标签:项目 新一代 避免 .com 链接 洛杉矶 lan key ica
今年以来,内存条价格暴涨,已经跃升为新的新一代理财产品,所以今天就和大家讨论一下内存的话题,主要内容就是在程序运行过程中,内存的作用以及如何与CPU,OS交互。
我们先来讨论:计算机的运行究竟是在做什么?来看一下经典的冯诺依曼结构。计算机科学虽然飞速发展了几十年,但是依旧遵循冯诺依曼结构。
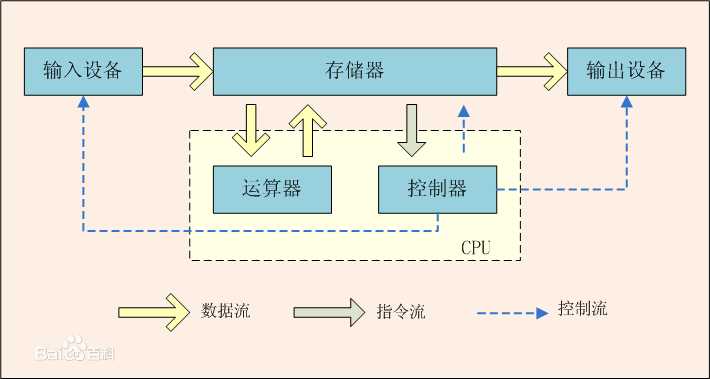
图1:冯诺依曼结构
数学家冯诺依曼提出的 体系结构包含以下几个要点:
- 把程序本身当作数据来对待,程序和该程序处理的数据用同样的方式储存。
- 计算机的数制采用二进制。
- 计算机应该按照程序顺序执行。
我们根据这张图进行思考就可以得到一个结论,所谓计算机处理任务,就是根据输入内容,数据/程序从存储器送往CPU进行处理,然后再将结果输出。
关于程序与数据,数据就是一首MP3歌曲, 程序就是用来控制解析播放这首歌的代码,从底层来讲就是供CPU运行的指令.总之在计算机当中它们都是0和1,不过为行文方便,我们直接简称为数据或程序或指令, 将它们理解为同一个意思,毕竟它们都属于0和1组成的流,这个可以根据上下文来理解。
本文讨论的主要内容,就是 存储器部分,为什么计算机需要存储器部分?这是显而易见的,我写好了程序,或者下载了一部电影,肯定得有个地方放啊。这样今后需要的时候,才能运行程序或者看电影啊。
我们思考一下,这个存储器应该具备什么样的特点。
关于这个存储器,我们大概想出了一个理想的存储器应该具备的的5个特点。
但是有句话说的好。理想很丰满,显示很骨感。一个屌丝在纸上列出了几十条他理想女友的标准,但是他能如愿吗?
先说结论,完全满足我们理想条件的存储器目前还没发明出来呢。目前的半导体工业只能造出部分符合条件的存储器,但是完全满足以上几条标准的,对不起,未来也许能做到,但是起码目前做不到。
所以这也是目前计算机系统存储器系统比较复杂的原因,区分为内存,硬盘,光盘等不同的存储器,如果有个完美的符合我们理想条件的存储器,直接使用这种存储器就好了。
先看看看我们最常见的存储设备:磁盘。足够稳定;有电没电都正常存储;容量也较大;价格也可以接受,所以磁盘是我们最常见的存储设备。
磁盘就是我们存储器的代表了。
为了行文方便,文中直接将存储器用磁盘来代替了,一来大家对磁盘比较熟悉,二来磁盘也是最常见的存储设备。类似flash,SD卡,ROM等从广义上来讲,也可以称为磁盘。因为它们的作用都是存储数据,掉电后不丢失。(这在下面文章中也会讨论到)
磁盘和硬盘什么关系呢?其实是同一个意思。硬盘是最常见的磁盘类型。在很早之前,计算机使用软盘存储数据,所以那种软盘也被称为 磁盘,不过软盘都早就被历史淘汰了,(电脑硬盘分区从C盘开始,就是因为AB盘是之前软盘的编号)。所以现在我们说磁盘,直接理解成硬盘就好了。
在我们软件当中,有个概念叫做数据持久化,意思就是说将数据存储起来,掉电之后不丢失,这其实就是存储在磁盘上面。
所以现在我们理解的计算机运行就是这样一个过程:将数据从磁盘送往CPU,供CPU进行计算,并将结果输出。
因为我们这片文章就是 讨论 内存,存储等问题,所以关于 输入设备,输出设备之类的,就不再涉及和讨论。
然后我们再简短来讨论CPU的发展历史。
世界上第一台计算机是1946年在美国诞生的ENIAC,当时CPU还是使用笨重的电子管,后面的故事依次是贝尔实验室发明了晶体管,TI的工程师又发明了集成晶体管,IBM研发成功首款使用集成电路的计算机,IBM360, 后面 就是仙童八叛徒与intel,AMD的故事了。这段很著名的IT故事,我们不再累述了。伴随着世界上第一款商用处理器:Intel4004的出现,波澜壮阔的摩尔定律开始了。
当时负责IBM 360 操作系统开发的那个项目经理,根据该项目经验, 写了一本经典著作《人月神话》,也有其他参与者根据该项目经验,立传出书了,所以当时那批人都是大牛。
