标签:target mes utf8 windows http lib text tput 语法错误
Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。整体架构大致如下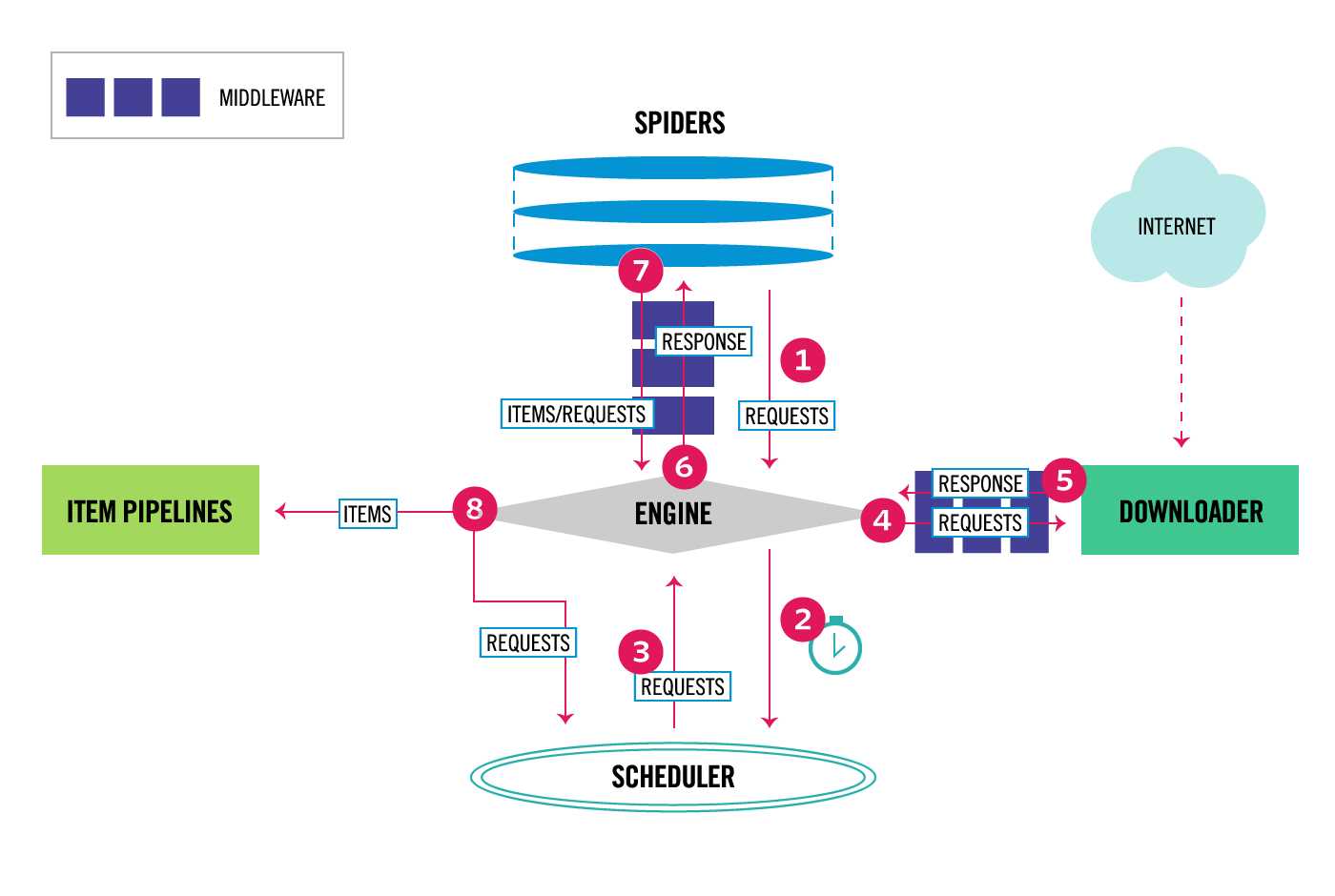
The data flow in Scrapy is controlled by the execution engine, and goes like this:
process_request()).process_response()).process_spider_input()).process_spider_output()).
