标签:就是 次数 遍历 ima images add temp 时间 sem
Collections 是集合的工具类,Collections.sort用于对象集合按照用户自定义的规则进行排序(常用于对list进行排序)
Arrays.sort 可以用于对象数组按照用户自定义规则排序。
eg: 本题中将字符串转成数组,然后使用Arrays.sort()
Char[] chars = s.toCharArray();
Arrays.sort(chars);
//String string = String.valueOf(chars); 转回string
Comparable: 接口位于java.lang中,通过实现compareTo()方法实现自定义排序。
compareTo() 定义在对象内部,直接调用Collections.sort(list);即可
import java.util.ArrayList; import java.util.Collections; import java.util.List; //定义一个Student类,实现Comparable接口,泛型设为Student class Student implements Comparable<Student>{ public int id ; public String name; public Student(int id, String name) { super(); this.id = id; this.name = name; } //重写接口中的comparaTo()方法 @Override public int compareTo(Student o) { //我在此定义的conparaTo()方法是以两者的id为标准进行比较,也可以对他们的其他属性进行比较 //通过改变返回值的方式(如取反等),可以自行决定排序的顺序 return (o.id-this.id); } } //测试的主类 public class CompareTest { public static void main(String[] args) { Student s1 = new Student(1,"小"); Student s2 = new Student(2,"大"); List<Student> list = new ArrayList<>(); list.add(s1); list.add(s2); System.out.println("Comparable:"); System.out.println(list.get(0).id +list.get(0).name); System.out.println(list.get(1).id +list.get(1).name); //由于Student类实现了Comparable接口,所以集合list可以直接排序 Collections.sort(list); System.out.println("=============交换后============="); System.out.println(list.get(0).id +list.get(0).name); System.out.println(list.get(1).id +list.get(1).name); } }
Comparator: 接口位于java.util中,通过实现其中compare()方法实现自定义排序。
compare定义在另一个实现Comparator的类中,通过调用Collections.sort(list, classname);调用
import java.util.Comparator; //需要导包 import java.util.ArrayList; import java.util.Collections; import java.util.List; //一个没有定义比较方式的普通类 class Student{ public int id ; public String name; public Student(int id, String name) { super(); this.id = id; this.name = name; } } //一个实现了Comparator接口的类,泛型设为我们需要进行比较排序的Student类 class Compare implements Comparator<Student>{ //重写compare()方法,参数为两个Student类型的对象 @Override public int compare(Object o1, Object o2) { //同样的,根据改变返回值的方式,我们可以自行决定排序的顺序 return (Student)o2.id-(Student)o1.id; } } //用于测试的主类 public class CompareTest { public static void main(String[] args) { Student s1 = new Student(1,"小"); Student s2 = new Student(2,"大"); List<Student> list = new ArrayList<>(); list.add(s1); list.add(s2); System.out.println("Comparator:"); System.out.println(list.get(0).id +list.get(0).name); System.out.println(list.get(1).id +list.get(1).name); //实现了Comparator接口的Compare类的一个实例对象就可以作为参数传到Collections.sort()方法中 //本没有定义比较方法的Student类的对象就可以排序了 Collections.sort(list,new Compare()); System.out.println("=============交换后============="); System.out.println(list.get(0).id +list.get(0).name); System.out.println(list.get(1).id +list.get(1).name); } }
