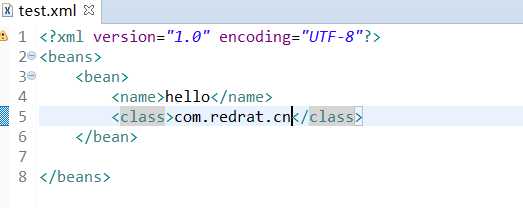
dom4j的使用示例
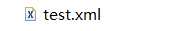
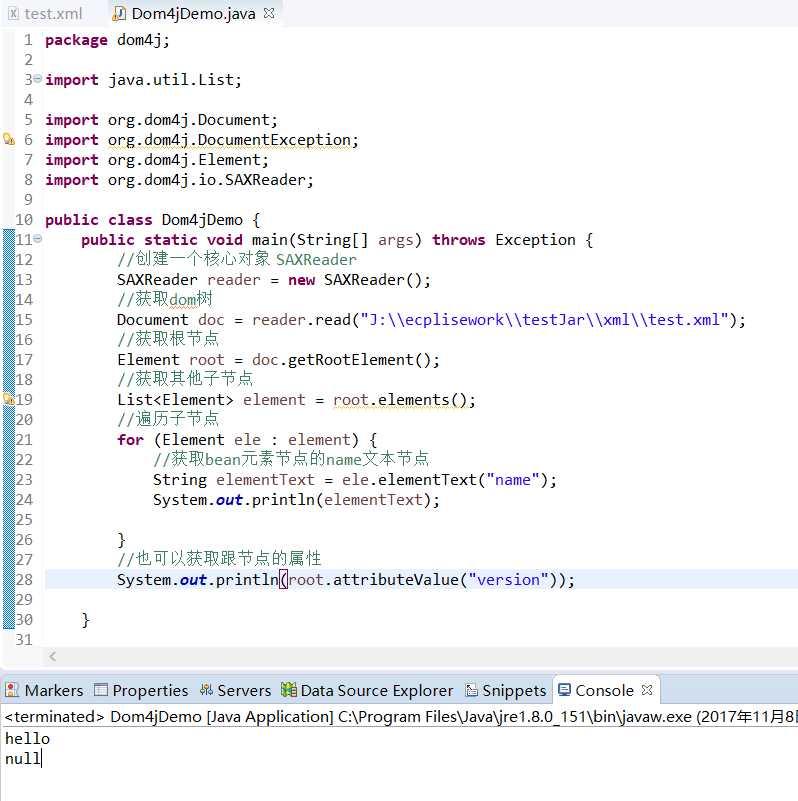
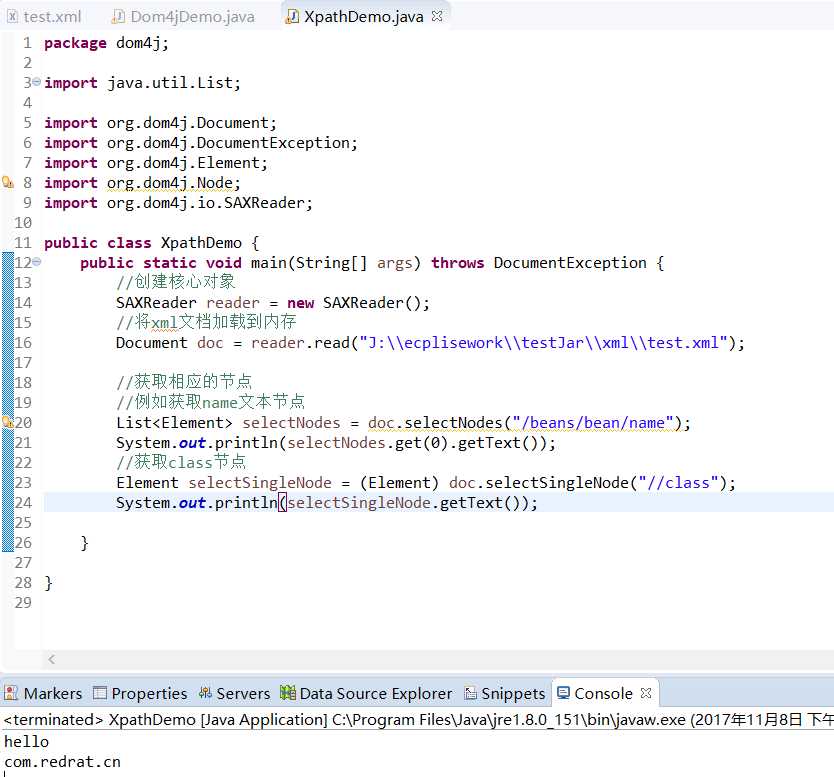
Xpath解析技术
使用api
selectNode("表达式");
selectSingleNode("表达式");
表达式的写法:
/ 从根节点选取
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
例如一个标签下有一个id属性且有值 id=2;
//元素名[@属性名=‘属性值‘]
//元素名[@id=‘2‘]
关于dom4j对xml文档的增删改查的方法
1 // 添加元素 2 @Test 3 public void method4() throws Exception { 4 // 得到Document 5 SAXReader reader = new SAXReader(); 6 Document doc = reader.read(new File("J:\\ecplisework\\testJar\\xml\\test.xml")); 7 8 // 获取root元素 9 Element root = doc.getRootElement(); 10 Element stuEle = root.addElement("student"); // 添加了student元素 11 // 给stuEle添加属性,名为number,值为1003 12 stuEle.addAttribute("number", "1003"); 13 // 分别为stuEle添加名为name、age、sex的子元素,并为子元素设置文本内容 14 stuEle.addElement("name").setText("wangWu"); 15 stuEle.addElement("age").setText("18"); 16 stuEle.addElement("sex").setText("male"); 17 18 // 设置保存的格式化器 1. \t,使用什么来完成缩进 2. true, 是否要添加换行 19 OutputFormat format = new OutputFormat("\t", true); 20 format.setTrimText(true); // 去掉空白 21 // 在创建Writer时,指定格式化器 22 XMLWriter writer = new XMLWriter(new FileOutputStream("J:\\ecplisework\\testJar\\xml\\test.xml"), format); 23 writer.write(doc); 24 }
1 // 修改元素 2 @Test 3 public void method5() throws Exception { 4 5 // 得到Document 6 SAXReader reader = new SAXReader(); 7 Document doc = reader.read(new File("J:\\ecplisework\\testJar\\xml\\test.xml")); 8 9 // 使用XPath找到符合条件的元素 10 // 查询student元素,条件是number属性的值为1003 11 Element stuEle = (Element) doc.selectSingleNode("//student[@number=‘1003‘]"); 12 // 修改stuEle的age子元素内容为81 13 stuEle.element("age").setText("81"); 14 // 修改stuEle的sex子元素的内容为female 15 stuEle.element("sex").setText("female"); 