Components:
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
官网链接:https://docs.scrapy.org/en/latest/topics/architecture.html
#Windows平台 1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs 3、pip3 install lxml 4、pip3 install pyopenssl 5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/ 6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl 8、pip3 install scrapy #Linux平台 1、pip3 install scrapy
#1 查看帮助 scrapy -h scrapy <command> -h #2 有两种命令:其中Project-only必须切到项目文件夹下才能执行,而Global的命令则不需要 Global commands: startproject #创建项目 genspider #创建爬虫程序 settings #如果是在项目目录下,则得到的是该项目的配置 runspider #运行一个独立的python文件,不必创建项目 shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否 fetch #独立于程单纯地爬取一个页面,可以拿到请求头 view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求 version #scrapy version 查看scrapy的版本,scrapy version -v查看scrapy依赖库的版本 Project-only commands: crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False check #检测项目中有无语法错误 list #列出项目中所包含的爬虫名 edit #编辑器,一般不用 parse #scrapy parse url地址 --callback 回调函数 #以此可以验证我们的回调函数是否正确 bench #scrapy bentch压力测试 #3 官网链接 https://docs.scrapy.org/en/latest/topics/commands.html

#1、执行全局命令:请确保不在某个项目的目录下,排除受该项目配置的影响 scrapy startproject MyProject cd MyProject scrapy genspider baidu www.baidu.com scrapy settings --get XXX #如果切换到项目目录下,看到的则是该项目的配置 scrapy runspider baidu.py scrapy shell https://www.baidu.com response response.status response.body view(response) scrapy view https://www.taobao.com #如果页面显示内容不全,不全的内容则是ajax请求实现的,以此快速定位问题 scrapy fetch --nolog --headers https://www.taobao.com scrapy version #scrapy的版本 scrapy version -v #依赖库的版本 #2、执行项目命令:切到项目目录下 scrapy crawl baidu scrapy check scrapy list scrapy parse http://quotes.toscrape.com/ --callback parse scrapy bench
project_name/ scrapy.cfg project_name/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py 爬虫1.py 爬虫2.py 爬虫3.py
文件说明:
注意:一般创建爬虫文件时,以网站域名命名
import scrapy class XiaoHuarSpider(scrapy.spiders.Spider): name = "xiaohuar" # 爬虫名称 ***** allowed_domains = ["xiaohuar.com"] # 允许的域名 start_urls = [ "http://www.xiaohuar.com/hua/", # 其实URL ] def parse(self, response): # 访问起始URL并获取结果后的回调函数
import sys,os sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030‘)
#在项目目录下新建:entrypoint.py from scrapy.cmdline import execute execute([‘scrapy‘, ‘crawl‘, ‘xiaohua‘])
强调:配置文件的选项必须是大写,如X=‘1‘
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class BaiduSpider(CrawlSpider): name = ‘xiaohua‘ allowed_domains = [‘www.xiaohuar.com‘] start_urls = [‘http://www.xiaohuar.com/v/‘] # download_delay = 1 rules = ( Rule(LinkExtractor(allow=r‘p\-\d\-\d+\.html$‘), callback=‘parse_item‘,follow=True,), ) def parse_item(self, response): if url: print(‘======下载视频==============================‘, url) yield scrapy.Request(url,callback=self.save) def save(self,response): print(‘======保存视频==============================‘,response.url,len(response.body)) import time import hashlib m=hashlib.md5() m.update(str(time.time()).encode(‘utf-8‘)) m.update(response.url.encode(‘utf-8‘)) filename=r‘E:\\mv\\%s.mp4‘ %m.hexdigest() with open(filename,‘wb‘) as f: f.write(response.body)
https://docs.scrapy.org/en/latest/topics/spiders.html
#1 //与/ #2 text #3、extract与extract_first:从selector对象中解出内容 #4、属性:xpath的属性加前缀@ #4、嵌套查找 #5、设置默认值 #4、按照属性查找 #5、按照属性模糊查找 #6、正则表达式 #7、xpath相对路径 #8、带变量的xpath