Set keys = map.keySet(); if(keys != null){ Iterator iterator = keys.iterator(); while(iterator.hasNext()){ Object key = iterator.next(); Object value = map.get(key); } } //每次从map中取得key之后,要返回map中相关的value,比较繁琐 Set entries = map.entrySet(); if(entries != null){ Iterator iterator = entries.iterator(); while(iterator.hasNest()){ Map.Entry entry = iterator.next(); Object key = entry.getKey(); Object value = entry.getValue();//entry.setValue(); } } //可以节省队get的调用
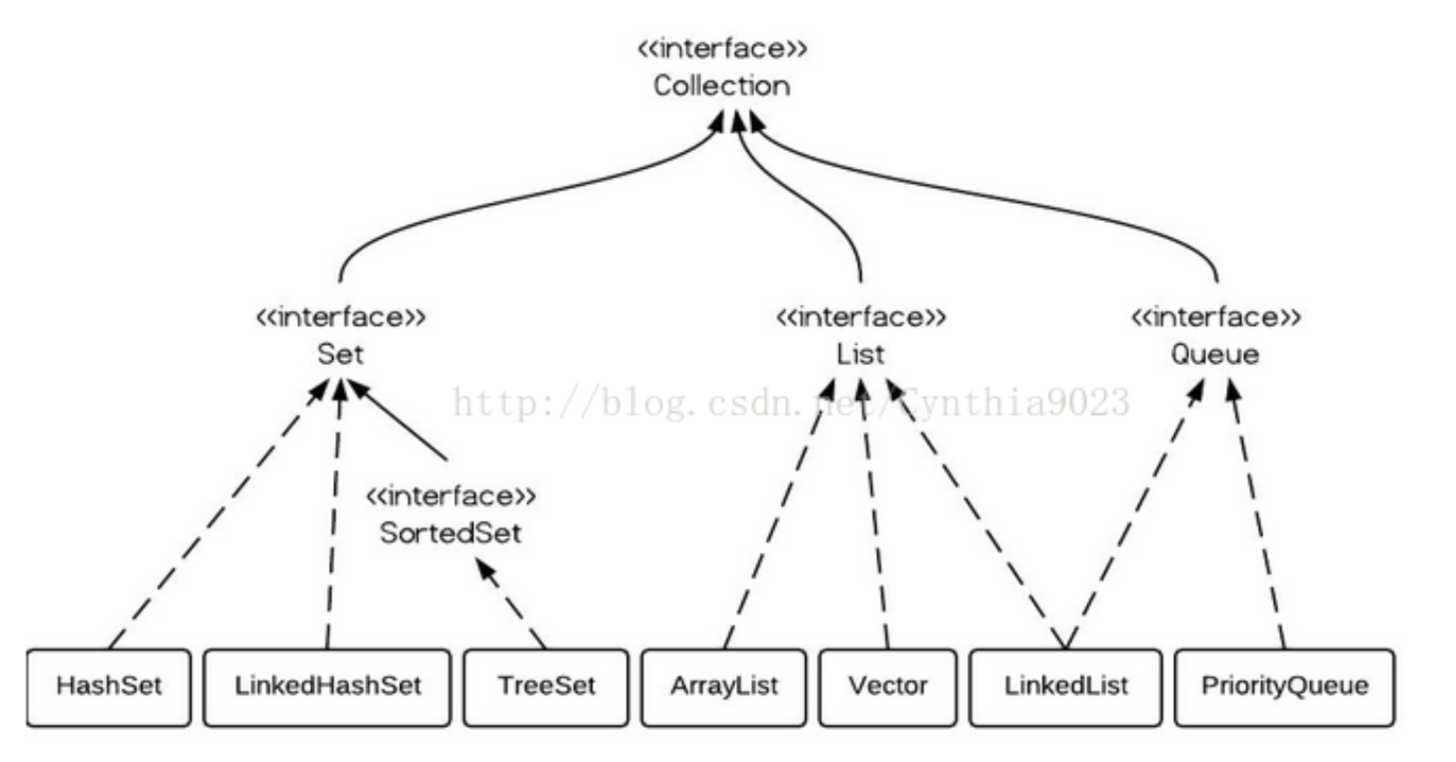
HashSet: add、remove 及contains 方法的时间复杂度是一个常量 O(1)。
TreeSet: 是使用一个红黑树来实现的。元素在set中被排好序,但是add、remove及contains方法的时间复杂度为O(log(n))。它提供了几个方法用来处理有序的set,比如first(),last(),headSet(),tailSet()等等。
LinkedHashSet: HashSet与TreeSet之间。它由一个执行hash表的链表实现,因此,它提供顺序插入。基本方法的时间复杂度为O(1)。
速度: HashSet > LinkedHashSet > TreeSet
TreeSet<Integer> tree = new TreeSet<Integer>(); tree.add(12); tree.add(63); tree.add(34); tree.add(45); Iterator<Integer> iterator = tree.iterator(); System.out.print("Tree set data: "); while (iterator.hasNext()) { System.out.print(iterator.next() + " "); }
结果: Tree set data: 12 34 45 63
Dog类:因为TreeSet是有序的,Dog对象需要实现java.lang.Comparable的compareTo()方法(应该是先实现Comparable再重写compareTo()方法),就像下面这样:
[java] view plain copy class Dog implements Comparable<Dog>{ int size; public Dog(int s) { size = s; } public String toString() { return size + ""; } @Override public int compareTo(Dog o) { return size - o.size; } }
import java.util.Iterator; import java.util.TreeSet; public class TestTreeSet { public static void main(String[] args) { TreeSet<Dog> dset = new TreeSet<Dog>(); dset.add(new Dog(2)); dset.add(new Dog(1)); dset.add(new Dog(3)); Iterator<Dog> iterator = dset.iterator(); while (iterator.hasNext()) { System.out.print(iterator.next() + " "); } } } 结果: 1 2 3
LinkedHashSet<Dog> dset = new LinkedHashSet<Dog>(); dset.add(new Dog(2)); dset.add(new Dog(1)); dset.add(new Dog(3)); dset.add(new Dog(5)); dset.add(new Dog(4)); Iterator<Dog> iterator = dset.iterator(); while (iterator.hasNext()) { System.out.print(iterator.next() + " "); } 结果: 2 1 3 5 4
49. Group Anagrams