摩尔定律:当价格不变时,集成电路上可容纳的元器件的数目,约每隔18-24个月便会增加一倍,性能也将提升一倍。
半导体行业开始腾飞了。CPU上集成的晶体管数量越来越多。 intel i9的制程工艺已经到了14nm。所以CPU的执行速度也越来越快。
当然,摩尔定律也快到尽头了,根据量子力学,2nm是理论极限值。线宽不能再细了,低于2nm,隧穿效应就会产生干扰。
闲扯了一段CPU的发展历史,想说明的是,现在的CPU集成度越来越高,速度也越来越快。每秒钟能执行的指令也越来越多。(如果不知道指令,汇编之类的啥意思,看一下我的的另一篇文章关于跨平台的一些认识,否则下面的内容看着也有难度)。
CPU的作用就是去执行指令(当然,也包括输出结果等,本文只讨论和存储器相关,所以不扯其他的),并且尽可能的以它的极限最高速度去执行指令,至于具体的执行过程,做过单片机或者学过微机原理的应该比较清楚。就是伴随着时钟周期滴滴答答的节奏,CPU踏着拍子来执行指令。
至于CPU的指令集,那就是Intel的架构师们的工作,总之,CPU认识这些指令,并且能执行运算。(别忘记了冯诺依曼体系结构那张图)。对于这些指令,但是CPU采取了各种措施来加快执行过程(也可以理解为加快它的计算速度)。比如有以下几种常见的措施:
- 流水线(pipeline)技术:有电子厂打工经历的读者肯定很熟悉这个流水线模式。CPU的流水线工作方式和工业生产上的流水线概念一样。就是将一个指令的执行过程也分解为多个步骤,CPU中的每个电路只执行其中一个步骤,这样前赴后继加快执行速度。CPU中多个不同功能的电路单元组成一条指令处理流水线,然后将一条指令分成几个步骤后再由这些电路单元分别执行。在执行过程中,指令源源不断的送往CPU。让每个电路单元都不闲着,这样就大大的加快了执行速度。
- 超线程(Hyper-Threading)技术:对于超线程,百度百科的解释我都没看懂,但是大概原理就是这样的。CPU在进行线程切换的时候,要执行 切换各种寄存器状态等一些操作。把第一个线程的各种寄存器状态写回缓存中保存,然后把第二个线程的相关内容送到各种寄存器上。该过程必不可少,否则待会再将第一个线程切换回来时,不知道该线程的各个状态, 那还怎么接着继续执行呢?也正因为如此,所以这个过程比较慢,大概需要几万个时钟周期。所以后来做了这样的设计,把每个寄存器等都多做一个,就是多做一组寄存器(也包括一些其他相关电路等),,CPU在执行A线程时,使用的第一组寄存器,切换到B线程,直接使用第二组寄存器,然后再切换A线程时,再使用第一组寄存器。,CPU就不用再傻傻的等着寄存器值的切换,线程切换只需要几个时钟周期就够了。对于普通的执行多任务的计算机,CPU线程切换是个非常频繁的操作,所以使用该技术就会节省大量的时钟周期。也就是相当于加快了CPU的执行速度。这就是CPU宣传参数中所谓的四核八线程的由来,其实就是超线程技术。(每个核多做一组寄存器等电路固然会占用宝贵的空间,但是它带来的优点远远大于缺点)。
- 超标量技术:CPU可以在每个时钟周期内执行多个操作,可以实行指令的并行运算。
- 乱序执行: 我们认为程序都是顺序执行的。但是在CPU层面上,指令的执行顺序并不一定与它们在机器级程序(汇编)中的顺序一样。比如
a = b+c; d++;这两个语句 不按照顺序执行也不会影响最终结果。当然这只是在CPU执行指令的层面,在程序员们看来,依旧认为程序是顺序执行的。
前面扯了那么多,就是为了说明CPU的执行速度很快。虽然每条指令的执行时间需要几个时钟周期到几十个时钟周期不等。但是CPU采用了种种技术来加快执行过程。所以平均执行一条指令只需要一个周期。而现在CPU主频都那么高。比如i7 7700K主频达到了 4.2G。这也就意味着,每个core每秒钟大约可以执行4.2亿条指令。那四个core呢?