response.selector.css() response.selector.xpath() 可简写为 response.css() response.xpath() #1 //与/ response.xpath(‘//body/a/‘)# response.css(‘div a::text‘) >>> response.xpath(‘//body/a‘) #开头的//代表从整篇文档中寻找,body之后的/代表body的儿子 [] >>> response.xpath(‘//body//a‘) #开头的//代表从整篇文档中寻找,body之后的//代表body的子子孙孙 [<Selector xpath=‘//body//a‘ data=‘<a href="image1.html">Name: My image 1 <‘>, <Selector xpath=‘//body//a‘ data=‘<a href="image2.html">Name: My image 2 <‘>, <Selector xpath=‘//body//a‘ data=‘<a href=" image3.html">Name: My image 3 <‘>, <Selector xpath=‘//body//a‘ data=‘<a href="image4.html">Name: My image 4 <‘>, <Selector xpath=‘//body//a‘ data=‘<a href="image5.html">Name: My image 5 <‘>] #2 text >>> response.xpath(‘//body//a/text()‘) >>> response.css(‘body a::text‘) #3、extract与extract_first:从selector对象中解出内容 >>> response.xpath(‘//div/a/text()‘).extract() [‘Name: My image 1 ‘, ‘Name: My image 2 ‘, ‘Name: My image 3 ‘, ‘Name: My image 4 ‘, ‘Name: My image 5 ‘] >>> response.css(‘div a::text‘).extract() [‘Name: My image 1 ‘, ‘Name: My image 2 ‘, ‘Name: My image 3 ‘, ‘Name: My image 4 ‘, ‘Name: My image 5 ‘] >>> response.xpath(‘//div/a/text()‘).extract_first() ‘Name: My image 1 ‘ >>> response.css(‘div a::text‘).extract_first() ‘Name: My image 1 ‘ #4、属性:xpath的属性加前缀@ >>> response.xpath(‘//div/a/@href‘).extract_first() ‘image1.html‘ >>> response.css(‘div a::attr(href)‘).extract_first() ‘image1.html‘ #4、嵌套查找 >>> response.xpath(‘//div‘).css(‘a‘).xpath(‘@href‘).extract_first() ‘image1.html‘ #5、设置默认值 >>> response.xpath(‘//div[@id="xxx"]‘).extract_first(default="not found") ‘not found‘ #4、按照属性查找 response.xpath(‘//div[@id="images"]/a[@href="image3.html"]/text()‘).extract() response.css(‘#images a[@href="image3.html"]/text()‘).extract() #5、按照属性模糊查找 response.xpath(‘//a[contains(@href,"image")]/@href‘).extract() response.css(‘a[href*="image"]::attr(href)‘).extract() response.xpath(‘//a[contains(@href,"image")]/img/@src‘).extract() response.css(‘a[href*="imag"] img::attr(src)‘).extract() response.xpath(‘//*[@href="image1.html"]‘) response.css(‘*[href="image1.html"]‘) #6、正则表达式 response.xpath(‘//a/text()‘).re(r‘Name: (.*)‘) response.xpath(‘//a/text()‘).re_first(r‘Name: (.*)‘) #7、xpath相对路径 >>> res=response.xpath(‘//a[contains(@href,"3")]‘)[0] >>> res.xpath(‘img‘) [<Selector xpath=‘img‘ data=‘<img src="image3_thumb.jpg">‘>] >>> res.xpath(‘./img‘) [<Selector xpath=‘./img‘ data=‘<img src="image3_thumb.jpg">‘>] >>> res.xpath(‘.//img‘) [<Selector xpath=‘.//img‘ data=‘<img src="image3_thumb.jpg">‘>] >>> res.xpath(‘//img‘) #这就是从头开始扫描 [<Selector xpath=‘//img‘ data=‘<img src="image1_thumb.jpg">‘>, <Selector xpath=‘//img‘ data=‘<img src="image2_thumb.jpg">‘>, <Selector xpath=‘//img‘ data=‘<img src="image3_thumb.jpg">‘>, <Selector xpa th=‘//img‘ data=‘<img src="image4_thumb.jpg">‘>, <Selector xpath=‘//img‘ data=‘<img src="image5_thumb.jpg">‘>] #8、带变量的xpath >>> response.xpath(‘//div[@id=$xxx]/a/text()‘,xxx=‘images‘).extract_first() ‘Name: My image 1 ‘ >>> response.xpath(‘//div[count(a)=$yyy]/@id‘,yyy=5).extract_first() #求有5个a标签的div的id ‘images‘
https://docs.scrapy.org/en/latest/topics/selectors.html
https://docs.scrapy.org/en/latest/topics/items.html
https://docs.scrapy.org/en/latest/topics/item-pipeline.html
https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
https://docs.scrapy.org/en/latest/topics/spider-middleware.html
