标签:sub 文件 文件中 orm alt 设计 上传 查看 row
①WorldCount.java 中的main函数修改如下:
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置输入文本路径 FileInputFormat.addInputPath(job, new Path("/input")); //设置mp结果输出路径 FileOutputFormat.setOutputPath(job, new Path("/output/wordcount")); System.exit(job.waitForCompletion(true) ? 0 : 1); }
②导出WordCount的jar包:
export->jar file->next->next->Main class里面选择WordCount->Finish。
③使用scp将wc.jar拷贝到node1机器,创建目录:hadoop fs –mkdir /input,将shakespeare.txt上传到hdfs上,运行wc.jar文件:hadoop jar wc.jar
④使用hadoop fs -cat /output/wordcount/part-r-00000 grep|head -n 30 查看前30条输出结果: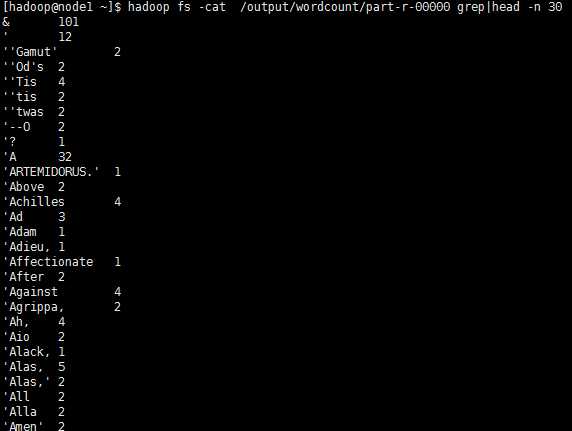
Mapreduce程序:
public class sougou3 { public static class Sougou3Map extends Mapper<Object, Text, Text, Text> { public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] vals = line.split("\t"); String uid = vals[1]; String search = vals[2]; context.write(new Text(uid), new Text(search+"|"+search.length())); } } public static class Sougou3Reduce extends Reducer<Text, Text, Text, Text> { public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { String result = ""; for (Text value : values) { String strVal = value.toString(); result += (strVal+" "); } context.write(new Text(key + "\t"), new Text(result)); } } }
输出结果:
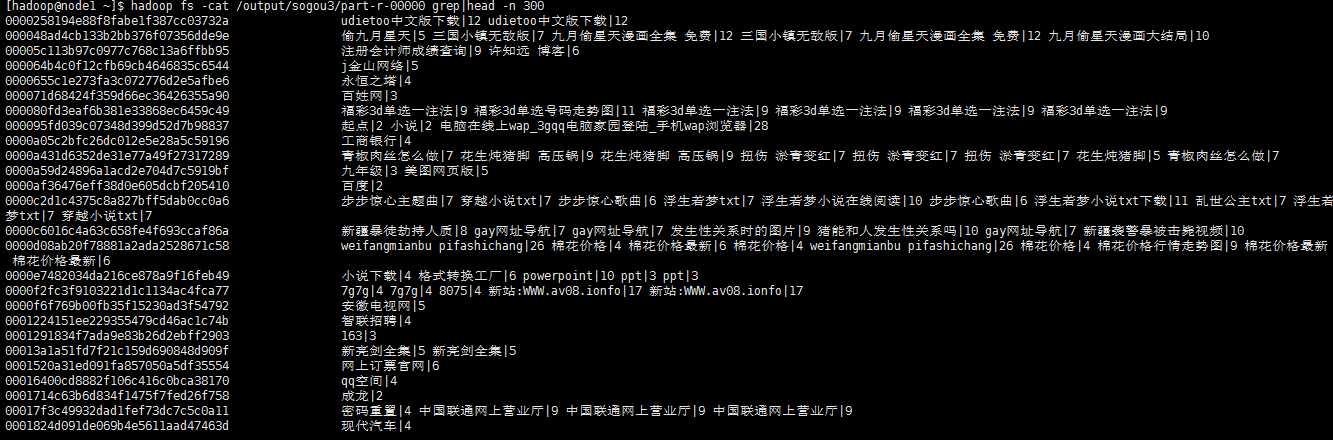 (2) 统计2011年12月30日1点到2点之间,搜索过的UID有哪些?