我们讨论完CPU如此快的执行速度,我们再来说我们常见的存储设备-机械硬盘。

图2:机械硬盘结构
机械硬盘的结构就不再具体的讨论了。它让我想起了民国电影中那种播放音乐的唱片机。
带机械硬盘的电脑,在使用过程中,如果机箱被摔了,可能后果很严重,就是因为可能会把机械硬盘的那个读写头/传动臂等机械结构摔坏。
机械硬盘容量很大(目前普遍1T,2T),我们的数据和程序是存储在磁盘上的,所以CPU要想执行指令/数据,就要从存储器,也就是磁盘上读取, CPU一秒钟可以执行几亿条指令,但是相对之下,磁盘的读写速度就是慢如蜗牛。假设磁盘一秒钟可以读取100条指令。那么这中间就存在 巨大的速度差异。半导体行业发展了几十年,CPU的执行速度一再飞速提升,奈何磁盘技术发展的太不给力了,CPU再快,可是磁盘严重拖后腿,那CPU就相当于工作严重不饱和,如果直接从磁盘上 来读取数据,那么CPU相当于 99.9999%的时间都在闲置着。
"假设磁盘一秒钟可以读取100条指令。":带有假设字样的,具体数字都是随便写的。比如 磁盘读写速度自然有它的参数指标,不过我们只是为了说明问题, 所以能理解其中的道理就好。
磁盘厂商们也在努力研究,比如SSD(固态硬盘),它的速度就比 机械硬盘快了一二十倍吧。但是对于CPU的速度,这也是然并卵啊。(更何况SSD相比机械硬盘太贵了)
所以这就是个大问题。
这就像是老板对我们这些员工的希望一样。老板给我们发工资, 那么他就是希望我们每一天的每一分每一秒都在努力帮公司干活。不要有什么任何时间闲着。所以我们要感谢劳动法,让我们每天工作八小时就够了。毕竟我们也是血肉之躯,也需要吃喝拉撒睡觉。
看到劳动法说每天工作八小时就够了,程序猿们哭晕在厕所。
程序猿问科比:“你为什么这么成功? ”
科比:“你知道洛杉矶凌晨四点是什么样子吗? ”
程序猿:“不知道,一般那个时候我还没下班呢,怎么了?”
科比:“额…….”
