标签:mda 例子 好的 自己 为什么 忽略 质量 100% 方向
一、智能问答系统最大的价值在于为客服附能
现在普遍认为智能问答能够独立解决很多问题,但是必须要承认现在技术所处的初级阶段的性质。也就是说,智能问答系统在现阶段最大的
价值在于为客服人员附能,而并非独立于人自行解决众多目前还有巨大错误率和不确定性的问题。一旦具有这样的思想基础——通过智能问答系统为客
服人员附能,那么将智能问答系统做成一个工具和产品的基础就有了,只有通过产品化、工具化的方式,才能够实现这个预期。
二、局限性下的兜底策略
如今阶段下的智能问答系统是有局限性的,这也是为什么知识图谱和深度学习是需要落地到某个具体的垂直领域的原因。但即使在某个具体的垂直领域,
局限性依然广泛的存在,所以通过产品对机器问答系统做出兜底策略是一个重要的路径,这样能够最大程度的增加用户对系统的信心。比如对
于系统不知道的问题,可以及时转换其他的服务策略或者进行多轮问答。就如锤子手机的大爆炸产品,智能分词有的时候不是那么准确的,但是只要你
在不准确的情况下,提供一种便捷的方式,让用户告诉机器自己想进行的操作,那么系统的可用性就会大大提升,而这个成本相对于提升算法的性
能来说,要低的多,而且效果要好得多。这就是用产品的策略弥补机器算法本身的不足。
苏宁云商推出了小苏智能机器人,用户可以通过与小苏聊天来了解商品的具体信息,以及协助解决一些购物流程中存在的问题。但是更加值得注意的是,
小苏具备一定的拒识能力,它能够知道自己不能回答用户哪些问题,以便及时的调用其他的服务方式介入。所以可以看出,为了最大程度的降低这种局
限性,在产品方面做出了两个方面的努力,一是不断的熟悉和观察具体的使用场景,通过扩展和精细使用场景,为智能问答系统提供更多地解决方案;
二是兜底策略,对于自己不知道的问题和场景,智能问答系统能够调用其他的服务方式介入。
了解了兜底策略之后,实际上非常重要的一环是如何将兜底策略也做的更加智能,现在普遍的方式是直接介入人工客服,但是这绝对不是唯一的方式,
在不同的场景下也不见得是最有效的方式。比如语音问答系统进行实时监听的时候,会有如下几种场景:没有监测到声音或者没有听清楚、监听到了声
音但是识别错误、出现歧义或者有多个目标分析关键词、给出了用户不满意的答案或者干脆没有任何答案、由于某些服务暂时没有接入无法执行相应的动
作(比如因为手机上没有安装外卖APP,无法完成下单的操作)等等,这些不同的场景实际上都应该有不同的兜底策略。
考虑兜底策略,并且将兜底策略做的智能化,是在产品上非常重要的一个前进方向。
三、圈定在垂直领域下的确定性范围
这是对兜底策略的进一步思考。
首先我们想这样一个问题——为什么之前很火的语音备忘录产品现在很少人仍然在用?其实有这么几个原因:
1、纯音频数据不具有可视化性质,因此难于检索,难于判断内容质量的高低。
单纯的音频是不具备可视化性质的,也就是说在你具体去听一段音频之前,你是无法快速知道里面有哪些内容是重要的,是对你有用的,更无法根据关
键词进行搜索。在之前做音频类产品的时候就存在这个问题,对于纯音频化的数据,能够展现给用户的只有音轨,知道什么时间声音大,什么地方声音
小,但是你却不能提前知道这段音频实质内容的一点点额外信息。一旦一段音频的时间非常长,而你又不想去听那些垃圾信息,又无法进行搜索和定位
那么你能做就是放弃听这段音频,因为时间成本太高。
2、既然语音不具有可视化性质,无法进行检索,那么通过语音识别转化为文字再进行存储,会不会更好?