(2) 统计2011年12月30日1点到2点之间,搜索过的UID有哪些?Mapreduce程序:
public class sougou1 { public static class Sougou1Map extends Mapper<Object, Text, Text, Text> { public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] vals = line.split("\t"); String time = vals[0]; String uid = vals[1]; //2008-07-10 19:20:00 String formatTime = time.substring(0,4)+"-"+time.substring(4,6)+"-"+time.substring(6,8)+" " +time.substring(8,10)+":"+time.substring(10,12)+":"+time.substring(12,14); SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); Date date; try { date = sdf.parse(formatTime); Date date1 = sdf.parse("2011-12-30 01:00:00"); Date date2 = sdf.parse("2011-12-30 02:00:00"); //日期在范围区间上 if (date.getTime() > date1.getTime() && date.getTime() < date2.getTime()){ context.write(new Text(uid), new Text(formatTime)); } } catch (ParseException e) { e.printStackTrace(); } } } public static class Sougou1Reduce extends Reducer<Text, Text, Text, Text> { public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { String result = ""; for (Text value : values) { result += value.toString()+"|"; } context.write(key, new Text(result)); } } }
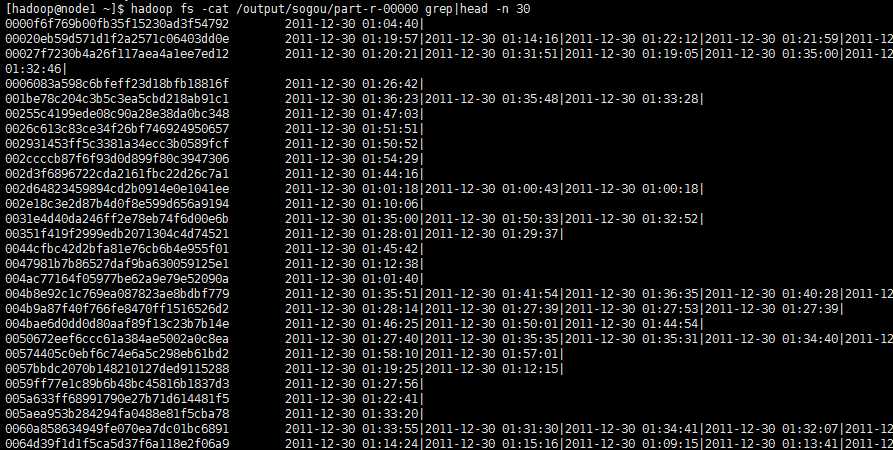
输出结果:
左边是用户id,右边分别是时间,以“|”作为分割。
Mapreduce程序:
public class sougou2 { public static class Sougou2Map extends Mapper<Object, Text, Text, IntWritable> { public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] vals = line.split("\t"); String uid = vals[1]; String search = vals[2]; if (search.equals("仙剑奇侠")){ context.write(new Text(uid), new IntWritable(1)); } } } public static class Sougou2Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int result = 0; for (IntWritable value : values) { result += value.get(); } context.write(new Text(key+"\t"), new IntWritable(result)); } } }
输出结果:
UID为:6856e6e003a05cc912bfe13ebcea8a04的用户搜索过“仙剑奇侠”共1次。
Mapreduce程序:
public class Sort { //map将输入中的value化成IntWritable类型,作为输出的key public static class Map extends Mapper<Object,Text,IntWritable,NullWritable>{ private static IntWritable data=new IntWritable(); //实现map函数 public void map(Object key,Text value,Context context) throws IOException,InterruptedException{ String line=value.toString(); data.set(Integer.parseInt(line)); context.write(data, NullWritable.get()); } } //reduce将输入中的key复制到输出数据的key上, //然后根据输入的value-list中元素的个数决定key的输出次数 //用全局linenum来代表key的位次 public static class Reduce extends Reducer<IntWritable,NullWritable,IntWritable,NullWritable>{ //实现reduce函数 public void reduce(IntWritable key,Iterable<NullWritable> values,Context context) throws IOException,InterruptedException{ for(NullWritable val:values){ context.write(key, NullWritable.get()); } } } }
输出内容为:
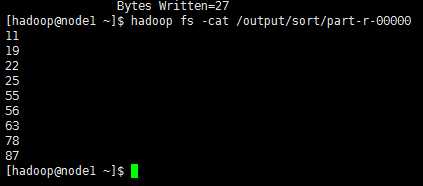
李平 87 89 98 75
张三 66 78 69 70
李四 96 82 78 90
王五 82 77 74 86
赵六 88 72 81 76
Mapreduce 程序:
public class Score { public static class ScoreMap extends Mapper<Object, Text, Text, NullWritable> { public void map(Object key, Text value, Context context) throws IOException, InterruptedException { context.write(value, NullWritable.get()); } } public static class ScoreReduce extends Reducer<Text, NullWritable, Text, IntWritable> { public void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { for (NullWritable nullWritable : values) { String line = key.toString(); String[] vals = line.split("\t"); String name = vals[0]; int val1 = Integer.parseInt(vals[1]); int val2 = Integer.parseInt(vals[2]); int val3 = Integer.parseInt(vals[3]); int average = (val1 + val2 + val3) / 3; context.write(new Text(name), new IntWritable(average)); } } } }
输出结果为
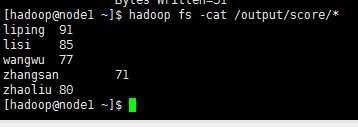
大数据(1):基于sogou.500w.utf8数据的MapReduce程序设计
标签:sub 文件 文件中 orm alt 设计 上传 查看 row
原文地址:http://www.cnblogs.com/tongkey/p/7854266.html