标签:lvs负载均衡 拓展 es2017 也有 流程图 127.0.0.1 好的 type 解决
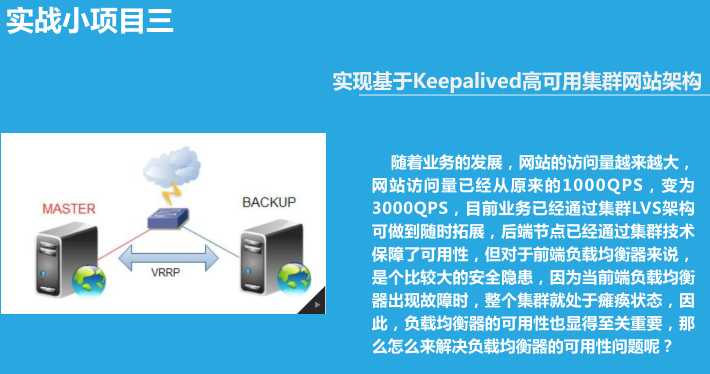
实现基于Keepalived高可用集群网站架构
环境:随着业务的发展,网站的访问量越来越大,网站访问量已经从原来的1000QPS,变为3000QPS,目前业务已经通过集群LVS架构可做到随时拓展,后端节点已经通过集群技术保障了可用性,但对于前端负载均衡器来说,是个比较大的安全隐患,因为当前端负载均衡器出现故障时,整个集群就处于瘫痪状态,因此,负载均衡器的可用性也显得至关重要,那么怎么来解决负载均衡器的可用性问题呢?
总项目流程图,详见http://www.cnblogs.com/along21/p/7435612.html
① 两台服务器都使用yum 方式安装keepalived 服务
② iptables -F && setenforing 清空防火墙策略,关闭selinux
实验原理:
主从:一主一从,主的在工作,从的在休息;主的宕机了,VIP漂移到从上,由从提供服务
两台centos系统做DR、一主一从,两台实现过基于LNMP的电子商务网站
|
机器名称 |
IP配置 |
服务角色 |
备注 |
|
lvs-server-master |
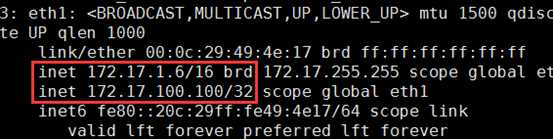
VIP:172.17.100.100 DIP:172.17.1.6 |
负载均衡器 主服务器 |
开启路由功能 配置keepalived |
|
lvs-server-backup |
VIP:172.17.100.100 DIP:172.17.11.11 |
后端服务器 从服务器 |
开启路由功能 配置keepalived |
|
rs01 |
RIP:172.17.1.7 |
后端服务器 |
|
|
rs02 |
RIP:172.17.22.22 |
后端服务器 |
|
修改keepalived主(lvs-server-master)配置文件实现 virtual_instance 实例
(1)vim /etc/keepalived/keepalived.conf 修改三段

① 全局段,故障通知邮件配置
global_defs {
notification_email {
root@localhost
}
notification_email_from root@along.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id keepalived_lvs
}
② 配置虚拟路由器的实例段,VI_1是自定义的实例名称,可以有多个实例段
vrrp_instance VI_1 { #VI_1是自定义的实例名称
state MASTER #初始状态,MASTER|BACKUP
interface eth1 #通告选举所用端口
virtual_router_id 51 #虚拟路由的ID号(一般不可大于255)
priority 100 #优先级信息 #备节点必须更低
advert_int 1 #VRRP通告间隔,秒
authentication {
auth_type PASS #认证机制
auth_pass along #密码(尽量使用随机)
}
virtual_ipaddress {
172.17.100.100 #vip
}
}
③ 设置一个virtual server段
virtual_server 172.17.100.100 80 { #设置一个virtual server:
delay_loop 6 # service polling的delay时间,即服务轮询的时间间隔
lb_algo wrr #LVS调度算法:rr|wrr|lc|wlc|lblc|sh|dh
lb_kind DR #LVS集群模式:NAT|DR|TUN
nat_mask 255.255.255.255
persistence_timeout 600 #会话保持时间(持久连接,秒),即以用户在600秒内被分配到同一个后端realserver
protocol TCP #健康检查用的是TCP还是UDP
④ real server设置段
real_server 172.17.1.7 80 { #后端真实节点主机的权重等设置
weight 1 #给每台的权重,rr无效
HTTP_GET { #http服务
url {
path /
}
connect_timeout 3 #连接超时时间
nb_get_retry 3 #重连次数
delay_before_retry 3 #重连间隔
}
}
real_server 172.17.22.22 80 {
weight 2
HTTP_GET {
url {
path /
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
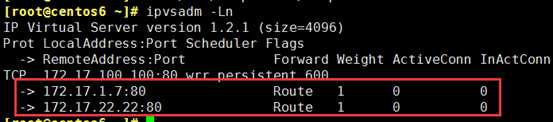
(3)因为是主从方式,所以从上的配置和主只有一点差别;所以可以把这个配置文件拷过去
scp /etc/keepalived/keepalived.conf @172.17.11.11:
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 51
