标签:mib highlight 比较 weight amp 析取 功能 utils shp
基于solr版本:6.0.0
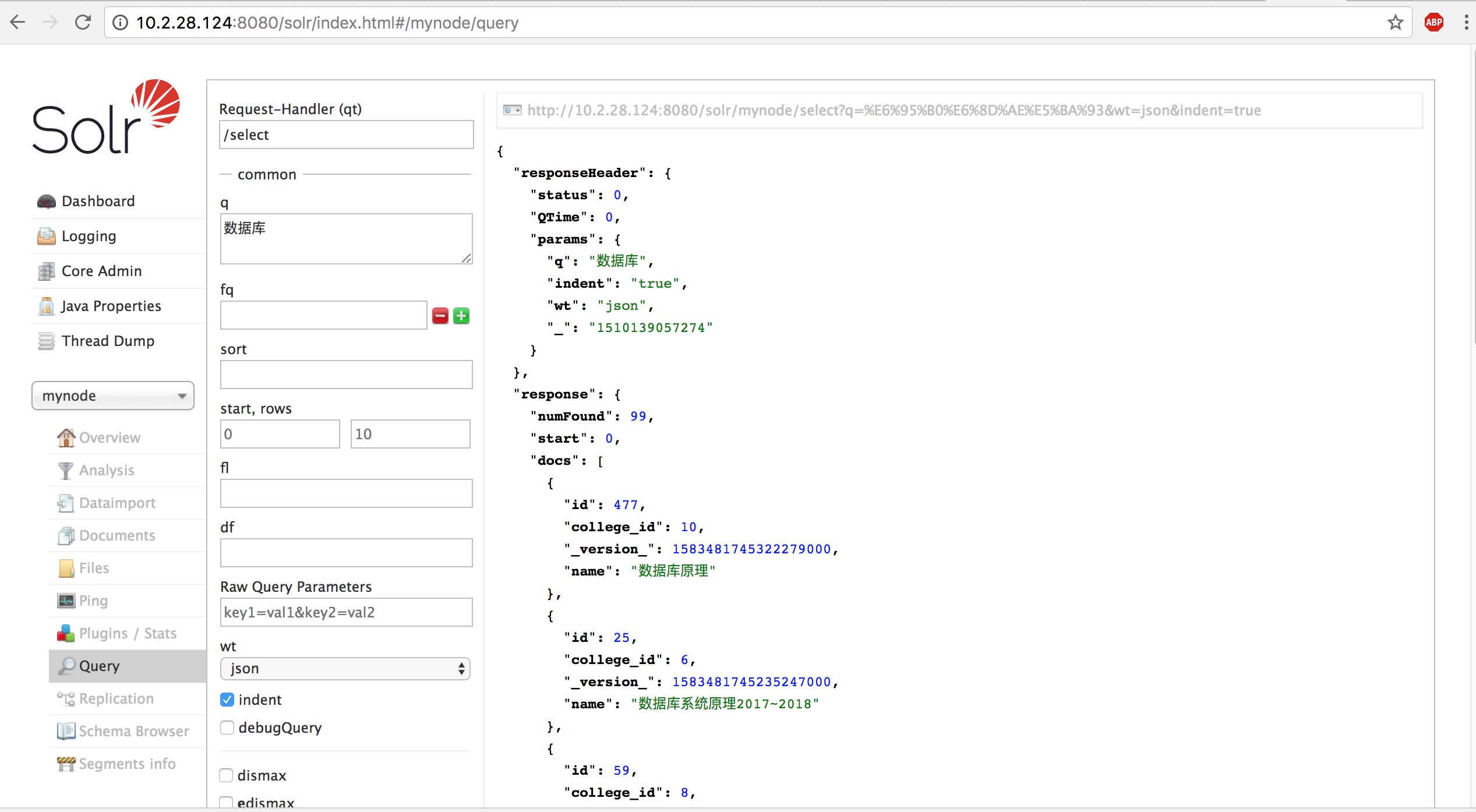
当配置好本地的环境之后,就访问http://localhost:8080/solr/index.html。或者是访问已经放在服务器上的solr环境,例如http://10.2.28.124:8080/solr/index.html,然后选择core(在我项目里目前只有一个node即mynode),进行查询。例如下图:
查询主要的如下面这张网络上的图:(来源:http://www.voidcn.com) 之后就其具体的一些参数我做一些解释与说明,主要介绍一些我用过的,因为Solr这个搜索引擎的功能很强大,还有很多功能我还没接触到,因此之后有机会补上更多的。

即搜索的关键词,唯一必填的选项。默认的是*:*, 代表显示全部内容。
区间搜索
排除词项
通配符搜索
权重表达式
软件工程^10。可以看到匹配度score立马变很高。
转义字符
转义字符加上\
fq即过滤条件。通常当我们需要一些附属一些搜索的条件时,需要用到此参数,可以有多个。
关闭缓存
fq={!cache false}id:99
默认情况下,solr会缓存查询结果,这样可以快速响应重复请求。在某些情况下,比如测试的时候,不希望solr缓存,参数cache=false可以禁用solr的缓存。
过滤顺序
添加执行成本,执行成本越低越先执行,成本大于等于100的过滤器被solr视为后置过滤器.需要注意的是,cost参数必须要cache=false,否则不生效。
fq={!cost=1}category:电器
fq={!cost=2}onsale:1
fq={!cost=100}star:[5 TO 9]
fq和q的区别主要在于fq不会影响搜索的匹配度score, q会影响。
一般我们不指定排序规则,这样的结果能满足大部分需求,默认是用文档的得分作为排序标准。相当于加上了参数sort=score desc,这里的score是solr的一个隐藏字段,衡量这个文档对于该查询参数的权重。使用如下的HTTP查询请求: http://localhost:8080/solr/core/select?q=*:*&fl=*,score