当然,这是一个很好的方案,因为一旦将音频转换为文字,那么就可以解决上面所说的问题,这是在产品上做的非常大的优化了。但是还是有一些不可
忽略的问题,就是语音识别不准确,语音识别不准确的后果是什么,用户就需要不断进行double check,就如老罗所说的那样,语音识别的准确性从
85%提升到90%,提升到95%这个变化不足以产生革命性的变革,但是如果有一天语音识别的准确性变成了100%,那就是一个质的飞跃,因为再也不
用double check了
我们分析语音备忘的相关问题是要得出这样一个结论,如果某个事物能够完成的任务是确定,是有清晰边界的,那么它就具有非常高的价值。而如果一个
事物的能力边界是不确定的,那么它的可信性就会大大降低,它的价值就会折损。因此智能问答系统在产品上的另一个方向是,在垂直领域圈定清晰的
边界,让用户知道智能问答系统在什么范围之内是绝对可信的,一旦系统达到了用户这样的心里预期,即使系统本身能够解决的问题非常局限,它也会
变得非常有用,就比如说一个能够为你查询和订购图书的智能问答系统,即便它的能力有限,但是如果它在这个范围内是可靠的,那么用户就会对它形
成依赖。
四、产品化流程上的自我增强机制
这一点是显而易见的,重点在于从产品流程的某些环节上为智能问答系统的计算核提供非监督性或者监督性的数据。
对于问答系统的知识图谱构建就是其中非常明显的一方面。现在知识图谱结构化数据的自动化构建技术实际上依然不成熟,所以很多垂直领域的知识
图谱的构建都是进行人工标注。另一方面,实际上每一次客服问答的数据都应该存入语料库,不断的扩大这个语料库,但是正如知识图谱所做的事,这
些数据只有结构化之后,只有进行标注之后,才会有更有价值。所以从产品的角度看,提供一套简易的人工标注界面给前线客服是有价值的。比如对于
每一次服务过程,客服人员都能够使用工具对客户身份、等级、问题类别、商品分类等等一系列的数据,在机器的协助下进行快速标注,并实时的存入
语料库中,那么就能够极大的提高效率,为智能问答系统不断地提供新的有效数据。我们都知道,在人工智能时代,谁拥有大数据谁就占据了制高点。
所以,这里面重要一环就是在理解计算核工作原理的基础上,提供协助机器变得更智能的产品解决方案,实现机器的智能增强。
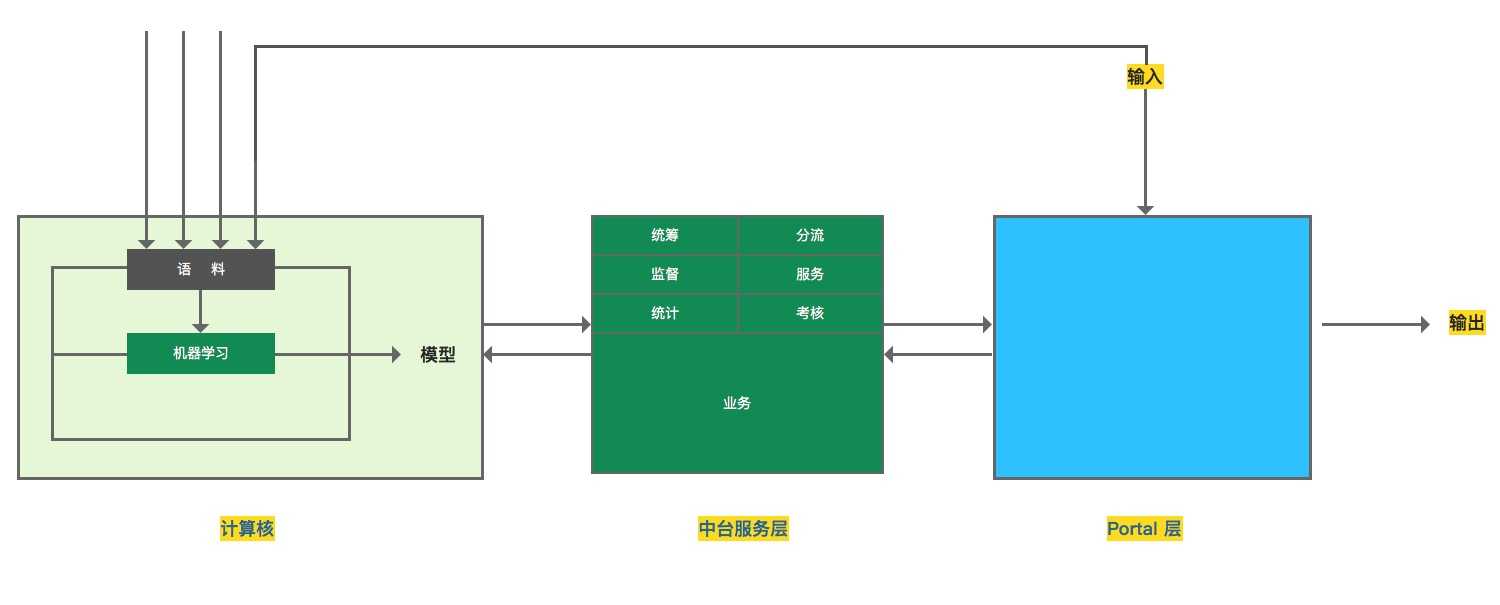