通过上面的介绍,我们就明白了计算机体系的主要矛盾,CPU太快了,而磁盘太慢了。所以它俩是不能够直接通信的,我们可以加一层过度。这就是内存的作用。这就是几百块钱一根的内存条的作用和功能。
实际上,一般情况下,内存的读写速度比磁盘快几十万倍左右。所以它终于够资格和CPU直接通信了。
这里有张图,我们来看一下磁盘/内存,与CPU速度之间逐渐增大的差距(主要是CPU技术发展太迅猛了)。
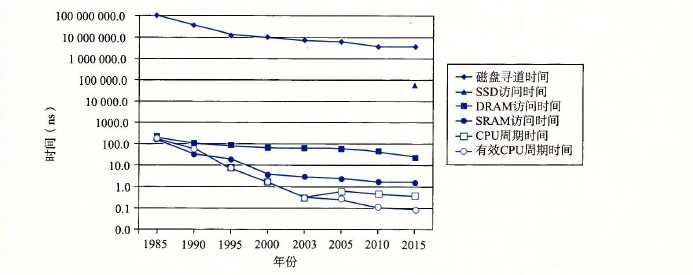
图三:磁盘DRAM和cpu速度之间逐渐增大的差距
所以现在程序执行过程是这样的。CPU执行任务时,只与内存通信,它从内存获取指令/数据或写回数据。内存再与磁盘通信,内存从磁盘读取数据/指令,或者内存将数据写回磁盘。
提到添加过渡层。这其实和JVM的原理都是类似的。具体可参考我的另一篇文章关于跨平台的一些认识。也许这就是大道至简吧。
我们这里说的内存,主要是指主存。就是主板上插的内存条。它的读写速度比磁盘快了几十万倍。但是相对于CPU的速度依旧还是慢。那么主存和CPU之间,可以继续添加速度更快的过度层。所以intel i7的存储器层次结构是这样的。
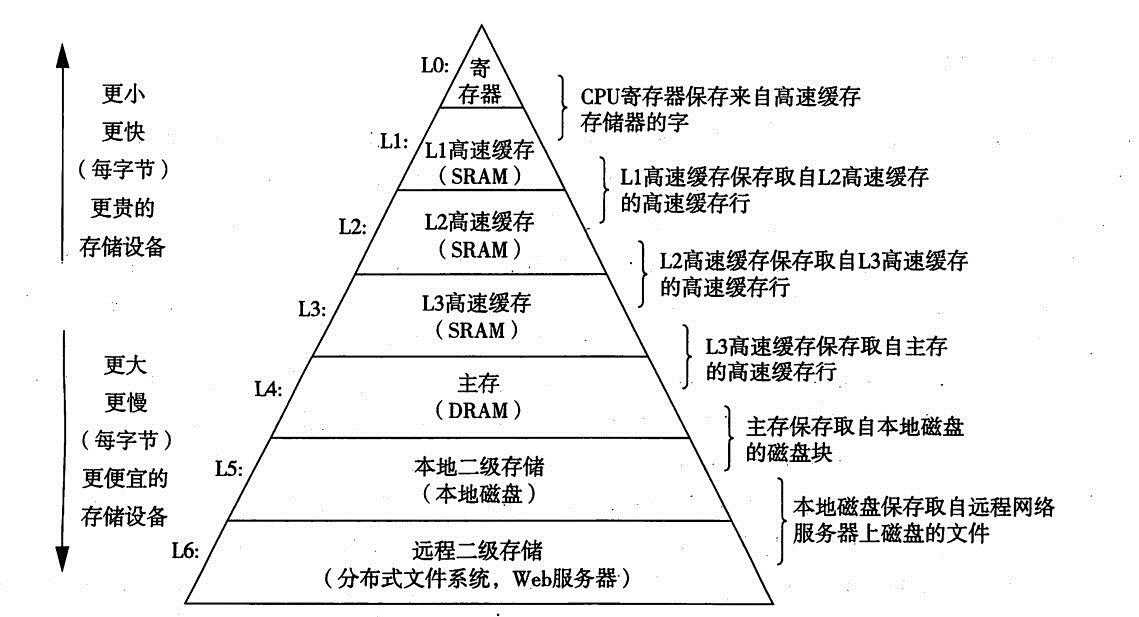
图4:一个存储器层次结构的示例
前面扯了那么多篇幅,就是告诉你,我们为什么需要内存(主存),那么理解了主存,自然也就理解了L3,L2,L1等各级缓存存在的意义。对于现代的计算机系统,在CPU与磁盘/主存之间,加了多层过度层。
严格来讲,应该叫CPU的算术逻辑单元(ALU),但是简单的直接说CPU,大家肯定也能听得懂。
实际上这是一种缓存思想。比如,本地磁盘也相当于 远方服务器的缓存。因为我们从网上下载数据/文件时,速度明显比从本地磁盘读取要慢。
一般情况下,L5磁盘与L4主存速度相差几十万倍, 而L3-L0之间,它们每级缓存的速度差异大概是10倍。
我们是拿i7处理器来做例子,它有三级缓存,像低端一些的处理器,比如i3,只有两级缓存,但是道理是相同的。本文当中,都是拿i7的存储器层次来做例子。
明白一点。CPU执行速度实在太快了,一秒钟执行几亿/十几亿条指令,CPU干活干脆利落,那么存储器就要想方设法的用最快的速度把指令/数据 送给CPU去运行。否则CPU干活再快,又有什么意义呢。
基本思想已经理解了。那么我们就开始具体讨论细节问题。
看看上面那幅图,什么SRAM,DRAM,还有我们前面讲的SSD,Flash,机械硬盘等,还有下面要讨论的总线(BUS),所以我们先来讨论一些基础硬件知识.
