标签:phone console migrate lin pass 匹配 正则匹配 保定 image
Django框架功能齐全自带数据库操作功能,本文主要介绍Django的ORM框架
到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞:
ORM是什么?:(在django中,根据代码中的类自动生成数据库的表也叫--code first)
ORM:Object Relational Mapping(关系对象映射)
类名对应------》数据库中的表名
类属性对应---------》数据库里的字段
类实例对应---------》数据库表里的一行数据
obj.id obj.name.....类实例对象的属性
Django orm的优势:
Django的orm操作本质上会根据对接的数据库引擎,翻译成对应的sql语句;所有使用Django开发的项目无需关心程序底层使用的是MySQL、Oracle、sqlite....,如果数据库迁移,只需要更换Django的数据库引擎即可;
1、创建数据库 (注意设置 数据的字符编码)
由于Django自带的orm是data_first类型的ORM,使用前必须先创建数据库
create database day70 default character set utf8 collate utf8_general_ci;
2、修改project中的settings.py文件中设置 连接 MySQL数据库(Django默认使用的是sqllite数据库)

DATABASES = { ‘default‘: { ‘ENGINE‘: ‘django.db.backends.mysql‘, ‘NAME‘:‘day70‘, ‘USER‘: ‘eric‘, ‘PASSWORD‘: ‘123123‘, ‘HOST‘: ‘192.168.182.128‘, ‘PORT‘: ‘3306‘, } }
扩展:查看orm操作执行的原生SQL语句
在project中的settings.py文件增加
LOGGING = { ‘version‘: 1, ‘disable_existing_loggers‘: False, ‘handlers‘: { ‘console‘:{ ‘level‘:‘DEBUG‘, ‘class‘:‘logging.StreamHandler‘, }, }, ‘loggers‘: { ‘django.db.backends‘: { ‘handlers‘: [‘console‘], ‘propagate‘: True, ‘level‘:‘DEBUG‘, }, } }
3、修改project 中的__init__py 文件设置 Django默认连接MySQL的方式
import pymysql pymysql.install_as_MySQLdb()
4、setings文件注册APP
INSTALLED_APPS = [ ‘django.contrib.admin‘, ‘django.contrib.auth‘, ‘django.contrib.contenttypes‘, ‘django.contrib.sessions‘, ‘django.contrib.messages‘, ‘django.contrib.staticfiles‘, ‘app01.apps.App01Config‘, ]
5、models.py创建表
6、进行数据迁移
6.1、在winds cmd或者Linux shell的项目的manage.py目录下执行
python manage.py makemigrations
python manage.py migrate
扩展:修改表之后常见报错

这个报错:因为表创建好之后,新增字段没有设置默认值,或者原来表中字段设置了不能为空参数,修改后的表结构和目前的数据冲突导致;
Djan提供了很多字段类型,比如URL/Email/IP/ 但是mysql数据没有这些类型,这类型存储到数据库上本质是字符串数据类型,其主要目的是为了封装底层SQL语句;
1、字符串类(以下都是在数据库中本质都是字符串数据类型,此类字段只是在Django自带的admin中生效)
name=models.CharField(max_length=32)
EmailField(CharField):
IPAddressField(Field)
URLField(CharField)
SlugField(CharField)
UUIDField(Field)
FilePathField(Field)
FileField(Field)
ImageField(FileField)
CommaSeparatedIntegerField(CharField)
扩展
models.CharField 对应的是MySQL的varchar数据类型
char 和 varchar的区别 :
char和varchar的共同点是存储数据的长度,不能 超过max_length限制,
不同点是varchar根据数据实际长度存储,char按指定max_length()存储数据;所有前者更节省硬盘空间;
2、时间字段
models.DateTimeField(null=True)
date=models.DateField()
3、数字字段
(max_digits=30,decimal_places=10)总长度30小数位 10位)
数字: num = models.IntegerField() num = models.FloatField() 浮点 price=models.DecimalField(max_digits=8,decimal_places=3) 精确浮点
4、枚举字段
choice=( (1,‘男人‘), (2,‘女人‘), (3,‘其他‘) ) lover=models.IntegerField(choices=choice) #枚举类型
扩展
在数据库存储枚举类型,比外键有什么优势?
