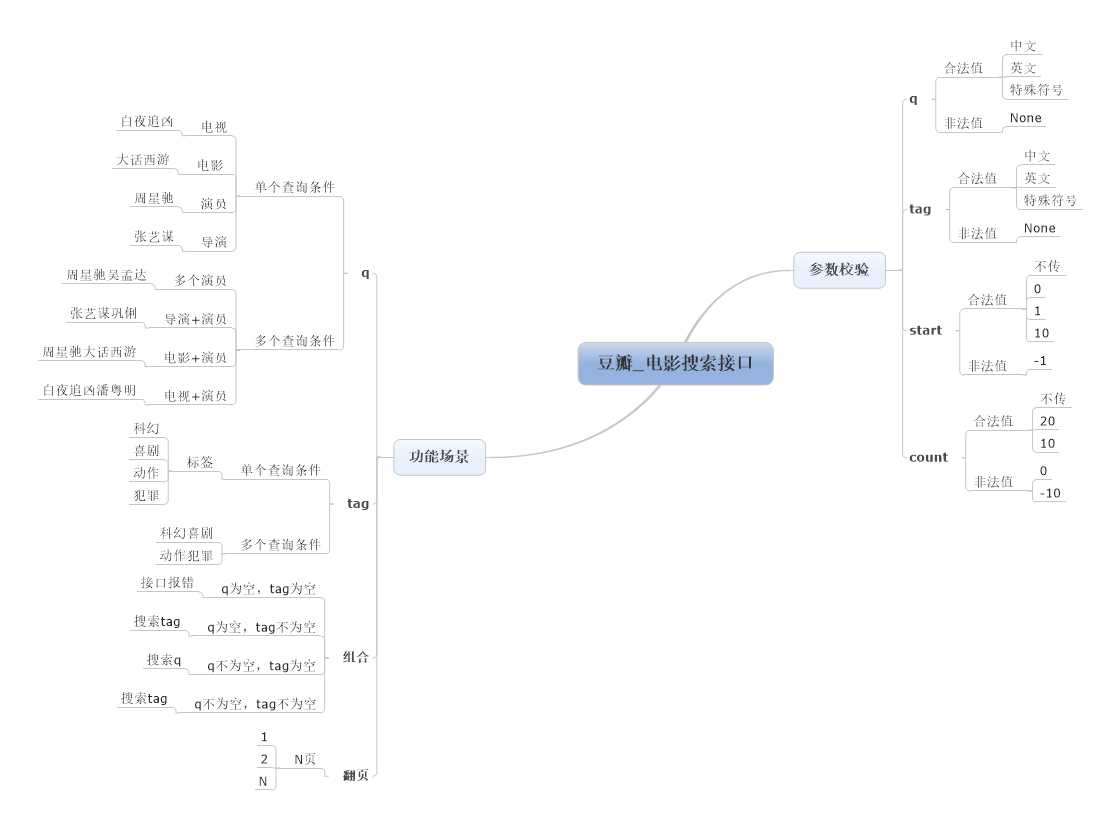
标签:str .json ext 使用 smt join osi 文档 参数
pip install nose pip install nose-html-reporting pip install requests
#coding=utf-8 import requests import json url = ‘https://api.douban.com/v2/movie/search‘ params=dict(q=u‘刘德华‘) r = requests.get(url, params=params) print ‘Search Params:\n‘, json.dumps(params, ensure_ascii=False) print ‘Search Response:\n‘, json.dumps(r.json(), ensure_ascii=False, indent=4)
class test_doubanSearch(object): @staticmethod def search(params, expectNum=None): url = ‘https://api.douban.com/v2/movie/search‘ r = requests.get(url, params=params) print ‘Search Params:\n‘, json.dumps(params, ensure_ascii=False) print ‘Search Response:\n‘, json.dumps(r.json(), ensure_ascii=False, indent=4) def test_q(self): # 校验搜索条件 q qs = [u‘白夜追凶‘, u‘大话西游‘, u‘周星驰‘, u‘张艺谋‘, u‘周星驰,吴孟达‘, u‘张艺谋,巩俐‘, u‘周星驰,大话西游‘, u‘白夜追凶,潘粤明‘] for q in qs: params = dict(q=q) f = partial(test_doubanSearch.search, params) f.description = json.dumps(params, ensure_ascii=False).encode(‘utf-8‘) yield (f,)
class check_response(): @staticmethod def check_result(response, params, expectNum=None): # 由于搜索结果存在模糊匹配的情况,这里简单处理只校验第一个返回结果的正确性 if expectNum is not None: # 期望结果数目不为None时,只判断返回结果数目 eq_(expectNum, len(response[‘subjects‘]), ‘{0}!={1}‘.format(expectNum, len(response[‘subjects‘]))) else: if not response[‘subjects‘]: # 结果为空,直接返回失败 assert False else: # 结果不为空,校验第一个结果 subject = response[‘subjects‘][0] # 先校验搜索条件tag if params.get(‘tag‘): for word in params[‘tag‘].split(‘,‘): genres = subject[‘genres‘] ok_(word in genres, ‘Check {0} failed!‘.format(word.encode(‘utf-8‘))) # 再校验搜索条件q elif params.get(‘q‘): # 依次判断片名,导演或演员中是否含有搜索词,任意一个含有则返回成功 for word in params[‘q‘].split(‘,‘): title = [subject[‘title‘]] casts = [i[‘name‘] for i in subject[‘casts‘]] directors = [i[‘name‘] for i in subject[‘directors‘]] total = title + casts + directors ok_(any(word.lower() in i.lower() for i in total), ‘Check {0} failed!