五、中台服务层的可扩展性
这一层是除了计算核之外非常重要的一层,也是智能问答系统的一个核心服务层。统筹、智能分流、数据统计、客服监督、客服考核在这一层,但是另
一种更加重要的服务是业务服务。所谓的业务服务就是将智能问答系统和自己的业务或者第三方业务服务打通。
对于商用问答系统,客户的问题中很大一类不仅仅是需要提供一些基本的反馈信息,往往最后一个环节是需要系统帮助他去完成某些动作,比如下单、
退款、退货等等,因此一个智能问答系统是否和公司业务打通是评价它是否有效率的一个非常重要的标准。
之所以提到这种服务的可扩展性,是最近对亚马逊Echo的关注,这款智能音箱不同于Google、微软等其他公司的产品,Google、微软的语音智能
产品提供的服务都是本公司自己的服务。但是Echo则不同,这款音箱一开始的定位就是做一个服务平台,提供类似于组件的接口和SDK,允许其他
的第三方服务集成进来。所以你不仅能够通过Echo完成买书的服务,还能够完成音乐、预定pizza这种服务。这种可扩展性是产品策略上关键的一环
六、用户主动提供数据的巨大价值
不论怎样,智能问答系统一个不可忽视的巨大价值在于,他收集的数据是用户自己透漏的数据,直接体现了用户自身的需求。
拿用户在网上购物来说,他从浏览产品到最终购买一件产品,这个链路的数据都可以被收集,但是机器是没有办法对这些数据的产生、对购买行为的
产生做出准确解释的。打个比方,我买了一件李宁的上衣,一连串的动作数据被记录了下来,但是机器却不知道,我为什么喜欢这件上衣,而不是其他
的上衣呢?是因为材质?因为颜色?因为图案?还是因为搭配?机器是无法给出准确回答的。
但是,如果我买了一件衣服,因为上面的图案不清晰,我通过客服要求退货,这个时候,其实我已经告诉客服,我很在意这个图案,而且这个信息是我
主动清晰的告诉客服的,这个信息的价值要高得多,反之如果你让机器去根据我之前的购买信息做大量的计算都不一定能够得到这个有价值的信息。
当然这个例子可能有不太准确的地方,但是要说明的是,问答系统收集到的数据是用户亲口透漏的数据,这种数据的价值要高得多!
标签:mda 例子 好的 自己 为什么 忽略 质量 100% 方向
原文地址:http://www.cnblogs.com/PengLee/p/7818644.html