class Solution { public List<List<String>> groupAnagrams(String[] strs) { List<List<String>> ans = new ArrayList<List<String>>(); if(strs.length == 0) return ans; HashMap<String, List<String>> map = new HashMap<>(); for(String s:strs){ char[] chars = s.toCharArray(); Arrays.sort(chars); String key = String.valueOf(chars); map.putIfAbsent(key, new ArrayList()); map.get(key).add(s); } for(String key:map.keySet()){ Collections.sort(map.get(key)); ans.add(map.get(key)); } return ans; } }
36. Valid Sudoku
class Solution { public boolean isValidSudoku(char[][] board) { for(int i = 0; i < board.length; i++){ //row if(isValid(board, i, 0, i, 8) == false) return false; //col if(isValid(board, 0, i, 8, i) == false) return false; //cube if(isValid(board, (i/3)*3, (i%3)*3, (i/3)*3+2, (i%3)*3+2) == false) return false; } return true; } boolean isValid(char[][] board, int row1, int col1, int row2, int col2){ HashSet<Character> set = new HashSet<Character>(); for(int i = row1; i <= row2; i++){ for(int j = col1; j <= col2; j++){ if(board[i][j]!=‘.‘ && set.add(board[i][j]) == false) return false; } } return true; } }
基本思路: 要对行列还有矩阵分别进行判别。
对于每一行每一列每一个矩阵分别使用一个HashSet。 注意: set.add()返回boolean,如果set中已经含有了这个值就回返回false。
最重要的是对矩阵的转换。
347. Top K Frequent Elements
// use an array to save numbers into different bucket whose index is the frequency public class Solution { public List<Integer> topKFrequent(int[] nums, int k) { Map<Integer, Integer> map = new HashMap<>(); for(int n: nums){ map.put(n, map.getOrDefault(n,0)+1); } // corner case: if there is only one number in nums, we need the bucket has index 1. List<Integer>[] bucket = new List[nums.length+1]; for(int n:map.keySet()){ int freq = map.get(n); if(bucket[freq]==null) bucket[freq] = new LinkedList<>(); bucket[freq].add(n); } List<Integer> res = new LinkedList<>(); for(int i=bucket.length-1; i>0 && k>0; --i){ if(bucket[i]!=null){ List<Integer> list = bucket[i]; res.addAll(list); k-= list.size(); } } return res; } }
public class Solution { public List<Integer> topKFrequent(int[] nums, int k) { Map<Integer, Integer> map = new HashMap<>(); for(int n: nums){ map.put(n, map.getOrDefault(n,0)+1); } PriorityQueue<Map.Entry<Integer, Integer>> maxHeap = new PriorityQueue<>((a,b)->(b.getValue()-a.getValue())); for(Map.Entry<Integer,Integer> entry: map.entrySet()){ maxHeap.add(entry); } List<Integer> res = new ArrayList<>(); while(res.size()<k){ Map.Entry<Integer, Integer> entry = maxHeap.poll(); res.add(entry.getKey()); } return res; } }