首先,他们都属于存储器,存储器分为两类:
ROM相比于RAM,容量更大,价格便宜,读写速度则比较慢。
其实我觉的把 Flash,ROM等都叫做磁盘,也没什么错。毕竟它们的作用和概念都是相似的,区别只是他们各自使用的半导体技术不同。Flash芯片等基于集成芯片的存储器读写速度比机械硬盘快,不过(相同容量下)价格也比后者贵。而它们相比于SRAM,DRAM则非常慢了,所以后者理解为内存即可。
"图4:一个存储器层次结构的示例",越往上,读写速度越快,价格更贵,存储容量也越小。(淘宝上搜搜8G的内存条,256G的SSD,1T的机械硬盘都是什么价格就明白了)。像L0 寄存器,每个寄存器只能存储一个字长的内容,但是CPU读写取寄存器耗费的时钟周期为0个。这是最快的速度。
另外,我们在电脑主板上可以看到内存条(L4主存)。硬盘(L5),但是却没看到L3-L0。原因很简单,他们都是集成在CPU芯片内部的。
我们知道了存储器的层级结构,下面还有一个问题,就是怎么把硬盘,内存条之类的连接起来进行通信呢,这就是 总线(Bus)了。
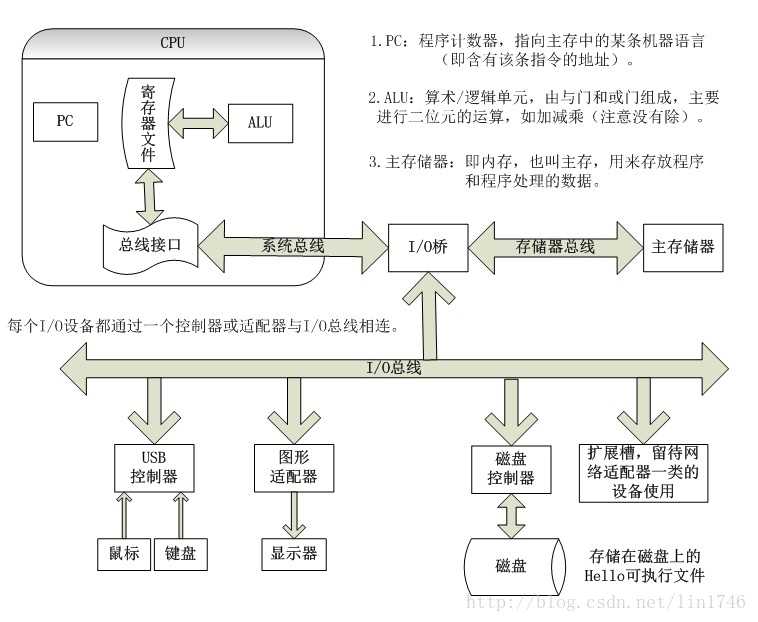
图6:一个典型系统的硬件组成
上图存在三条总线,IO总线,存储器总线(通常称为内存总线),系统总线。在主板上,就是那一排排的32/64根并行的导线。这些导线用来连接CPU,内存,硬盘,以其他外围设备。CPU与存储器,输入输出设备等通信,都是通过总线。不同总线的速度也有差异。
CPU要通过I/O桥(就是主板的北桥/南桥芯片组)与外围设备连接,因为CPU的主频太高了,它的时钟周期一秒钟震荡几亿次,外围设备的时钟周期都较慢,所以他们不能直接通信。
本文是讨论软件的,所以硬件部分就一笔带过,读者知道有这回事就ok了。总线上携带地址,数据和控制信号, 如何区分不同信号,分辨它与哪个外围设备通信,这就是另外一个问题了。
有些读者脑子转的比较快,可能想到了这样一个问题。
不管你中间怎么加缓存,也不管中间的什么SRAM,DRAM的读写速度有多快,但是磁盘的读写速度就是那么慢,所以磁盘与主存之间的交互速度很慢。CPU归根到底需要向磁盘读写数据。整个环节速度瓶颈就是在磁盘那里,这个根本快不了,那么加那么多级缓存,意义有何在呢?