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass along
}
负载均衡策略已经设置好了,注意:主director没有宕机,从上就不会有VIP
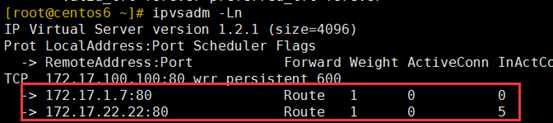
ifconfig lo:0 172.17.100.100 broadcast 172.17.100.100 netmask 255.255.255.255 up
route add -host 172.17.100.100 lo:0
echo "1" > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" > /proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" > /proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" > /proc/sys/net/ipv4/conf/all/arp_announce
1:仅在请求的目标IP配置在本地主机的接收到请求报文的接口上时,才给予响应
net.ipv4.conf.lo.arp_ignore = 1 net.ipv4.conf.lo.arp_announce = 2 net.ipv4.conf.all.arp_ignore = 1 net.ipv4.conf.all.arp_announce = 2
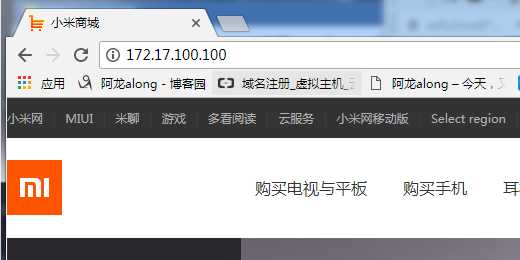
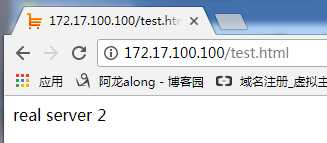
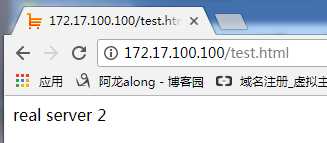
③ 网页访问http://172.17.100.100/test.html 发现有real server 1也有real server 2
③ 使keepalive 的主重新开启服务,因为主的优先级高,所以VIP又重新漂移到了主上
实验原理:
互为主从:主从都在工作;其中一个宕机了,VIP漂移到另一个上,提供服务
|
机器名称 |
IP配置 |
服务角色 |
备注 |
|
lvs-server-1 |
VIP:172.17.100.100 DIP:172.17.1.6 |
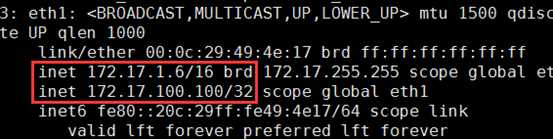
负载均衡器 主服务器 |
开启路由功能 配置keepalived |
|
lvs-server2 |
VIP:172.17.100.101 DIP:172.17.11.11 |
后端服务器 从服务器 |
开启路由功能 配置keepalived |
|
rs01 |
RIP:172.17.1.7 |
后端服务器 |
|
|
rs02 |
RIP:172.17.22.22 |
后端服务器 |
|
修改keepalived主(lvs-server-master)配置文件实现 virtual_instance 实例
(1)vim /etc/keepalived/keepalived.conf
① 主的设置 VI_1
vrrp_instance VI_1 {
state MASTER
interface eth1
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass along
}
virtual_ipaddress {
172.17.100.100
}
}
virtual_server 172.17.100.100 80 {
delay_loop 6
lb_algo wrr
lb_kind DR
nat_mask 255.255.255.255
persistence_timeout 600
protocol TCP
real_server 172.17.1.7 80 {
weight 1
HTTP_GET {
url {
path /
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 172.17.22.22 80 {
weight 1
HTTP_GET {
url {
path /
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
vrrp_instance VI_2 {
state BACKUP
interface eth1
virtual_router_id 52
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass along
}
virtual_ipaddress {
172.17.100.101
}
}
virtual_server 172.17.100.101 443 {
delay_loop 6
lb_algo wrr
lb_kind DR
nat_mask 255.255.255.255
persistence_timeout 600
protocol TCP
real_server 172.17.1.7 443 {
weight 1
HTTP_GET {
url {
path /
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 172.17.22.22 443 {