null if the map is empty.// use treeMap. Use freqncy as the key so we can get all freqencies in order public class Solution { public List<Integer> topKFrequent(int[] nums, int k) { Map<Integer, Integer> map = new HashMap<>(); for(int n: nums){ map.put(n, map.getOrDefault(n,0)+1); } TreeMap<Integer, List<Integer>> freqMap = new TreeMap<>(); for(int num : map.keySet()){ int freq = map.get(num); if(!freqMap.containsKey(freq)){ freqMap.put(freq, new LinkedList<>()); } freqMap.get(freq).add(num); } List<Integer> res = new ArrayList<>(); while(res.size()<k){ Map.Entry<Integer, List<Integer>> entry = freqMap.pollLastEntry(); res.addAll(entry.getValue()); } return res; } }
class Solution { public List<Integer> topKFrequent(int[] nums, int k) { List<Integer> ans = new ArrayList<Integer>(); Map<Integer, Integer> count = new TreeMap<Integer, Integer>(); for(int i = 0; i < nums.length; i++){ count.putIfAbsent(nums[i], 0); count.put(nums[i], count.get(nums[i])+1); } Map<Integer, List<Integer>> map = new TreeMap<>(new Comparator<Integer>(){ public int compare(Integer o1, Integer o2){ return o2 - o1; } }); for(Integer key:count.keySet()){ map.putIfAbsent(count.get(key), new ArrayList<Integer>()); map.get(count.get(key)).add(key); } for(Integer key:map.keySet()){ for(int i = 0; i < map.get(key).size(); i++){ ans.add(map.get(key).get(i)); k--; if(k == 0) return ans; } }
187. Repeated DNA Sequences
用一个长度为10的滑动窗口,记:不能用HashSet要用HashMap的value来记忆次数,要不然可能会返回重复的子字符串。
299. Bulls and Cows
Have two HashMap to maintain the characters and the frequency of it. And compare each other in the hashMap.
311. SparseMatrix Multiplication 稀疏矩阵:大部分element为0

第一行A与第一列B乘积构成了C[0][0], 第一行A与第二列B乘积构成了C[0][1]
如果用三个嵌套的循环,i(行)j(列)k(A列/B行)会TE。由于可能会有很多0存在导致一些不必要的乘积。
把对k的循环拉到第二层,对A[i][k]和B[k][j]进行判断,如果有一个是0则不需要进行循环。例如,如果A[0][0]是0,则没必要每次都将它与B[0][0] B[0][1] B[0][2]...进行相乘
class Solution{ public int[][] multiply(int[][] A, int[][] B){ int[][] ans = new int[A.length][B[0].length]; for(int i = 0; i < A.length; i++){ for(int k = 0; k < A[0].length; k++){ if(A[i][k] != 0){ for(int j = 0; j < B[0].length; j++){ if(B[k][j] != 0) ans[i][j] = ans[i][j] + A[i][k] * B[k][j]; } } } } return ans; } }
A sparse matrix can be represented as a sequence of rows, each of which is a sequence of (column-number, value) pairs of the nonzero values in the row.