这是一个好问题啊。 下面让我们继续讨论。
我们来看看,CPU如何读取磁盘中的一个数据。
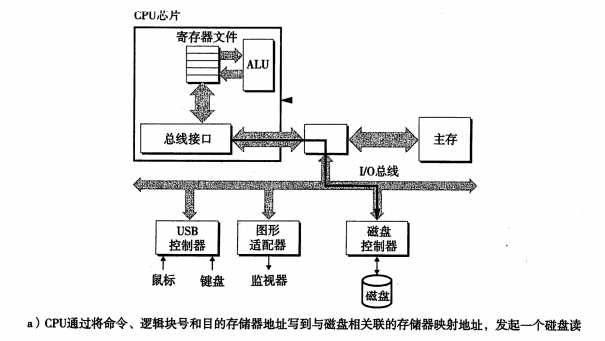
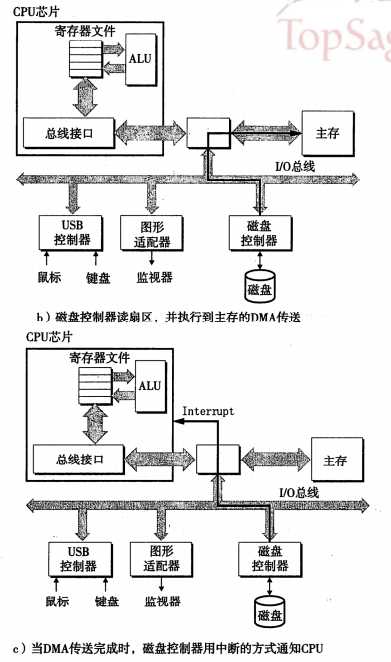
图7:读一个磁盘扇区
网上找的图片不是很清楚,注意每张图中的黑线。步骤分三部:
- CPU 将相关的命令和地址,通过系统总线和IO总线传递给磁盘,发起一个磁盘读。
- 磁盘控制器将相关的地址解析,并通过IO总线与内存总线将数据传给内存。
- 第2步完成之后,磁盘控制器向CPU发送一个中断信号。(学电子的同学应该很清楚中断是什么)。这时CPU就知道了,数据已经发送到内存了。
第二步磁盘操作很慢,但是在第一步CPU发出信号后。但是第二步和第三部时,CPU根本不参与。第二步很耗时,所以CPU在第一步发出信号后,就去在干其他事情啊。(切换到另一个线程)。所以此时的CPU依旧没有闲着。而待第三步时,通过中断,硬盘主动发信号给CPU,你需要的数据已经发送到内存了,然后此时它可以将线程再切换回来,接着执行这个该线程的任务。
除了多线程切换,避免CPU闲置浪费,还有一点。
我先问一个问题。
//@author :www.yaoxiaowen.com
int main(){
//我们执行任务的代码
return 0;
}对于一个应用/进程而言,它都应该有一个入口。(虽然不一定需要我们直接写main函数)。入口函数内部就是我们的任务代码,任务代码执行完了这个应用/进程也就结束了。这个很好理解,比如测试工程师写的一个测试case。跑完了这个任务就结束了。
但是 有些程序,比如一个 app,你打开了这个app。不做任何操作。这个界面会一直存在,也不会消失。思考一下这是为什么。因为这个app进程肯定也要有一个main入口。 main里面的任务代码执行完了,就应该结束了。而一个程序的代码/指令数目肯定是有限的。但该app在我们不主动退出情况下,却不会主动结束。
所以这个app进程的入口main来讲,其实是这样的。
//@author :www.yaoxiaowen.com
int main(){
boolean flag = true;
while (flag){
//我们执行任务的代码
}
return 0;
}并且不仅如此,在一个程序内部,也有大量的for,while等循环语句。
那么当我们把这些相关的代码指令送到了主存,或者更高一级的缓存时,那么CPU在执行这些指令时,存取速度自然快了很多。
在执行一个程序时,启动阶段比较慢,因为需要从磁盘读取数据。(而CPU在这个阶段也没闲置浪费,它会进行线程切换执行其他任务)。 但是数据被送往内存之后,它执行起来就会快多了,并且伴随着执行过程,还可能越来越快,因为这些数据,有可能被一级一级的向上送,从L4,送到L3,再送到L2,L1
so,上述那个问题的答案,已经解释的比较清楚了吧。
locality对于硬件和软件系统的设计和性能都有着重要的影响。对于我们理解存储器的层次结构也必不可缺。
程序倾向于引用临近于与其他最近引用过的数据项的数据项。或者最近引用过的数据项本身。这种倾向性,我们称之为局部性原理。它通常有以下两种形式:
- 时间局部性(temporal locality):被引用过一次的存储器位置的内容在未来会被多次引用。
- 空间局部性(spatial locality):如果一个存储器位置的内容被引用,那么它附近的位置也很大概率会被引用。
一般而言,有良好局部性的程序比局部性差的程序运行的更快。 现代计算机系统的各个层次,从硬件到操作系统、再到应用程序,它们的设计都利用了局部性。
当然,光说理论的东西比较玄乎。我们来看实际的例子。
//@author www.yaoxiaowen.com
