标签:range 欧氏距离 一个 def ice k-近邻算法 计算 image pre
学习《机器学习实战》第2章
参考博客:http://blog.csdn.net/c406495762/article/details/75172850#三-k-近邻算法实战之sklearn手写数字识别
K近邻法(k-nearest neighbor,K-NN)采用测量不同特征值之间的距离方法进行分类。
工作原理:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似数据,这就是k-近邻算法中k的出处,通常k是不大于20的证书。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
K近邻算法:
对未知类别属性的数据集中的每个点依次执行以下操作
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前点距离最小的k个点;
(4)确定前k个点所在类别的出现频率;
(5)返回前k个点出现频率最高的类别作为当前点的预测分类。
K-近邻算法的python实现:
1 """ 2 函数说明:kNN算法,分类器 3 Parameters: 4 inX - 用于分类的数据(测试集) 5 dataSet - 用于训练的数据(训练集) 6 labes - 分类标签 7 k - kNN算法参数,选择距离最小的k个点 8 Returns: 9 sortedClassCount[0][0] - 分类结果 10 """ 11 def classify0(inX, dataSet, labels, k): 12 #如dataSet为n*m的矩阵,.shape[0]返回n,.shape[1]返回m,.shape返回n,m 13 dataSetSize = dataSet.shape[0] #返回训练集的行数 14 #tile是numpy中的函数,功能是重复:tile(inx,(n,m))按行重复n遍,按列重复m遍。 15 diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet #执行待分类数据与训练数组相减操作,(xi-xj),(yi-yj) 16 #二维特征相减后平方 17 sqDiffMat = diffMat**2 18 #sum()所有元素相加,sum(0)列相加,sum(1)行相加 19 sqDistances = sqDiffMat.sum(axis=1) #(axis=1)是行相加,(axis=0)是列相加 20 #开方,计算出距离,距离是欧氏距离 21 distances = sqDistances**0.5 22 #argsort()是numpy中的函数 23 sortedDistIndices = distances.argsort() #返回distances中元素从小到大排序后的索引值 24 #定一个记录类别次数的字典 25 classCount = {} 26 for i in range(k): 27 #取出前k个元素的类别 28 voteIlabel = labels[sortedDistIndices[i]] 29 #dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值,该处设置默认值为0。 30 #计算类别次数 31 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 32 #字典的items方法返回可遍历的元组数组 33 #key=operator.itemgetter(1)根据字典的值进行排序 34 #key=operator.itemgetter(0)根据字典的键进行排序 35 #reverse降序排序字典,设置为True是降序,False为升序 36 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) 37 #返回次数最多的类别,即所要分类的类别 38 return sortedClassCount[0][0]
按照书上,定义训练集为(1.0, 1.1) (1.0, 1.0) (0.0, 0.0) (0.0, 0.1)
1 def creatDataset(): 2 group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) 3 lables = [‘A‘,‘A‘,‘B‘,‘B‘] 4 return group,lables
用knn对一个未知点进行分类的完整python实现
from numpy import * from matplotlib import * import operator
import numpy as np import matplotlib.pyplot as plt """ 实现:有类A和类B的点,对一个未知点进行分类 """ def creatDataset(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) lables = [‘A‘,‘A‘,‘B‘,‘B‘] return group,lables """ 函数说明:kNN算法,分类器 Parameters: inX - 用于分类的数据(测试集) dataSet - 用于训练的数据(训练集) labes - 分类标签 k - kNN算法参数,选择距离最小的k个点 Returns: sortedClassCount[0][0] - 分类结果 """ def classify0(inX, dataSet, labels, k): #如dataSet为n*m的矩阵,.shape[0]返回n,.shape[1]返回m,.shape返回n,m dataSetSize = dataSet.shape[0] #返回训练集的行数 #tile是numpy中的函数,功能是重复:tile(inx,(n,m))按行重复n遍,按列重复m遍。 diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet #执行待分类数据与训练数组相减操作,(xi-xj),(yi-yj) #二维特征相减后平方 sqDiffMat = diffMat**2 #sum()所有元素相加,sum(0)列相加,sum(1)行相加 sqDistances = sqDiffMat.sum(axis=1) #(axis=1)是行相加,(axis=0)是列相加 #开方,计算出距离 distances = sqDistances**0.5 #argsort()是numpy中的函数 sortedDistIndices = distances.argsort() #返回distances中元素从小到大排序后的索引值 #定一个记录类别次数的字典 classCount = {} for i in range(k): #取出前k个元素的类别 voteIlabel = labels[sortedDistIndices[i]] #dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值,该处设置默认值为0。 #计算类别次数 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #字典的items方法返回可遍历的元组数组 #key=operator.itemgetter(1)根据字典的值进行排序 #key=operator.itemgetter(0)根据字典的键进行排序 #reverse降序排序字典,设置为True是降序,False为升序 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) #返回次数最多的类别,即所要分类的类别 return sortedClassCount[0][0] group,lables=creatDataset() #画出点的分布 plt.plot(group[:,0],group[:,1],‘ro‘,label="point") plt.ylim(-0.2,1.2) plt.xlim(-0.2,1.2) plt.show() #测试[0,0]所属类别 print(classify0([0,0],group,lables,3))
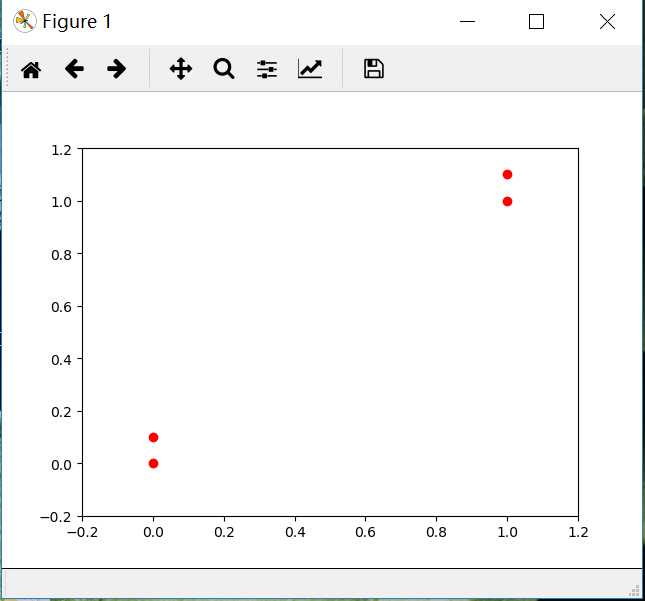
分类结果为:B
标签:range 欧氏距离 一个 def ice k-近邻算法 计算 image pre
原文地址:http://www.cnblogs.com/zj83839/p/7834569.html