1、无需连表查询性能低,省硬盘空间(选项不固定时用外键)
2、在modle文件里不能动态增加(选项一成不变用Django的choice)
其他字段
db_index = True 表示设置索引 unique(唯一的意思) = True 设置唯一索引 联合唯一索引 class Meta: unique_together = ( (‘email‘,‘ctime‘), ) 联合索引(不做限制) index_together = ( (‘email‘,‘ctime‘), )
ManyToManyField(RelatedField) #多对多操作
1.数据库级别生效

AutoField(Field) - int自增列,必须填入参数 primary_key=True BigAutoField(AutoField) - bigint自增列,必须填入参数 primary_key=True 注:当model中如果没有自增列,则自动会创建一个列名为id的列 from django.db import models class UserInfo(models.Model): # 自动创建一个列名为id的且为自增的整数列 username = models.CharField(max_length=32) class Group(models.Model): # 自定义自增列 nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) SmallIntegerField(IntegerField): - 小整数 -32768 ~ 32767 PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField) - 正小整数 0 ~ 32767 IntegerField(Field) - 整数列(有符号的) -2147483648 ~ 2147483647 PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField) - 正整数 0 ~ 2147483647 BigIntegerField(IntegerField): - 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807 自定义无符号整数字段 class UnsignedIntegerField(models.IntegerField): def db_type(self, connection): return ‘integer UNSIGNED‘ PS: 返回值为字段在数据库中的属性,Django字段默认的值为: ‘AutoField‘: ‘integer AUTO_INCREMENT‘, ‘BigAutoField‘: ‘bigint AUTO_INCREMENT‘, ‘BinaryField‘: ‘longblob‘, ‘BooleanField‘: ‘bool‘, ‘CharField‘: ‘varchar(%(max_length)s)‘, ‘CommaSeparatedIntegerField‘: ‘varchar(%(max_length)s)‘, ‘DateField‘: ‘date‘, ‘DateTimeField‘: ‘datetime‘, ‘DecimalField‘: ‘numeric(%(max_digits)s, %(decimal_places)s)‘, ‘DurationField‘: ‘bigint‘, ‘FileField‘: ‘varchar(%(max_length)s)‘, ‘FilePathField‘: ‘varchar(%(max_length)s)‘, ‘FloatField‘: ‘double precision‘, ‘IntegerField‘: ‘integer‘, ‘BigIntegerField‘: ‘bigint‘, ‘IPAddressField‘: ‘char(15)‘, ‘GenericIPAddressField‘: ‘char(39)‘, ‘NullBooleanField‘: ‘bool‘, ‘OneToOneField‘: ‘integer‘, ‘PositiveIntegerField‘: ‘integer UNSIGNED‘, ‘PositiveSmallIntegerField‘: ‘smallint UNSIGNED‘, ‘SlugField‘: ‘varchar(%(max_length)s)‘, ‘SmallIntegerField‘: ‘smallint‘, ‘TextField‘: ‘longtext‘, ‘TimeField‘: ‘time‘, ‘UUIDField‘: ‘char(32)‘, BooleanField(Field) - 布尔值类型 NullBooleanField(Field): - 可以为空的布尔值 CharField(Field) - 字符类型 - 必须提供max_length参数, max_length表示字符长度 TextField(Field) - 文本类型 EmailField(CharField): - 字符串类型,Django Admin以及ModelForm中提供验证机制 IPAddressField(Field) - 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制 GenericIPAddressField(Field) - 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6 - 参数: protocol,用于指定Ipv4或Ipv6, ‘both‘,"ipv4","ipv6" unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启刺功能,需要protocol="both" URLField(CharField) - 字符串类型,Django Admin以及ModelForm中提供验证 URL SlugField(CharField) - 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号) CommaSeparatedIntegerField(CharField) - 字符串类型,格式必须为逗号分割的数字 UUIDField(Field) - 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证 FilePathField(Field) - 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能 - 参数: path, 文件夹路径 match=None, 正则匹配 recursive=False, 递归下面的文件夹 allow_files=True, 允许文件 allow_folders=False, 允许文件夹 FileField(Field) - 字符串,路径保存在数据库,文件上传到指定目录 - 参数: upload_to = "" 上传文件的保存路径 storage = None 存储组件,默认django.core.files.storage.FileSystemStorage ImageField(FileField) - 字符串,路径保存在数据库,文件上传到指定目录 - 参数: upload_to = "" 上传文件的保存路径 storage = None 存储组件,默认django.core.files.storage.FileSystemStorage width_field=None, 上传图片的高度保存的数据库字段名(字符串) height_field=None 上传图片的宽度保存的数据库字段名(字符串) DateTimeField(DateField) - 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ] DateField(DateTimeCheckMixin, Field) - 日期格式 YYYY-MM-DD TimeField(DateTimeCheckMixin, Field) - 时间格式 HH:MM[:ss[.uuuuuu]] DurationField(Field) - 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型 FloatField(Field) - 浮点型 DecimalField(Field) - 10进制小数 - 参数: max_digits,小数总长度 decimal_places,小数位长度 BinaryField(Field) - 二进制类型 字段
2、Django admin级别生效
针对 dango_admin生效的参数(正则匹配)(使用Django admin就需要关心以下参数!!))