weight 1
HTTP_GET {
url {
path /
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
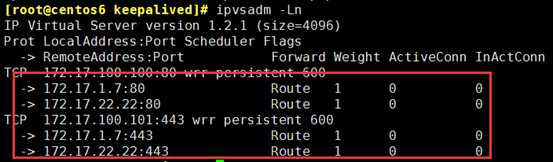
(3)因为是主从方式,所以从上的配置和主只有一点差别;所以可以把这个配置文件拷过去
scp /etc/keepalived/keepalived.conf @172.17.11.11:
(1)vim /etc/keepalived/keepalived.conf
① vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 51
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass along
}
virtual_ipaddress {
172.17.100.100
}
}
② vrrp_instance VI_2 {
state MASTER
interface eth1
virtual_router_id 52
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass along
}
virtual_ipaddress {
172.17.100.101
}
}
能看到网卡别名 和 负载均衡策略已经设置好了,显示结果会等段时间再显示

ifconfig lo:0 172.17.100.100 broadcast 172.17.100.100 netmask 255.255.255.255 up
ifconfig lo:1 172.17.100.101 broadcast 172.17.100.101 netmask 255.255.255.255 up
route add -host 172.17.100.100 lo:0
route add -host 172.17.100.101 lo:1
echo "1" > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" > /proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" > /proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" > /proc/sys/net/ipv4/conf/all/arp_announce
1:仅在请求的目标IP配置在本地主机的接收到请求报文的接口上时,才给予响应
net.ipv4.conf.lo.arp_ignore = 1
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
客户端访问http://172.17.100.100/ 公网172.17.100.100只能访问80
https://172.17.100.101/ 公网172.17.100.101只能访问443
③ 网页访问http://172.17.100.100/test.html或https://172.17.100.101/test.html 发现有real server 1也有real server 2
会发现服务能照常访问,另一个机器80、443都能访问,且宕机的VIP漂移到了另一个服务器上
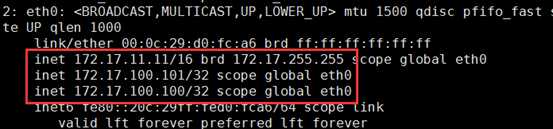
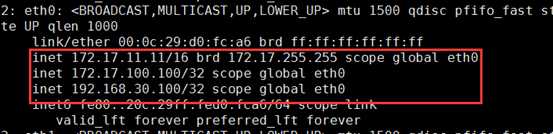
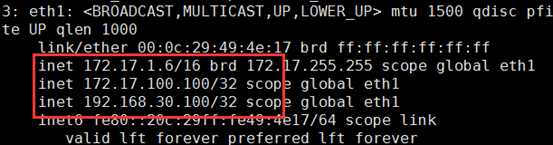
主从:一主一从,主的在工作,从的在休息;主的宕机了,VIP和DIP都漂移到从上,由从提供服务,因为DIP需被rs作为网关,所以也需漂移
|
机器名称 |
IP配置 |
服务角色 |
备注 |
|
vs-server-master |
VIP:172.17.100.100 DIP:192.168.30.100 |
负载均衡器 主服务器 |
开启路由功能 配置keepalived |
|
lvs-server-backup |
VIP:172.17.100.100 DIP:192.168.30.100 |
后端服务器 从服务器 |
开启路由功能 配置keepalived |
|
rs01 |
RIP:192.168.30.107 |
后端服务器 |
网关指向DIP |
|
rs02 |
RIP:192.168.30.7 |
后端服务器 |
网关指向DIP |
global_defs {
notification_email {
root@localhost
}
notification_email_from root@along.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id keepalived_lvs
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass along
}
virtual_ipaddress {
172.17.100.100
192.168.30.100
}
}
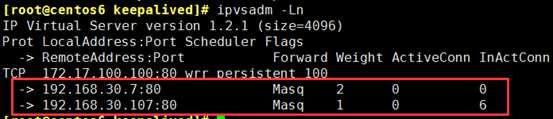