‘.format(word.encode(‘utf-8‘))) @staticmethod def check_pageSize(response): # 判断分页结果数目是否正确 count = response.get(‘count‘) start = response.get(‘start‘) total = response.get(‘total‘) diff = total - start if diff >= count: expectPageSize = count elif count > diff > 0: expectPageSize = diff else: expectPageSize = 0 eq_(expectPageSize, len(response[‘subjects‘]), ‘{0}!={1}‘.format(expectPageSize, len(response[‘subjects‘])))
nosetests -v test_doubanSearch.py:test_doubanSearch --with-html --html-report={0}‘.format(report_file)
import smtplib from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart def send_mail(): # 读取测试报告内容 with open(report_file, ‘r‘) as f: content = f.read().decode(‘utf-8‘) msg = MIMEMultipart(‘mixed‘) # 添加邮件内容 msg_html = MIMEText(content, ‘html‘, ‘utf-8‘) msg.attach(msg_html) # 添加附件 msg_attachment = MIMEText(content, ‘html‘, ‘utf-8‘) msg_attachment["Content-Disposition"] = ‘attachment; filename="{0}"‘.format(report_file) msg.attach(msg_attachment) msg[‘Subject‘] = mail_subjet msg[‘From‘] = mail_user msg[‘To‘] = ‘;‘.join(mail_to) try: # 连接邮件服务器 s = smtplib.SMTP(mail_host, 25) # 登陆 s.login(mail_user, mail_pwd) # 发送邮件 s.sendmail(mail_user, mail_to, msg.as_string()) # 退出 s.quit() except Exception as e: print "Exceptioin ", e
打开nosetests运行完成后生成的测试报告,可以看出本次测试共执行了51条测试用例,50条成功,1条失败。
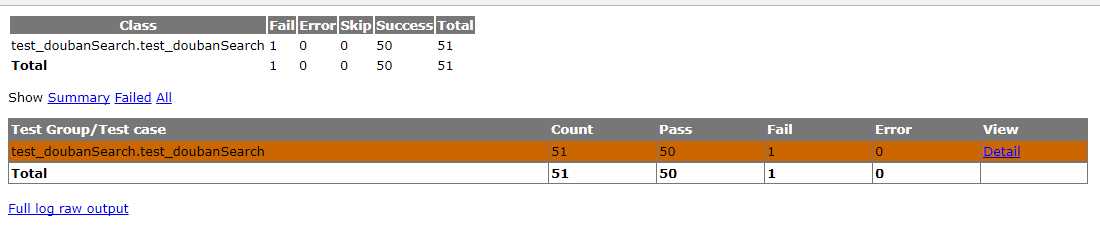
失败的用例可以看到传入的参数是:{"count": -10, "tag": "喜剧"},此时返回的结果数与我们的期望结果不一致(count为负数时,期望结果是接口报错或使用默认值20,但实际返回的结果数目是189。赶紧去给豆瓣提bug啦- -)

python test_doubanSearch.py
标签:str .json ext 使用 smt join osi 文档 参数
原文地址:http://www.cnblogs.com/lovesoo/p/7845731.html