blanke (是否为空) editable=False 是否允许编辑 help_text="提示信息"提示信息 choices=choice 提供下拉框 error_messages="错误信息" 错误信息 validators 自定义错误验证(列表类型),从而定制想要的验证规则 from django.core.validators import RegexValidator from django.core.validators import EmailValidator,URLValidator,DecimalValidator, MaxLengthValidator,MinLengthValidator,MaxValueValidator,MinValueValidator 如: test = models.CharField( max_length=32, error_messages={ ‘c1‘: ‘优先错信息1‘, ‘c2‘: ‘优先错信息2‘, ‘c3‘: ‘优先错信息3‘, }, validators=[ RegexValidator(regex=‘root_\d+‘, message=‘错误了‘, code=‘c1‘), RegexValidator(regex=‘root_112233\d+‘, message=‘又错误了‘, code=‘c2‘), EmailValidator(message=‘又错误了‘, code=‘c3‘), ]
orm使用方式:
orm操作可以使用类实例化,obj.save的方式,也可以使用create()的形式
QuerySet数据类型介绍
QuerySet与惰性机制
所谓惰性机制:Publisher.objects.all()或者.filter()等都只是返回了一个QuerySet(查询结果集对象),它并不会马上执行sql,而是当调用QuerySet的时候才执行。
QuerySet特点:
<1> 可迭代的
<2> 可切片
<3>惰性计算和缓存机制
def queryset(request): books=models.Book.objects.all()[:10] #切片 应用分页 books = models.Book.objects.all()[::2] book= models.Book.objects.all()[6] #索引 print(book.title) for obj in books: #可迭代 print(obj.title) books=models.Book.objects.all() #惰性计算--->等于一个生成器,不应用books不会执行任何SQL操作 # query_set缓存机制1次数据库查询结果query_set都会对应一块缓存,再次使用该query_set时,不会发生新的SQL操作; #这样减小了频繁操作数据库给数据库带来的压力; authors=models.Author.objects.all() for author in authors: print(author.name) print(‘-------------------------------------‘) models.Author.objects.filter(id=1).update(name=‘张某‘) for author in authors: print(author.name) #但是有时候取出来的数据量太大会撑爆缓存,可以使用迭代器优雅得解决这个问题; models.Publish.objects.all().iterator() return HttpResponse(‘OK‘)
增加和查询操作
增
def orm(request): orm2添加一条记录的方法 单表 1、表.objects.create() models.Publish.objects.create(name=‘浙江出版社‘,addr="浙江.杭州") models.Classify.objects.create(category=‘武侠‘) models.Author.objects.create(name=‘金庸‘,sex=‘男‘,age=89,university=‘东吴大学‘) 2、类实例化:obj=类(属性=XX) obj.save() obj=models.Author(name=‘吴承恩‘,age=518,sex=‘男‘,university=‘龙溪学院‘) obj.save() 1对多 1、表.objects.create() models.Book.objects.create(title=‘笑傲江湖‘,price=200,date=1968,classify_id=6, publish_id=6) 2、类实例化:obj=类(属性=X,外键=obj)obj.save() classify_obj=models.Classify.objects.get(category=‘武侠‘) publish_obj=models.Publish.objects.get(name=‘河北出版社‘) 注意以上获取得是和 book对象 向关联的(外键)的对象 book_obj=models.Book(title=‘西游记‘,price=234,date=1556,classify=classify_obj,publish=publish_obj) book_obj.save() 多对多 如果两表之间存在双向1对N关系,就无法使用外键来描述其关系了; 只能使用多对多的方式,新增第三张表关系描述表; book=models.Book.objects.get(title=‘笑傲江湖‘) author1=models.Author.objects.get(name=‘金庸‘) author2=models.Author.objects.get(name=‘张根‘) book.author.add(author1,author2) 书籍和作者是多对多关系, 切记:如果两表之间存在多对多关系,例如书籍相关的所有作者对象集合,作者也关联的所有书籍对象集合 book=models.Book.objects.get(title=‘西游记‘) author=models.Author.objects.get(name=‘吴承恩‘) author2 = models.Author.objects.get(name=‘张根‘) book.author.add(author,author2) #add() 添加 #clear() 清空 #remove() 删除某个对象 return HttpResponse(‘OK‘)
删
级联删除
为防止读者跑路,不再赘述!
改
# 修改方式1 update() models.Book.objects.filter(id=1).update(price=3) #修改方式2 obj.save() book_obj=models.Book.objects.get(id=1) book_obj.price=5 book_obj.save()
查
def ormquery(request): books=models.Book.objects.all() #------query_set对象集合 [对象1、对象2、.... ] books=models.Book.objects.filter(id__gt=2,price__lt=100) book=models.Book.objects.get(title__endswith=‘金‘) #---------单个对象,没有找到会报错 book1 = models.Book.objects.filter(title__endswith=‘金‘).first() book2 = models.Book.objects.filter(title__icontains=‘瓶‘).last() books=models.Book.objects.values(‘title‘,‘price‘, #-------query_set字典集合 [{一条记录},{一条记录} ] ‘publish__name‘, ‘date‘, ‘classify__category‘, #切记 正向连表:外键字段___对应表字段 ‘author__name‘, #反向连表: 小写表名__对应表字段 ‘author__sex‘, #区别:正向 外键字段__,反向 小写表名__ ‘author__age‘, ‘author__university‘) books=models.Book.objects.values(‘title‘,‘publish__name‘).distinct() #exclude 按条件排除。。。 #distinct()去重, exits()查看数据是否存在? 返回 true 和false a=models.Book.objects.filter(title__icontains=‘金‘). return HttpResponse(‘OK‘)
连表查询
