标签:ase list back eal 特征 文件名 技术分享 cto logs
一、kNN算法
1、kNN算法是机器学习的入门算法,其中不涉及训练,主要思想是计算待测点和参照点的距离,选取距离较近的参照点的类别作为待测点的的类别。
2,距离可以是欧式距离,夹角余弦距离等等。
3,k值不能选择太大或太小,k值含义,是最后选取距离最近的前k个参照点的类标,统计次数最多的记为待测点类标。
4,欧式距离公式:
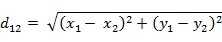
二、关于kNN实现手写数字识别
1,手写数字训练集测试集的数据格式,本篇文章说明的是《机器学习实战》书提供的文件,将所有数字已经转化成32*32灰度矩阵。
三、代码结构构成
1,data_Prepare.py :在这个文件放数据处理的函数,最终返回合适格式的数据集
2,kNN_Algorithm.py :在这个文件中存放kNN分类算法的核心函数,即执行决策的分类函数
3,testknn_Test.py :这个文件用于测试一波数据,计算函数的错误率
四、代码如下
1,data_Prepare.py
1 import numpy as np 2 def img2_vector(filename): 3 return_vect = np.zeros((1,1024)) 4 fr = open(filename) 5 for i in range(32): 6 linestr = fr.readline() 7 for j in range(32): 8 return_vect[0,32*i+j] = int(linestr[j]) 9 return return_vect
解释:可以看出返回一个1行1024列的向量,这是把一个图像的32*32展开表示成一行,为后面计算欧式距离做准备。
2,kNN_Algorithm.py
1 #导入kNN算法所需的两个模块,(1)numpy科学计算包(2)operator运算符模块 2 import numpy as np 3 import operator 4 5 #定义k近邻算法函数classify0,[参数说明:inX待预测的对象,dataset训练数据,labels训练数据对应的标签,选取的前k相近] 6 def classidy0(inX,dataset,labels,k): 7 8 #1,计算距离 9 dataset_size = dataset.shape[0] 10 diff_mat = np.tile(inX,(dataset_size,1))-dataset 11 sqdiff_mat = diff_mat**2 12 sq_distances = sqdiff_mat.sum(axis=1) 13 distances = sq_distances**0.5 14 15 #2,按递增排序 16 sorted_distances_index = distances.argsort() 17 18 #3,选择距离最近的前k个点,并且计算它们类别的次数排序 19 class_count = {} 20 for i in range(k): 21 vote_label = labels[sorted_distances_index[i]] 22 class_count[vote_label] = class_count.get(vote_label,0) + 1 23 sorted_class_count = sorted(class_count.items(),key=operator.itemgetter(1),reverse=True) 24 25 #4,返回前k个里面统计的最高次类别作为预测类别 26 return sorted_class_count[0][0]
解释:此函数是分类函数,四个参数,定义k近邻算法函数classify0,[参数说明:inX待预测的对象,dataset训练数据,labels训练数据对应的标签,选取的前k相近]。最后会返回分类的类别。
3,testknn_Test.py
1 from os import listdir #列出给定目录的文件名# 2 import kNN_Algorithm 3 import numpy as np 4 import data_Prepare 5 def class_test(): 6 7 #获取训练集目录下的所有文件# 8 labels = [] 9 train_file_list = listdir(‘trainingDigits‘) 10 m_train = len(train_file_list) 11 train_mat = np.zeros((m_train,1024)) 12 for i in range(m_train): 13 file_str = train_file_list[i] 14 #filename1 = ‘trainingDigits/‘+file_str# 15 file_name = file_str.split(‘.‘)[0] 16 class_num = file_name.split(‘_‘)[0] 17 labels.append(class_num) #训练集所有文件对应的分类label# 18 train_mat[i,:]=data_Prepare.img2_vector(‘trainingDigits/%s‘ %file_str) #每个训练集特征# 19 20 test_file_list = listdir(‘testDigits‘) 21 error_count = 0.0 22 m_test = len(test_file_list) 23 24 for i in range(m_test): 25 file_str = test_file_list[i] 26 #filename2 = ‘testDigits/‘+file_str 27 file_name = file_str.split(‘.‘)[0] 28 class_num = file_name.split(‘_‘)[0] 29 vector_under_test = data_Prepare.img2_vector(‘testDigits/%s‘ %file_str) 30 classifier_result = kNN_Algorithm.classidy0(vector_under_test,train_mat,labels,3) #进行一次测试# 31 print("the classifier came back with:%d, the real answer is : %d" %(int(classifier_result),int(class_num))) 32 if (classifier_result!=class_num):error_count+=1 33 34 print(‘\n the total number of errors is : %d‘ %error_count) 35 print(‘\n the total error rate is : %f‘%(error_count/float(m_test)))
解释:可以看出这个代码是一个测试函数,写的略显复杂,真实的意思就是循环调用第二个函数,计算错误率。
五、其余说明
限制:本代码手写数字识别,图片格式有局限性,所以若自己做相关项目,应该处理图片数据。
建议:建议仅参考第二个文件,即分类文件,这是整个算法的核心。然后可以用自己的方法用自己的数据,对算法稍作更改即可使用。
标签:ase list back eal 特征 文件名 技术分享 cto logs
原文地址:http://www.cnblogs.com/jane-ape/p/python.html