标签:arc 处理器 性能 响应 自我评价 重要 信息 之间 pre
随机访问存储器
随机访问寄存器(RAM)分为静态随机访问寄存器(SRAM)和动态随机访问寄存器(DRAM)。静态RAM可以作为高速缓存寄存器,动态RAM可以用作主存以及图形系统的帧缓冲区。静态RAM将每一个位存储在一个双稳态的存储器单元里,构成静态RAM 的电路可以无限期的保持在两个不同的电压配置或状态之一。动态RAM将每一个位存储为对电容的充电,所以动态RAM要比静态RAM对干扰的敏感度更高。构成动态RAM的电路被干扰后就不会恢复了。
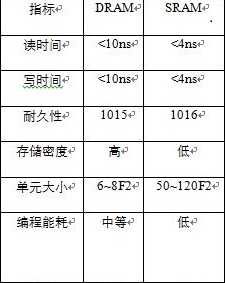
传统的DRAM
常规DRAM芯片中的单元被分成了d个超单位(supercall),每个超单位都是由w个DRAM单元组成的。一个d*w的DRAM总共存储了dw位信息。超单元被组织成一个r行r列的长方形矩阵列,rc=d。每个DRAM被连接到存储控制器这个电路,该电路能一次传w位到每个DRAM芯片或一次从每个DRAM芯片传出w位。下图是一个128位16*8的DRAM芯片的高级视图。
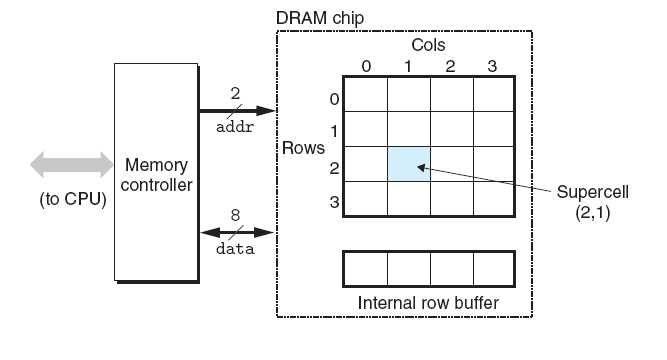
要读取图中的超单元(2,1),存储控制器将把2发送出去,DRAM的响应是将2行的整个内容都拷贝到内部缓冲区。接下来,存储控制器将发送1,DRAM的响应是从缓冲区中拷贝出单元(2,1)中的- 存储器模块
非易失性存储器
非易失性存储器不同于DRAM与SRAM,它在断电后也仍然可以保存它的信息。ROM和闪存就是非易失性存储器。
ROM以能够被重编程的次数和它们进行重编程所用的机制来区分的
可编程ROM (PROM):只能被编程一次。
可擦写可编程ROM(EPROM):EPROM能够被擦写和重编程的次数的数量级可以达到1000次。
电子可擦除PROM(EEPROM):EEPROM能够被擦写和重编程的次数的数量级可以达到100000次。
闪存:闪存是基于EEPROM的非易失性存储器,是一种较为普遍的非易失性存储器。
访问主存
数据流通过称为总线的共享电子电路在处理器和DRAM主存之间来来回回。每次CPU与主存之间的数据都是由总线事务来完成的,总线事务包括读事务和写事务。
一个计算机程序通常具有良好的局部性,也就是说,它们倾向于引用于其他最近引用过的数据项的数据项,或者最近引用过的数据项本身。局部性通常有两种不同的形式:时间局部性和空间局部性。
一个连续向量中,每隔k个元素进行访问,就被称为步长为k的引用模式。步长为的引用模式是程序中空间局部性常见和重要的来源。一般而言,随着步长的增加,空间局部性下降。
所有的现代计算机系统中都使用存储器结构层次来使得软件和硬件互相补充。
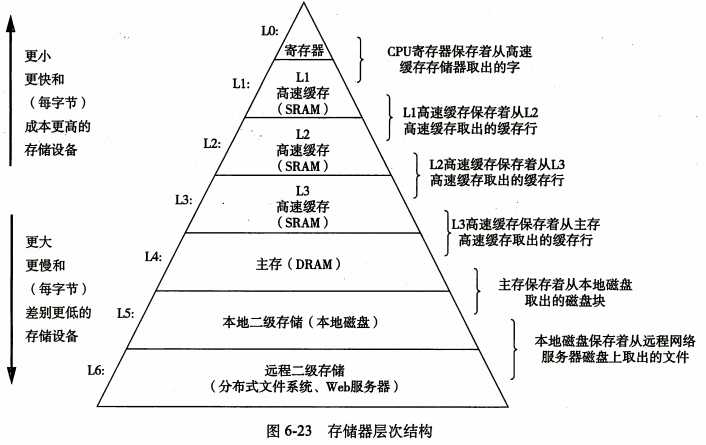
早期计算机系统的存储结构只有三层:CPU寄存器、DRAM主存储器和磁盘存储。不过,由于CPU和主存之间逐渐增大的距离,系统设计者被迫在CPU寄存器文件和主存之间插入了一个小的SRAM高速缓存存储器,称为L1高速缓存。随着CPU和主存之间的性能差距不断增大,系统设计者在L1高速缓存更大的高速缓存,称为L2高速缓存。有些现代计算机还包括一个更大的高速缓存,称为L3缓存。
通用的高速缓存存储器结构
一般而言,高速缓存的结构可以用元组(S,E,B,m)来描述。高速缓存的大小(或容量)C指的是所有块的大小的和。标记位和有效位不包括在内。因此,C=(SE)B。
直接映射高速缓存
根据E(每个组的高速缓存行数)高速缓存被分为不同的类。每个组只有一行(E=1)的高速缓存称为直接映射高速缓存。
组相联高速缓存
直接映射高速缓存中冲突不命中造成的问题是源于每个组只有一行这个限制,组相联高速缓存放松了这条限制,所以每个组都保存多余一个的高速缓存行。
全相联高速缓存
一个全相联高速缓存是由一个包含所有高速缓存行的组。
- [20155203](http://www.cnblogs.com/xhwh/p/7822561.html)
- 结对学习内容
课下练习、一起读书、一起研究课下测试。| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 500/1000 | 3/7 | 22/60 | |
| 第四周 | 300/1300 | 2/9 | 30/90 | |
| 第五周 | 200/1500 | 2/11 | 10/100 | |
| 第六周 | 200/1700 | 2/13 | 10/110 | |
| 第七周 | 302/2020 | 1/14 | 10/120 | |
| 第八周 | 892/2912 | 1/14 | 10/130 | |
| 第九周 | 892/2912 | 3/17 | 10/140 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
计划学习时间:10小时
实际学习时间:10小时
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)
2017-2018-1 20155204 《信息安全系统设计基础》第八周学习总结
标签:arc 处理器 性能 响应 自我评价 重要 信息 之间 pre
原文地址:http://www.cnblogs.com/20155204wh/p/7860549.html