反向连表查询: 1、通过object的形式反向连表, obj.小写表名_set.all() publish=models.Publish.objects.filter(name__contains=‘湖南‘).first() books=publish.book_set.all() for book in books: print(book.title) 通过object的形式反向绑定外键关系 authorobj = models.Author.objects.filter(id=1).first() objects = models.Book.objects.all() authorobj.book_set.add(*objects) authorobj.save() 2、通过values双下滑线的形式,objs.values("小写表名__字段") 注意对象集合调用values(),正向查询是外键字段__XX,而反向是小写表名__YY看起来比较容易混淆; books=models.Publish.objects.filter(name__contains=‘湖南‘).values(‘name‘,‘book__title‘) authors=models.Book.objects.filter(title__icontains=‘我的‘).values(‘author__name‘) print(authors) fifter()也支持__小写表名语法进行连表查询:在publish标查询 出版过《笑傲江湖》的出版社 publishs=models.Publish.objects.filter(book__title=‘笑傲江湖‘).values(‘name‘) print(publishs) 查询谁(哪位作者)出版过的书价格大于200元 authors=models.Author.objects.filter(book__price__gt=200).values(‘name‘) print(authors) 通过外键字段正向连表查询,出版自保定的书籍; city=models.Book.objects.filter(publish__addr__icontains=‘保定‘).values(‘title‘) print(city)
# 增 # # models.Tb1.objects.create(c1=‘xx‘, c2=‘oo‘) 增加一条数据,可以接受字典类型数据 **kwargs # obj = models.Tb1(c1=‘xx‘, c2=‘oo‘) # obj.save() # 查 # # models.Tb1.objects.get(id=123) # 获取单条数据,不存在则报错(不建议) # models.Tb1.objects.all() # 获取全部 # models.Tb1.objects.filter(name=‘seven‘) # 获取指定条件的数据 # 删 # # models.Tb1.objects.filter(name=‘seven‘).delete() # 删除指定条件的数据 # 改 # models.Tb1.objects.filter(name=‘seven‘).update(gender=‘0‘) # 将指定条件的数据更新,均支持 **kwargs # obj = models.Tb1.objects.get(id=1) # obj.c1 = ‘111‘ # obj.save() # 修改单条数据 基本操作
利用双下划线将字段和对应的操作连接起来
# 获取个数 # # models.Tb1.objects.filter(name=‘seven‘).count() # 大于,小于 # # models.Tb1.objects.filter(id__gt=1) # 获取id大于1的值 # models.Tb1.objects.filter(id__gte=1) # 获取id大于等于1的值 # models.Tb1.objects.filter(id__lt=10) # 获取id小于10的值 # models.Tb1.objects.filter(id__lte=10) # 获取id小于10的值 # models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 # in # # models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 # models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in # isnull # Entry.objects.filter(pub_date__isnull=True) # contains # # models.Tb1.objects.filter(name__contains="ven") # models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 # models.Tb1.objects.exclude(name__icontains="ven") # range # # models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and # 其他类似 # # startswith,istartswith, endswith, iendswith, # order by # # models.Tb1.objects.filter(name=‘seven‘).order_by(‘id‘) # asc # models.Tb1.objects.filter(name=‘seven‘).order_by(‘-id‘) # desc # group by # # from django.db.models import Count, Min, Max, Sum # models.Tb1.objects.filter(c1=1).values(‘id‘).annotate(c=Count(‘num‘)) # SELECT "app01_tb1"."id", COUNT("app01_tb1"."num") AS "c" FROM "app01_tb1" WHERE "app01_tb1"."c1" = 1 GROUP BY "app01_tb1"."id" # limit 、offset # # models.Tb1.objects.all()[10:20] # regex正则匹配,iregex 不区分大小写 # # Entry.objects.get(title__regex=r‘^(An?|The) +‘) # Entry.objects.get(title__iregex=r‘^(an?|the) +‘) # date # # Entry.objects.filter(pub_date__date=datetime.date(2005, 1, 1)) # Entry.objects.filter(pub_date__date__gt=datetime.date(2005, 1, 1)) # year # # Entry.objects.filter(pub_date__year=2005) # Entry.objects.filter(pub_date__year__gte=2005) # month # # Entry.objects.filter(pub_date__month=12) # Entry.objects.filter(pub_date__month__gte=6) # day # # Entry.objects.filter(pub_date__day=3) # Entry.objects.filter(pub_date__day__gte=3) # week_day # # Entry.objects.filter(pub_date__week_day=2) # Entry.objects.filter(pub_date__week_day__gte=2) # hour # # Event.objects.filter(timestamp__hour=23) # Event.objects.filter(time__hour=5) # Event.objects.filter(timestamp__hour__gte=12) # minute # # Event.objects.filter(timestamp__minute=29) # Event.objects.filter(time__minute=46) # Event.objects.filter(timestamp__minute__gte=29) # second # # Event.objects.filter(timestamp__second=31) # Event.objects.filter(time__second=2) # Event.objects.filter(timestamp__second__gte=31) 进阶操作
# extra # # extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # Entry.objects.extra(select={‘new_id‘: "select col from sometable where othercol > %s"}, select_params=(1,)) # Entry.objects.extra(where=[‘headline=%s‘], params=[‘Lennon‘]) # Entry.objects.extra(where=["foo=‘a‘ OR bar = ‘a‘", "baz = ‘a‘"]) # Entry.objects.extra(select={‘new_id‘: "select id from tb where id > %s"}, select_params=(1,), order_by=[‘-nid‘]) # F # # from django.db.models import F # models.Tb1.objects.update(num=F(‘num‘)+1) # Q # # 方式一: # Q(nid__gt=10) # Q(nid=8) | Q(nid__gt=10) # Q(Q(nid=8) | Q(nid__gt=10)) & Q(caption=‘root‘) # 方式二: # con = Q() # q1 = Q() # q1.connector = ‘OR‘ # q1.children.append((‘id‘, 1)) # q1.children.append((‘id‘, 10)) # q1.children.append((‘id‘, 9)) # q2 = Q() # q2.connector = ‘OR‘ # q2.children.append((‘c1‘, 1)) # q2.children.append((‘c1‘, 10)) # q2.children.append((‘c1‘, 9)) # con.add(q1, ‘AND‘) # con.add(q2, ‘AND‘) # # models.Tb1.objects.filter(con) # 执行原生SQL # # from django.db import connection, connections # cursor = connection.cursor() # cursor = connections[‘default‘].cursor() # cursor.execute("""SELECT * from auth_user where id = %s""", [1]) # row = cursor.fetchone() 其他操作
我们在学习django中的orm的时候,我们可以把一对多,多对多,分为正向和反向查找两种方式。
正向查找:ForeignKey在 UserInfo表中,如果从UserInfo表开始向其他的表进行查询,这个就是正向操作,反之如果从UserType表去查询其他的表这个就是反向操作。
正向连表操作总结:
所谓正、反向连表操作的认定无非是Foreign_Key字段在哪张表决定的,
Foreign_Key字段在哪张表就可以哪张表使用Foreign_Key字段连表,反之没有Foreign_Key字段就使用与其关联的 小写表名;
1对多:对象.外键.关联表字段,values(外键字段__关联表字段)
多对多:外键字段.all()
反向连表操作总结:
通过value、value_list、fifter 方式反向跨表:小写表名__关联表字段
通过对象的形式反向跨表:小写表名_set().all()
应用场景:
一对多:当一张表中创建一行数据时,有一个单选的下拉框(可以被重复选择)
例如:创建用户信息时候,需要选择一个用户类型【普通用户】【金牌用户】【铂金用户】等。
多对多:在某表中创建一行数据是,有一个可以多选的下拉框
例如:创建用户信息,需要为用户指定多个爱好
一对一:在某表中创建一行数据时,有一个单选的下拉框(下拉框中的内容被用过一次就消失了
例如:原有含10列数据的一张表保存相关信息,经过一段时间之后,10列无法满足需求,需要为原来的表再添加5列数据
如果A表的1条记录对应B表中N条记录成立,两表之间就是1对多关系;在1对多关系中 A表就是主表,B表为子表,ForeignKey字段就建在子表;
如果B表的1条记录也对应A表中N条记录,两表之间就是双向1对多关系,也称为多对多关系;
在orm中设置如果 A表设置了外键字段user=models.ForeignKey(‘UserType‘)到B表(注意外键表名加引号)
就意味着 写在写A表的B表主键, (一列),代表B表的多个(一行)称为1对多,
查询
总结:利用orm获取 数据库表中多个数据
获取到的数据类型本质上都是 queryset类型,
类似于列表,
内部有3种表现形式(对象,字典,列表)
modle.表名.objects.all()
modle.表名.objects.values()
modle.表名.objects.values()
跨表
正操作
所以表间只要有外键关系就可以一直点下去。。。点到天荒地老
所以可以通过obj.外键.B表的列表跨表操作(注意!!orm连表操作必须选拿单个对象,不像SQL中直接表和表join就可以了)
print(obj.cls.title)
foreignkey字段在那个表里,那个表里一个"空格"代表那个表的多个(一行)
class UserGroup(models.Model): """ 部门 3 """ title = models.CharField(max_length=32) class UserInfo(models.Model): """ 员工4 """ nid = models.BigAutoField(primary_key=True) user = models.CharField(max_length=32) password = models.CharField(max_length=64) age = models.IntegerField(default=1) # ug_id 1 ug = models.ForeignKey("UserGroup",null=True)
1. 在取得时候跨表
q = UserInfo.objects.all().first()
q.ug.title
2. 在查的时候就跨表了
UserInfo.objects.values(‘nid‘,‘ug_id‘)
UserInfo.objects.values(‘nid‘,‘ug_id‘,‘ug__title‘) #注意正向连表是 外键__外键列 反向是小写的表名
3. UserInfo.objects.values_list(‘nid‘,‘ug_id‘,‘ug__title‘)
反向连表:
反向操作无非2种方式:
1、通过对象的形式反向跨表:小写表面_set().all()
2、通过value和value_list方式反向跨表:小写表名__字段
1. 小写的表名_set 得到有外键关系的对象
obj = UserGroup.objects.all().first()
result = obj.userinfo_set.all() [userinfo对象,userinfo对象,]
2. 小写的表名 得到有外键关系的列 #因为使用values取值取得是字典的不是对象,所以需要 小写表名(外键表)__
v = UserGroup.objects.values(‘id‘,‘title‘)
v = UserGroup.objects.values(‘id‘,‘title‘,‘小写的表名称‘)
v = UserGroup.objects.values(‘id‘,‘title‘,‘小写的表名称__age‘)
3. 小写的表名 得到有外键关系的列
v = UserGroup.objects.values_list(‘id‘,‘title‘)
v = UserGroup.objects.values_list(‘id‘,‘title‘,‘小写的表名称‘)
v = UserGroup.objects.values_list(‘id‘,‘title‘,‘小写的表名称__age‘)
1对多自关联( 由原来的2张表,变成一张表! )
想象有第二张表,关联自己表中的 行
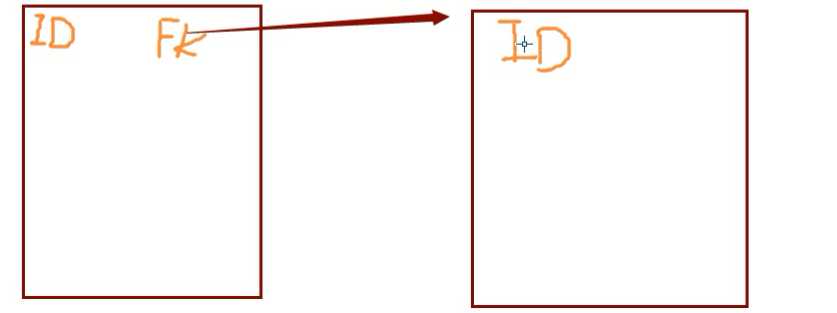
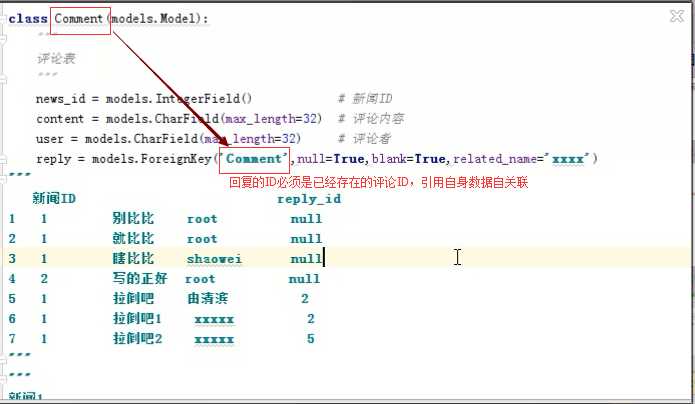
代码
class Comment(models.Model): """ 评论表 """ news_id = models.IntegerField() # 新闻ID content = models.CharField(max_length=32) # 评论内容 user = models.CharField(max_length=32) # 评论者 reply = models.ForeignKey(‘Comment‘,null=True,blank=True,related_name=‘xxxx‘) #回复ID
1、自己写第3张关系表
ORM多对多查询:
女士表:
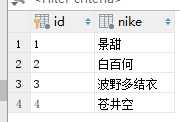
男生表:
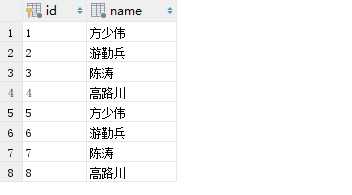
男女关系表

多对跨表操作
#获取方少伟有染的女孩 obj=models.Boy.objects.filter(name=‘方少伟‘).first() obj_list=obj.love_set.all() for row in obj_list: print(row.g.nike) # 获取和苍井空有染的男孩 obj=models.Girl.objects.filter(nike=‘苍井空‘).first() user_list=obj.love_set.all() for row in user_list: print(row.b.name)
多对多关系表 数据查找思路
1、找到该对象
2.通过该对象 反向操作 找到第三张关系表
3.通过第三张关系表 正向操作 找到 和该对象有关系对象
总结(只要对象1和对象2 中间有关系表建立了关系; 对象1反向操作 到关系表 ,关系表正向操作到对象2,反之亦然
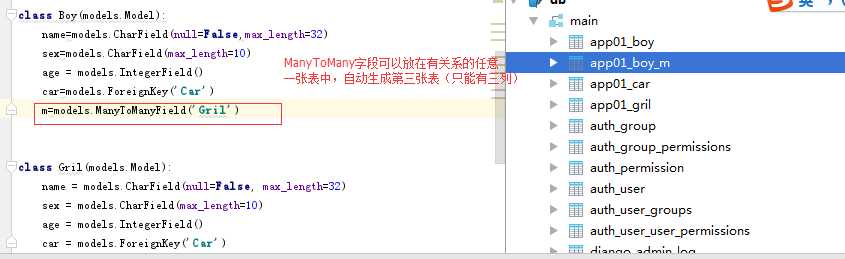
由于 DjangoORM中一个类名对应一张表,要想操作表就modles.类直接操作那张表,但使用ManyToManyField字段生成 “第三张”关系表怎么操作它呢?