按某一filed排序
有时候,我们只关心某一字段,希望返回的数据根据这一字段排序。例如,我想查找名字叫软件工程的课程,并按照系号进行排序。可以使用查询参数sort=college_id asc,使用如下的HTTP查询请求: ?http://10.2.28.124:8080/solr/mynode/select?q=%E8%BD%AF%E4%BB%B6%E5%B7%A5%E7%A8%8B&rows=100&fl=*&wt=json&indent=true&sort=college_id asc
按多个filed排序
有时候,我希望返回的数据先按权重排序,再按某一filed排序,那么可以使用多个field来排序,此时按第一个排序参数排序,如果第一个参数不能区分顺序,则按第二个参数排序。对于某次查询,我希望先按系号从小到大排序,系号相同则按id降序,那么,查询参数可以为sort=college_id asc, id desc.
含有函数的排序
有时候,排序规则可能需要两个filed的值做数学运算。比如,有一次排序基于两个字段的乘积,可以使用这样的查询参数sort=mul(x_d, y_d) desc(这里的x字段和y字段都为double类型)。
分页开始索引,每页条数。
默认是start=0, row=10. 即从第一项开始,展示10项作为一页。
即返回哪些字段列表。例如显示id和name, fl=id,name. 如果是*就是显示所有,此时再加上score(score是solr自己求的一个字段) 就是fl=*,score.
响应格式
wt=json,Web项目常用格式。如果仅仅是自己查看,用csv比较直观。还可以返回Python、PHP、ruby具体的数据,除此之外还有xml格式。
debugQuery:调试模式
dismax:析取最大化查询解析器
edismax:扩展析取最大化查询解析器
hl(highlight):高亮
facet:分面查询
spatial:空间查询
spellcheck:拼写检查
group:分组查询
标签:mib highlight 比较 weight amp 析取 功能 utils shp
原文地址:http://www.cnblogs.com/ohazyi/p/7807722.html