int sum1(int array[N])
{
int i, sum = 0;
for(i = 0; i < N; i++)
sum += array[i];
return sum;
}在这个程序中,变量sum,i在每次循环迭代时被引用一次,因此对sum和i来说,有较好的时间局部性。
对变量array来说,它是一个int类型数组,循环时按顺序访问array,因为一个C数组在内存中是占用连续的内存空间。因而的较好的空间局部性,
再来看一个例子:
//@author www.yaoxiaowen.com
int sum2(int array[M][N])
{
int i, j, sum = 0;
for(i = 0; i < M; i++){
for(j = 0; j < N; j++)
sum += array[j][i];
}
return sum;
}这是一个空间局部性很差的程序。
假设这个数组是array[3][4],因为C数组在内存中是按行顺序来存放的。所以sum2对每个数组元素的访问顺序成了这样:0, 4, 8, 1, 5, 9…… 7, 11。所以它的空间局部性很差。
但是幸运的是,一般情况下软件编程天然就是符合局部性原理的。比如程序的循环结构。
假设CPU需要读取一个值,int var,而var在L4主存上,那么该值会被依次向上送,L4->L3->L2,但是这个传递的过程并不是单纯的只传递var四个字节的内容,而是把var所在的内存块(block),依次向上传递,为什么要传递block?因为根据局部性原理,我们认为,与var值相邻的值,未来也会被引用。
存储器的层次结构,数据进行传送时,是以block(块)为单位传送的。在整个层次结构上,越往上,block越小而已。
洋洋洒洒的扯了那么多,我相对于所谓的 存储器层次结构读者应该有一个基本的认识,有些地方介绍的 不够严谨,但是本文的目的也就是让大家理解基本思想。
归根到底,它就是一个缓存(caching)的思想,并且其实不复杂,
我们做app开发时,对于app中活动页面等,都是后台发给我们图片url,我们下载后才显示在app上,这时我们总要使用
Glide,Picasso等图片缓存框架来把下载好的图片缓存在手机本地存储上。这样下次打开app时,如果这个图片链接没有改变,我们就直接拿手机本地缓存的图片来进行显示,而不用再从服务器上下载了。如果图片链接改变了,则重新下载。为什么要这么做?因为从服务器上下载比较慢,而手机本地存储(ROM)中读取就会快很多。
这个时候可以再回头看看"图4:一个存储器层次结构的示例"。
下面这张图和这段文字来自《深入理解计算机系统》(CSAPP),大家可以有个更严谨和细节的认识。
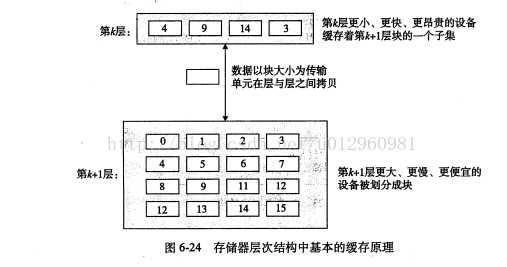
图8:存储器层次结构中基本的缓存原理
存储器层次结构的中心思想:位于k层的更快更小的存储设备作为位于k+1层得更大更慢的存储设备的缓存;数据总是以块大小为传送单元(transfer unit)在第k层和第k+1层之间来回拷贝的;任何一对相邻的层次之间传送的块大小是固定的,即每一级缓存的块大小是固定的。但是其它的层次对之间可以有不同的块大小。
当程序需要第k+1层的某个数据对象d时,它首先在当前存储在第k层的一个块中查找d。如果d刚好在k层,那么就是缓存命中。如果第k层中没有缓存数据对象d,那么就是缓存命不中。当缓存不命中发生时,第k层的缓存从第k+1层 缓存中取出包含d的那个块,如果第k层的缓存已经满了的话,可能会覆盖现存的一个块。(覆盖策略可以使用常见的LRU算法)。
volatile 关键字在java和C当中,有一个volatile关键字(其他语言估计也有),它的作用就是在多线程时保证变量的内存可见性,但是具体怎么理解呢?