答案:通过单个objd对象 间接操作
class Boy(models.Model): name = models.CharField(max_length=32) m = models.ManyToManyField(‘Girl‘,through="Love",through_fields=(‘b‘,‘g‘,)) class Girl(models.Model): nick = models.CharField(max_length=32) m = models.ManyToManyField(‘Boy‘)
正向操作: obj.m.all()
obj = models.Boy.objects.filter(name=‘方少伟‘).first() print(obj.id,obj.name) obj.m.add(2) obj.m.add(2,4) obj.m.add(*[1,]) obj.m.remove(1) obj.m.remove(2,3) obj.m.remove(*[4,]) obj.m.set([1,]) q = obj.m.all() # [Girl对象] print(q) obj = models.Boy.objects.filter(name=‘方少伟‘).first() girl_list = obj.m.all() obj = models.Boy.objects.filter(name=‘方少伟‘).first() girl_list = obj.m.all() girl_list = obj.m.filter(nick=‘小鱼‘) print(girl_list) obj = models.Boy.objects.filter(name=‘方少伟‘).first() obj.m.clear()
反向操作 :obj.小写的表名_set
多对多和外键跨表一样都是 小写的表名_set
ManyToManyField()字段创建第3张关系表,可以使用字段跨表查询,但无法直接操作第3张表,
自建第3表关系表可以直接操作,但无法通过字段 查询,我们可以把他们结合起来使用;
作用:
1、既可以使用字段跨表查询,也可以直接操作第3张关系表
2、obj.m.all() 只有查询和清空 方法
class UserInfo(AbstractUser): """ 用户信息 """ nid = models.BigAutoField(primary_key=True) nickname = models.CharField(verbose_name=‘昵称‘, max_length=32) telephone = models.CharField(max_length=11, blank=True, null=True, unique=True, verbose_name=‘手机号码‘) avatar = models.FileField(verbose_name=‘头像‘, upload_to=‘upload/avatar/‘) create_time = models.DateTimeField(verbose_name=‘创建时间‘,auto_now_add=True) fans = models.ManyToManyField(verbose_name=‘粉丝们‘, to=‘UserInfo‘, through=‘UserFans‘, through_fields=(‘user‘, ‘follower‘)) def __str__(self): return self.username class UserFans(models.Model): """ 互粉关系表 """ nid = models.AutoField(primary_key=True) user = models.ForeignKey(verbose_name=‘博主‘, to=‘UserInfo‘, to_field=‘nid‘, related_name=‘users‘) follower = models.ForeignKey(verbose_name=‘粉丝‘, to=‘UserInfo‘, to_field=‘nid‘, related_name=‘followers‘) class Meta: unique_together = [ (‘user‘, ‘follower‘), ] through=‘UserFans‘指定第3张关系表的表名 through_fields 指定第3张关系表的字段
class Boy(models.Model): name = models.CharField(max_length=32) m = models.ManyToManyField(‘Girl‘,through="Love",through_fields=(‘b‘,‘g‘,)) # 查询和清空 class Girl(models.Model): nick = models.CharField(max_length=32) # m = models.ManyToManyField(‘Boy‘) class Love(models.Model): b = models.ForeignKey(‘Boy‘) g = models.ForeignKey(‘Girl‘) class Meta: unique_together = [ (‘b‘,‘g‘),
在写ForeignKey字段的时候,如果想要在反向查找时不使用默认的 小写的表名_set,就在定义这个字段的时间加related参数!
related_name、related_query_name 字段=什么别名 反向查找时就使用什么别名!