16 // 设置保存的格式化器 1. \t,使用什么来完成缩进 2. true, 是否要添加换行 17 OutputFormat format = new OutputFormat("\t", true); 18 format.setTrimText(true); // 去掉空白 19 // 在创建Writer时,指定格式化器 20 XMLWriter writer = new XMLWriter(new FileOutputStream("J:\\ecplisework\\testJar\\xml\\test.xml"), format); 21 writer.write(doc); 22 23 }
1 // 删除元素 2 @Test 3 public void method6() throws Exception { 4 5 // 得到Document 6 SAXReader reader = new SAXReader(); 7 Document doc = reader.read(new File("J:\\ecplisework\\testJar\\xml\\test.xml")); 8 9 // 查找student元素,条件是name子元素的文本内容为wangWu 10 Element stuEle = (Element) doc.selectSingleNode("//student[name=‘wangWu‘]"); 11 12 // 2. 获取父元素,使用父元素删除指定子元素 13 stuEle.getParent().remove(stuEle); 14 15 // 设置保存的格式化器 1. \t,使用什么来完成缩进 2. true, 是否要添加换行 16 OutputFormat format = new OutputFormat("\t", true); 17 format.setTrimText(true); // 去掉空白 18 // 在创建Writer时,指定格式化器 19 XMLWriter writer = new XMLWriter(new FileOutputStream("J:\\ecplisework\\testJar\\xml\\test.xml"), format); 20 writer.write(doc); 21 }
1 // 查找 2 @Test 3 public void method() throws Exception { 4 // 创建一个核心对象 SAXReader 5 SAXReader reader = new SAXReader(); 6 // 获取dom树 7 Document doc = reader.read("J:\\ecplisework\\testJar\\xml\\test.xml"); 8 // 获取根节点 9 Element root = doc.getRootElement(); 10 // 获取其他子节点 11 List<Element> element = root.elements(); 12 // 遍历子节点 13 for (Element ele : element) { 14 // 获取bean元素节点的name文本节点 15 String elementText = ele.elementText("name"); 16 System.out.println(elementText); 17 18 } 19 // 也可以获取跟节点的属性 20 System.out.println(root.attributeValue("version")); 21 }
DOM4J无论在那个方面都是非常出色的。如今越来越多的Java软件在使用DOM4J来读写XML,例如Hibernate,包括sun公司自己的JAXM也用了DOM4J。
标签:ber work 公司 cdata 匹配 parent jsoup 添加元素 span
原文地址:http://www.cnblogs.com/jimisun/p/7805081.html