To save space and running time it is critical to only store the nonzero elements. A standard representation of sparse matrices in sequential languages is to use an array with one element per row each of which contains a linked-list of the nonzero values in that row along with their column number.
| A = |
|
A = [[(0, 2.0), (1, -1.0)],
[(0, -1.0), (1, 2.0), (2, -1.0)],
[(1, -1.0), (2, 2.0), (3, -1.0)],
[(2, -1.0), (3, 2.0)]]
class Solution { public int[][] multiply(int[][] A, int[][] B) { int[][] ans = new int[A.length][B[0].length]; List [] indexA = new List[A.length];//注意是List数组,存储的是List for(int i = 0; i < A.length; i++){ List<Integer> numsA = new ArrayList<Integer>(); for(int j = 0; j < A[0].length; j++){ if(A[i][j] != 0){ numsA.add(j); numsA.add(A[i][j]);//把列号和值存储起来 } } indexA[i] = numsA;//把list放入数组中 } for(int i = 0; i < indexA.length; i++){//对每一行处理 List<Integer> numsA = indexA[i]; //拿到index[I]中List的引用 for(int p = 0; p < numsA.size() - 1; p++){//对每一行中的非0列处理 int colA = numsA.get(p); int valA = numsA.get(++p); for(int j = 0; j < B[0].length; j++){ int valB = B[colA][j];//每一行的非零列所需要进行的所有处理 ans[i][j] = ans[i][j] + valA*valB; } } } return ans; } }
380. Insert Delete GetRandom O(1)
一开始用了HashSet但是HashSet没法GetRandom(),本来使用了Iterator 但是Iterator是无序返回但是不是但是每一次都是重新按照固定顺序返回的。
用ArrayList来保存输入的数字,HashMap() key保持输入的数字,value保持数字在List中的index
remove的时候,map直接remove,将list中的最后一个值填写到value 的index上,然后删除list中的最后一个值。
public boolean remove(int val) { if(map.containsKey(val)){ int index = map.get(val); if(index < list.size() - 1){ int temp = list.get(list.size() - 1); list.set(index, temp); map.put(temp, index); } list.remove(list.size() - 1); map.remove(val); return true; }else return false; }
Integer val = (Integer) iter.next();// iter.next()会返回一个object
int value = val.intValue();//将 Integer转化成int
int value = 0; Integer val = new Integer(value);//将int转化成Integer
实例:如何写,生成随机生成出0~100中的其中一个数呢?
Math.random()返回的只是从0到1之间的小数,如果要50到100,就先放大50倍,即0到50之间,这里还是小数,如果要整数,就强制转换int,然后再加上50即为50~100.
最终代码:(int)(Math.random()*50) + 50
Random 类中的方法比较简单,每个方法的功能也很容易理解。需要说明的是,Random类中各方法生成的随机数字都是均匀分布的,也就是说区间内部的数字生成的几率是均等的。下面对这些方法做一下基本的介绍:
a. public boolean nextBoolean()
该方法的作用是生成一个随机的boolean值,生成true和false都是50%的几率。
b. public double nextDouble()
该方法的作用是生成一个随机的double值,数值介于[0,1.0)之间,这里中括号代表包含区间端点,小括号代表不包含区间端点,也就是0到1之间的随机小数,包含0而不包含1.0。
ex: [1, 2.5) double val = r.nextDouble() * 1.5 + 1;
r.nextDouble(n2-n1)+n1
c. public int nextInt()
该方法的作用是生成一个随机的int值,该值介于int的区间,也就是-2的31次方到2的31次方-1之间。
d. public int nextInt(int n)
该方法的作用是生成一个随机的int值,该值介于[0,n)的区间,也就是0到n之间的随机int值,包含0而不包含n。
如果想生成指定区间的int值,也需要进行一定的数学变换,具体可以参看下面的使用示例中的代码。
ex: [-3, 15) int val = r.nextInt(18) - 3;
标签:就是 次数 遍历 ima images add temp 时间 sem
原文地址:http://www.cnblogs.com/ninalei/p/7859467.html