反向查找:
设置了related_query_name 反向查找时就是obj.别名_set.all()保留了_set
related_query_name
from django.db import models class Userinfo(models.Model): nikename=models.CharField(max_length=32) username=models.CharField(max_length=32) password=models.CharField(max_length=64) sex=((1,‘男‘),(2,‘女‘)) gender=models.IntegerField(choices=sex) ‘‘‘把男女表混合在一起,在代码层面控制第三张关系表的外键关系 ‘‘‘ #写到此处问题就来了,原来两个外键 对应2张表 2个主键 可以识别男女 #现在两个外键对应1张表 反向查找 无法区分男女了了 # object对象女.U2U.Userinfo.set object对象男.U2U.Userinfo.set #所以要加related_query_name对 表中主键 加以区分 #查找方法 # 男 obj.a._set.all() # 女:obj.b._set.all() class U2U(models.Model): b=models.ForeignKey(Userinfo,related_query_name=‘a‘) g=models.ForeignKey(Userinfo,related_query_name=‘b‘)
反向查找:
设置了relatedname就是 反向查找时就说 obj.别名.all()
from django.db import models class Userinfo(models.Model): nikename=models.CharField(max_length=32) username=models.CharField(max_length=32) password=models.CharField(max_length=64) sex=((1,‘男‘),(2,‘女‘)) gender=models.IntegerField(choices=sex) ‘‘‘把男女表混合在一起,在代码层面控制第三张关系表的外键关系 ‘‘‘ #写到此处问题就来了,原来两个外键 对应2张表 2个主键 可以识别男女 #现在两个外键对应1张表 反向查找 无法区分男女了了 # object对象女.U2U.Userinfo.set object对象男.U2U.Userinfo.set #所以要加related_query_name设置反向查找命名对 表中主键 加以区分 #查找方法 # 男 obj.a.all() # 女:obj.b.all() class U2U(models.Model): b=models.ForeignKey(Userinfo,related_name=‘a‘) g=models.ForeignKey(Userinfo,related_name=‘b‘)
操作
from django.shortcuts import render,HttpResponse from app01 import models # Create your views here. def index(request): #查找 ID为1男孩 相关的女孩 boy_obj=models.Userinfo.objects.filter(id=1).first() res= boy_obj.boy.all()#得到U2U的对象再 正向跨表 #原来跨表 boy_obj.小写表名.all() # 现在设置了related_name(别名) 直接res= boy_obj.boy.all()跨表 for obj in res: print(obj.g.nikename) return HttpResponse(‘OK‘)
把两张表通过 choices字段合并为一张表
‘第三张关系表’ 使用models.ManyToManyField(‘Userinfo‘)生成
特性:
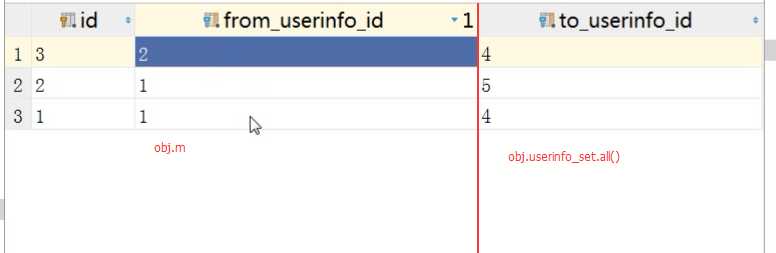
obj = models.UserInfo.objects.filter(id=1).first() 获取对象
1、查询第三张关系表前面那一列:obj.m
select xx from xx where from_userinfo_id = 1
2、查询第三张关系表后面那一列:obj.userinfo_set
select xx from xx where to_userinfo_id = 1
class Userinfo(models.Model): nikename=models.CharField(max_length=32) username=models.CharField(max_length=32) password=models.CharField(max_length=64) sex=((1,‘男‘),(2,‘女‘)) gender=models.IntegerField(choices=sex) m=models.ManyToManyField(‘Userinfo‘)
查找方法
def index(request): # 多对多自关联 之通过男士查询女生 boy_obj=models.Userinfo.objects.filter(id=4).first() res=boy_obj.m.all() for row in res: print(row.nikename) return HttpResponse(‘OK‘) #多对多自关联 之通过女士查询男生 girl_obj=models.Userinfo.objects.filter(id=4).first() res=girl_obj.userinfo_set.all() for obj in res: print(obj.nikename) return HttpResponse(‘OK‘)
多对多自关联特性:
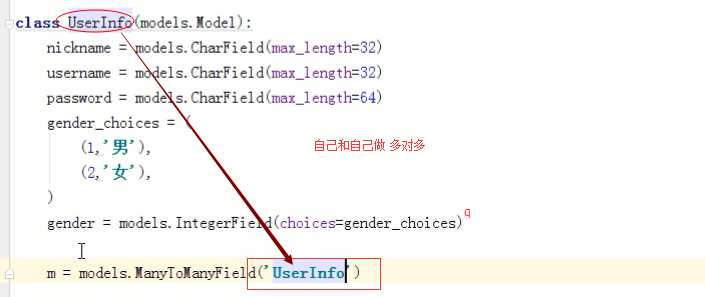
ManyToManyField生成的第三张表
普通查询 obj_list=models.Love.objects.all() for row in obj_list: #for循环10次发送10次数据库查询请求 print(row.b.name) 这种查询方式第一次发送 查询请求每for循环一次也会发送查询请求 1、select_related:结果为对象 注意query_set类型的对象 都有该方法 原理: 查询时主动完成连表形成一张大表,for循环时不用额外发请求; 试用场景: 节省硬盘空间,数据量少时候适用相当于做了一次数据库查询; obj_list=models.Love.objects.all().select_related(‘b‘) for row in obj_list: print(row.b.name) 2、prefetch_related:结果都对象是 原理:虽好,但是做连表操作依然会影响查询性能,所以出现prefetch_related prefetch_related:不做连表,多次单表查询外键表 去重之后显示, 2次单表查询(有几个外键做几次1+N次单表查询, 适用场景:效率高,数据量大的时候试用 obj_list=models.Love.objects.all().prefetch_related(‘b‘) for obj in obj_list: print(obj.b.name) 3、update()和对象.save()修改方式的性能PK 修改方式1 models.Book.objects.filter(id=1).update(price=3) 方式2 book_obj=models.Book.objects.get(id=1) book_obj.price=5 book_obj.save() 执行结果: (0.000) BEGIN; args=None (0.000) UPDATE "app01_book" SET "price" = ‘3.000‘ WHERE "app01_book"."id" = 1; args=(‘3.000‘, 1) (0.000) SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."date", "app01_book"."publish_id", "app01_book"."classify_id" FROM "app01_book" WHERE "app01_book"."id" = 1; args=(1,) (0.000) BEGIN; args=None (0.000) UPDATE "app01_book" SET "title" = ‘我的奋斗‘, "price" = ‘5.000‘, "date" = ‘1370-09-09‘, "publish_id" = 4, "classify_id" = 3 WHERE "app01_book"."id" = 1; args=(‘我的奋斗‘, ‘5.000‘, ‘1370-09-09‘, 4, 3, 1) [31/Aug/2017 17:07:20] "GET /fandq/ HTTP/1.1" 200 2 结论: update() 方式1修改数据的方式,比obj.save()性能好;