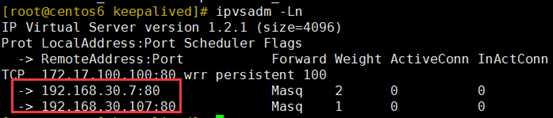
virtual_server 172.17.100.100 80 {
delay_loop 6
lb_algo wrr
lb_kind NAT
nat_mask 255.255.255.255
persistence_timeout 100
protocol TCP
real_server 192.168.30.107 80 {
weight 1
HTTP_GET {
url {
path /
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.30.7 80 {
weight 2
HTTP_GET {
url {
path /
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}

(4)因为是主从方式,所以从上的配置和主只有一点差别;所以可以把这个配置文件拷过去
scp /etc/keepalived/keepalived.conf @172.17.11.11:
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 51
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass along
}
负载均衡策略已经设置好了,注意:主director没有宕机,从上就不会有VIP
route add default gw 192.168.30.100
③ 网页访问http://172.17.100.100/test.html 发现有real server 1也有real server 2
③ 使keepalive 的主重新开启服务,因为主的优先级高,所以VIP和DIP又重新漂移到了主上
脚本主要内容:检测到主从发生变化,或错误,给谁发邮件;邮件内容是:在什么时间,谁发生了什么变化
#!/bin/bash
# Author: www.magedu.com
contact=‘root@localhost‘
notify() {
mailsubject="$(hostname) to be $1: vip floating"
mailbody="$(date +‘%F %H:%M:%S‘): vrrp transition, $(hostname) changed to be $1"
echo $mailbody | mail -s "$mailsubject" $contact
}
case $1 in
master)
notify master
exit 0
;;
backup)
notify backup
exit 0
;;
fault)
notify fault
exit 0
;;
*)
echo "Usage: $(basename $0) {master|backup|fault}"
exit 1
;;
esac
脚本加权限 chmod +x /etc/keepalived/notify.sh
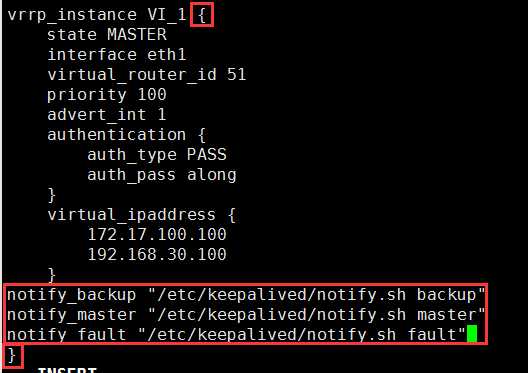
notify_backup "/etc/keepalived/notify.sh backup" notify_master "/etc/keepalived/notify.sh master" notify_fault "/etc/keepalived/notify.sh fault"
原理:在keepalived的配置文件中能直接定义脚本,且能在instance 实例段直接调用生效
vrrp_script chk_down { #定义一个脚本,脚本名称为chk_down
script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0" #检查这个down文件,若存在返回值为1,keepalived会停止;不存在返回值为0,服务正常运行;这里的exit和bash脚本里的return很相似
interval 2 #每2秒检查一次
}
track_script {
chk_down
}
在主上,创建一个/etc/keepalived/down 文件,主的keepalived服务立刻停止,VIP漂到从上,从接上服务;
down文件一旦删除,主的keepalived服务会立即启动,若优先级高或优先级低但设置的抢占,VIP会重漂回来,接上服务。
vrrp_script chk_nginx {
script "killall -0 nginx" #killall -0 检测这个进程是否还活着,不存在就减权重
interval 2 #每2秒检查一次
fall 2 #失败2次就打上ko的标记
rise 2 #成功2次就打上ok的标记
weight -4 #权重,优先级-4,若为ko
}
track_script {
chk_nginx
}
若主的nginx服务没有开启,则每2秒-4的权重,当优先级小于从,VIP漂到从上,从接上服务;
若主的nginx服务开启,重读配置文件,优先级恢复,VIP回到主上,主恢复服务;
标签:lvs负载均衡 拓展 es2017 也有 流程图 127.0.0.1 好的 type 解决
原文地址:http://www.cnblogs.com/haiyabtx/p/7843450.html