1、 scrapy startproject Amazon cd Amazon scrapy genspider spider_goods www.amazon.cn 2、settings.py ROBOTSTXT_OBEY = False #请求头 DEFAULT_REQUEST_HEADERS = { ‘Referer‘:‘https://www.amazon.cn/‘, ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36‘ } #打开注释 HTTPCACHE_ENABLED = True HTTPCACHE_EXPIRATION_SECS = 0 HTTPCACHE_DIR = ‘httpcache‘ HTTPCACHE_IGNORE_HTTP_CODES = [] HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage‘ 3、items.py class GoodsItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() #商品名字 goods_name = scrapy.Field() #价钱 goods_price = scrapy.Field() #配送方式 delivery_method=scrapy.Field() 4、spider_goods.py # -*- coding: utf-8 -*- import scrapy from Amazon.items import GoodsItem from scrapy.http import Request from urllib.parse import urlencode class SpiderGoodsSpider(scrapy.Spider): name = ‘spider_goods‘ allowed_domains = [‘www.amazon.cn‘] # start_urls = [‘http://www.amazon.cn/‘] def __int__(self,keyword=None,*args,**kwargs): super(SpiderGoodsSpider).__init__(*args,**kwargs) self.keyword=keyword def start_requests(self): url=‘https://www.amazon.cn/s/ref=nb_sb_noss_1?‘ paramas={ ‘__mk_zh_CN‘: ‘亚马逊网站‘, ‘url‘: ‘search - alias = aps‘, ‘field-keywords‘: self.keyword } url=url+urlencode(paramas,encoding=‘utf-8‘) yield Request(url,callback=self.parse_index) def parse_index(self, response): print(‘解析索引页:%s‘ %response.url) urls=response.xpath(‘//*[contains(@id,"result_")]/div/div[3]/div[1]/a/@href‘).extract() for url in urls: yield Request(url,callback=self.parse_detail) next_url=response.urljoin(response.xpath(‘//*[@id="pagnNextLink"]/@href‘).extract_first()) print(‘下一页的url‘,next_url) yield Request(next_url,callback=self.parse_index) def parse_detail(self,response): print(‘解析详情页:%s‘ %(response.url)) item=GoodsItem() # 商品名字 item[‘goods_name‘] = response.xpath(‘//*[@id="productTitle"]/text()‘).extract_first().strip() # 价钱 item[‘goods_price‘] = response.xpath(‘//*[@id="priceblock_ourprice"]/text()‘).extract_first().strip() # 配送方式 item[‘delivery_method‘] = ‘‘.join(response.xpath(‘//*[@id="ddmMerchantMessage"]//text()‘).extract()) return item 5、自定义pipelines #sql.py import pymysql import settings MYSQL_HOST=settings.MYSQL_HOST MYSQL_PORT=settings.MYSQL_PORT MYSQL_USER=settings.MYSQL_USER MYSQL_PWD=settings.MYSQL_PWD MYSQL_DB=settings.MYSQL_DB conn=pymysql.connect( host=MYSQL_HOST, port=int(MYSQL_PORT), user=MYSQL_USER, password=MYSQL_PWD, db=MYSQL_DB, charset=‘utf8‘ ) cursor=conn.cursor() class Mysql(object): @staticmethod def insert_tables_goods(goods_name,goods_price,deliver_mode): sql=‘insert into goods(goods_name,goods_price,delivery_method) values(%s,%s,%s)‘ cursor.execute(sql,args=(goods_name,goods_price,deliver_mode)) conn.commit() @staticmethod def is_repeat(goods_name): sql=‘select count(1) from goods where goods_name=%s‘ cursor.execute(sql,args=(goods_name,)) if cursor.fetchone()[0] >= 1: return True if __name__ == ‘__main__‘: cursor.execute(‘select * from goods;‘) print(cursor.fetchall()) #pipelines.py from Amazon.mysqlpipelines.sql import Mysql class AmazonPipeline(object): def process_item(self, item, spider): goods_name=item[‘goods_name‘] goods_price=item[‘goods_price‘] delivery_mode=item[‘delivery_method‘] if not Mysql.is_repeat(goods_name): Mysql.insert_table_goods(goods_name,goods_price,delivery_mode) 6、创建数据库表 create database amazon charset utf8; create table goods( id int primary key auto_increment, goods_name char(30), goods_price char(20), delivery_method varchar(50) ); 7、settings.py MYSQL_HOST=‘localhost‘ MYSQL_PORT=‘3306‘ MYSQL_USER=‘root‘ MYSQL_PWD=‘123‘ MYSQL_DB=‘amazon‘ #数字代表优先级程度(1-1000随意设置,数值越低,组件的优先级越高) ITEM_PIPELINES = { ‘Amazon.mysqlpipelines.pipelines.mazonPipeline‘: 1, } #8、在项目目录下新建:entrypoint.py from scrapy.cmdline import execute execute([‘scrapy‘, ‘crawl‘, ‘spider_goods‘,‘-a‘,‘keyword=iphone8‘])
https://pan.baidu.com/s/1boCEBT1
标签:target mes utf8 windows http lib text tput 语法错误
原文地址:http://www.cnblogs.com/bingabcd/p/7859612.html