1、aggregate(*args,**kwargs) 聚合函数
通过对QuerySet进行计算,返回一个聚合值的字典。aggregate()中每一个参数都指定一个包含在字典中的返回值。即在查询集上生成聚合。
from django.db.models import Avg,Sum,Max,Min #求书籍的平均价 ret=models.Book.objects.all().aggregate(Avg(‘price‘)) #{‘price__avg‘: 145.23076923076923} #参与西游记著作的作者中最老的一位作者 ret=models.Book.objects.filter(title__icontains=‘西游记‘).values(‘author__age‘).aggregate(Max(‘author__age‘)) #{‘author__age__max‘: 518} #查看根哥出过得书中价格最贵一本 ret=models.Author.objects.filter(name__contains=‘根‘).values(‘book__price‘).aggregate(Max(‘book__price‘)) #{‘book__price__max‘: Decimal(‘234.000‘)}
2、annotate(*args,**kwargs) 分组函数
#查看每一位作者出过的书中最贵的一本(按作者名分组 values() 然后annotate 分别取每人出过的书价格最高的) ret=models.Book.objects.values(‘author__name‘).annotate(Max(‘price‘)) # < QuerySet[ # {‘author__name‘: ‘吴承恩‘, ‘price__max‘: Decimal(‘234.000‘)}, # {‘author__name‘: ‘吕不韦‘,‘price__max‘: Decimal(‘234.000‘)}, # {‘author__name‘: ‘姜子牙‘, ‘price__max‘: Decimal(‘123.000‘)}, # {‘author__name‘: ‘亚微‘,price__max‘: Decimal(‘123.000‘)}, # {‘author__name‘: ‘伯夷 ‘, ‘price__max‘: Decimal(‘2010.000‘)}, # {‘author__name‘: ‘叔齐‘,‘price__max‘: Decimal(‘200.000‘)}, # {‘author__name‘: ‘陈涛‘, ‘price__max‘: Decimal(‘234.000‘)}, # {‘author__name‘: ‘高路川‘, price__max‘: Decimal(‘234.000‘)} # ] > #查看每本书的作者中最老的 按作者姓名分组 分别求出每组中年龄最大的 ret=models.Book.objects.values(‘author__name‘).annotate(Max(‘author__age‘)) # < QuerySet[ # {‘author__name‘: ‘吴承恩‘, ‘author__age__max‘: 518}, # {‘author__name‘: ‘张X‘, ‘author__age__max‘: 18}, # { ‘author__name‘: ‘张X杰‘, ‘author__age__max‘: 56}, # {‘author__name‘: ‘方X伟‘, ‘author__age__max‘: 26}, # {‘author__name‘: ‘游X兵‘, ‘author__age__max‘: 35}, # {‘author__name‘: ‘金庸‘, ‘author__age__max‘: 89}, # { ‘author__name‘: ‘X涛‘, ‘author__age__max‘: 27}, # {‘author__name‘: ‘高XX‘, ‘author__age__max‘: 26} # ] > #查看 每个出版社 出版的最便宜的一本书 ret=models.Book.objects.values(‘publish__name‘).annotate(Min(‘price‘)) # < QuerySet[ # {‘publish__name‘: ‘北大出版社‘,‘price__min‘: Decimal(‘67.000‘)}, # {‘publish__name‘: ‘山西出版社‘,‘price__min‘: Decimal(‘34.000‘)}, # {‘publish__name‘: ‘河北出版社‘, ‘price__min‘: Decimal(‘123.000‘)}, # {‘publish__name‘: ‘浙江出版社‘, ‘price__min‘: Decimal(‘2.000‘)}, # {‘publish__name‘: ‘湖北出版社‘, ‘price__min‘: Decimal(‘124.000‘)}, # {‘publish__name‘: ‘湖南出版社‘,price__min‘: Decimal(‘15.000‘)} # ] >
仅仅靠单一的关键字参数查询已经很难满足查询要求。此时Django为我们提供了F和Q查询:
1、F 可以获取对象中的字段的属性(列),并对其进行操作;
from django.db.models import F,Q #F 可以获取对象中的字段的属性(列),并且对其进行操作; models.Book.objects.all().update(price=F(‘price‘)+1) #对图书馆里的每一本书的价格 上调1块钱
2、Q多条件组合查询
Q()可以使orm的fifter()方法支持, 多个查询条件,使用逻辑关系(&、|、~)包含、组合到一起进行多条件查询;
语法:
fifter(Q(查询条件1)| Q(查询条件2))
fifter(Q(查询条件2)& Q(查询条件3))
fifter(Q(查询条件4)& ~Q(查询条件5))
fifter(Q(查询条件6)| Q(Q(查询条件4)& ~ Q(Q(查询条件5)& Q(查询条件3)))包含
from django.db.models import F,Q 1、F 可以获取对象中的字段的属性(列),并且对其进行操作; # models.Book.objects.all().update(price=F(‘price‘)+1) 2、Q多条件组合查询 #如果 多个查询条件 涉及到逻辑使用 fifter(,隔开)可以表示与,但没法表示或非得关系 #查询 书名包含作者名的书 book=models.Book.objects.filter(title__icontains=‘伟‘,author__name__contains=‘伟‘).values(‘title‘) #如何让orm 中得 fifter 支持逻辑判断+多条件查询? Q()登场 book=models.Book.objects.filter(Q(title__icontains=‘伟‘) & Q(author__name__contains=‘伟‘)).values(‘title‘) book=models.Book.objects.filter(Q(author__name__contains=‘伟‘) & ~Q(title__icontains=‘伟‘)).values(‘title‘) #多条件包含组合查询 #查询作者姓名中包含 方/少/伟/书名包含伟3字 并且出版社地址以山西开头的书 book=models.Book.objects.filter( Q( Q(author__name__contains=‘方‘) | Q(author__name__contains=‘少‘) | Q(title__icontains=‘伟‘)| Q(author__name__contains=‘伟‘) ) & Q(publish__addr__contains=‘山西‘) ).values(‘title‘) print(book) return HttpResponse(‘OK‘)
注意:Q查询条件和非Q查询条件混合使用注意,不包Q()的查询条件一点要放在Q(查询条件)后面

标签:phone console migrate lin pass 匹配 正则匹配 保定 image
原文地址:http://www.cnblogs.com/huchong/p/7819473.html
