标签:正则 循环 分享 ## 情况 bug 数据库 src 文字
这个功能的描述是:
把一本符合
markdown语法写的书里面的所有大章节里面内容的每个大标题和该标题对应下的内容做分离,一 一对应。
一般会出现这种问题的场景:
举个例子,有一段内容是如下:
### 糖尿病的症状 (这是 markdown 的第三级标题)
初期的症状体现在.....分离后要求达到:
title ===> 糖尿病的症状
content ===> 初期的症状体现在...对我而言,这个功能的目的是:
我们把一本书分割成上述的样子,数据存入数据库。供搜索使用。搜索方式,以 title 或 content 做模糊匹配,命中即返回。
相信看到这里的读者都能清楚知道上面谈的是什么,但愿我的文字能通俗易懂,文字多了,我也记不住,累赘。
先谈谈正则匹配下的处理:
然后是逐行处理处理:
两种方法的对比:
举个例子对比:
标题有下面的 markdown 代码形式:
### 第一种标题
#### 第二种
##### 第三种[点我](http://www.xxx.com)
### ``第四种``
### <strong>第五种,嵌套html标签</strong>
...对于上面的情况,第一次的正则拿出标题内容很简单,例如这个: ###? 从三个#号开始贪婪匹配。这样我们可以拿出标题,但是标题里面还掺杂着一些其他标签。你会想,有没有可能在正则匹配就把掺杂的标签去掉。那这个是肯定可以的,代价就是高超的正则匹配式子,且现在还没考虑内容的情况。
为什么非要去掉标签呢? 因为这是标题,标题将会被用作搜索的 key,且返回给前端的时候,你不能把这个解析符号也给前端对吧?去掉了有以下好处:
我们从文件中读出第一行 ### 第一种标题,replace 函数处理掉 ### 等符号,这里循环处理即可去掉指定的任何符号。
读出第三行的时候 ##### 第三种[点我](http://www.xxx.com),处理掉,##### [ ] ( 等,剩下就是完美:第三种点我
我们知道
markdown 的非标题内容部分,符号和标签更是多种多样,如果我们用正则解决,假设标题能完美处理,那么内容怎么办呢? > 如果去掉内容的其他无用标签,或者要求特定保存一些,等情况,多批次的正则过滤将会是花销巨大的操作。
无论是正则匹配方案 还是 逐行处理方案,这两种我都写了对应的引擎函数,通过且以后者运行谓之0 bug。实现的时间加起来不足 3.5 小时。后者尤其快,下面我仅主要介绍后者的解决流程。
内容66655
#### 标题一
#### 标题二
456789....输出:
title[0] ===> "标题一" , content[0] ===> ""
title[0] ===> "标题二" , content[0] ===> "456789...."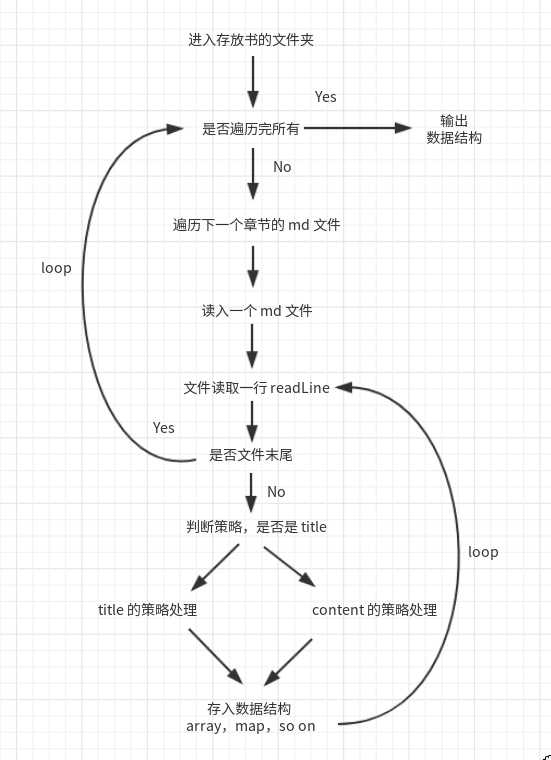
至此,已经很简答,例如 Java 语言的 String API startWith 就能用在判断是否是title,if(startWith"####")
过滤方面,replace 之类的函数,等都可以。公司代码,不便公开。
标签:正则 循环 分享 ## 情况 bug 数据库 src 文字
原文地址:http://www.cnblogs.com/linguanh/p/7844628.html