我们在"图4:一个存储器层次结构的示例"中,说的缓存结构其实对于一个单核CPU而言的,比如 对于 一个四核三级缓存的CPU,它的缓存结构是这样的。
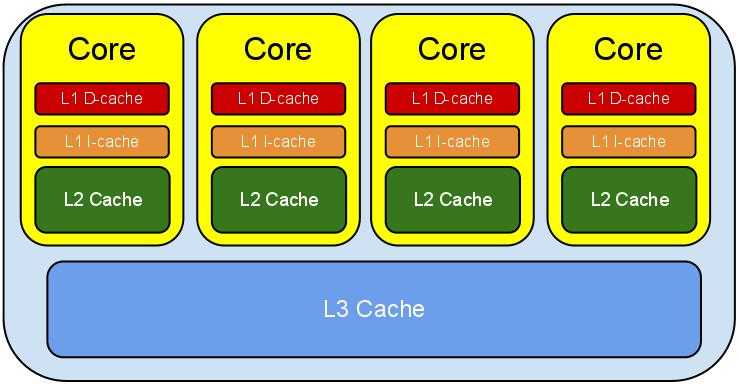
图9:多核处理器缓存结构
我们可以看到L3是四个核共有的,但是L2,L1其实是每个核私有的,如果我有一个变量var,它会被两个线程同时读取,这两个线程在两个核上并行执行,因为我们的缓存原理,这个var可能分别在两个核的 L2或L1缓存,这样读取速度最快,但是该var值可能就分别被这两个核分别修改成不同的值, 最后将值回写到L3或L4主存,此时就会发生bug了。
所以volatile关键字就是预防这种情况,对于被volatile修饰的的变量,每次CPU需要读取时,都至少要从L3读取,并且CPU计算结束后,也立刻回写到L3中,这样读写速度虽然减慢了一些,但是避免了该值在每个core的私有缓存中单独操作而其他核不知道。
本篇是"什么是内存"系列第一篇文章,下一篇文章会讨论关于内存的另一个重要方面,两篇文章加起来,相信大家会对内存有一个全面的,全新的认识。
这里请大家思考以下几个问题。
- 不管什么程序,最后的直接/间接的编译结果都是0和1,(我们直接理解为汇编)。(这点不知道的,欢迎阅读我的另一篇文章关于跨平台的一些认识),比如这句汇编代码:
mov eax,0x123456;它的意思是将内存0x123456处的内容送往eax这个寄存器。各个应用的数据共同存在内存中的。假设有一个音乐播放器应用的汇编代码中,引用了0x123456这个内存地址。但是同时运行的应用有很多,那其他应用也完全有可能引用0x123456这个地址。那为什么竟然没起冲突和错误呢?
- 进程是计算机领域最重要的概念之一,什么是进程?进程是关于某次数据集合的一次运行活动, 是运行在它自己地址空间的一段自包容程序, 解释的通俗的点, 一个程序在运行时,我们会得到一个假象,该进程好像是独占地使用CPU和内存,CPU是没有间断地一条接一条的执行该程序的指令,所有的内存空间都是供该进程的代码和数据分配使用的。(这点不严谨,其实内存还有一部分要分给
内核kernel)。说起来,这个程序就好像得到了全世界一样。,CPU是我的,内存也全部我的,妹子们还是我的。当然这是假象而已。但是这些假象又是怎么做到的呢?
- 程序中都会引用库API,比如每个C程序都要引用
stdio.h库的printf(),在程序运行时,库代码也要被加入到内存,这么多程序都引用了这个库,难道我内存中需要加很多份吗?这自然不可能,那么库代码又是怎么被所有进程共享的呢?
下篇文章将会给大家解释这些问题,并且这些问题的答案是非常简单的。相信大家看了会有恍然大悟的感觉,敬请期待。
标签:项目 新一代 避免 .com 链接 洛杉矶 lan key ica
原文地址:http://www.cnblogs.com/jmsjh/p/7811601.html