标签:量化 分割 适用于 包含 分布 分数 内容 无法 过程
1.经常使用决策树处理分类问题,决策树也是最经常使用的数据挖掘算法。
2.kNN可以完成很多分类任务,最大的缺点是无法给出数据的内在含义,决策树的优势在于数据形式容易理解。
3.1决策树的构造
决策树的优点:计算复杂度不高,输出结果易于理解,对中间值缺失不敏感,可以处理不相关特征数据。
缺点:可能会产生过度匹配问题。
适用数据类型:数值型和标称型。
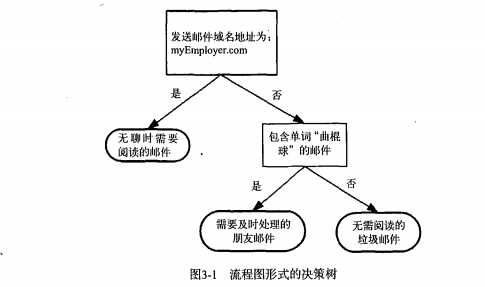
构造决策树时,解决的第一个问题是,必须评估每一个特征找出划分数据分类时起决定性作用的特征。
完成后,原始数据被划分为几个数据子集,这些数据子集会分布在第一个决策点的所有分支上。如果某个分支下的数据属于同一类型,则当前无需阅读的垃圾邮件已经正确的划分数据分类,无需进一步对数据进行分割。如果数据子集的数据不属于同一类型,则需要重新划分数据子集的过程。
划分数据子集的算法与划分原始数据的算法相同,直到所有相同类型的数据均在一个数据子集内。
创建分支的伪代码函数createBranch():
检测数据集中的每一个子项是否属于同一分类 If so return 类标签; Else 寻找划分数据集的最好特征 划分数据集 创建分支节点 for 每个划分的子集 调用函数createBranch并增加返回结果到分支节点中 return 分支节点
createBranch()是一个递归函数,在倒数第二行直接调用它自己。
决策树一般流程:
(1).收集数据:可以使用任何方法
(2).准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化。
(3).分析数据:可以使用任何方法,构造树完成之后,我们应检查图形是否符合预期。
(4).训练算法:构造树的数据结构
(5).测试算法:使用经验计算错误率。
(6).使用算法:此步骤可以使用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义。
依据某个属性划分数据将会产生4个可能的值,我们将把数据划分成4块,并创建4个不同的分支。本书将使用ID3算法划分数据集,该算法处理如何划分数据集,何时停止划分数据集。每次划分数据集时我们只选取一个特征属性,如果训练集中存在20个特征,第一次选择哪个特征作为划分的参考属性是个问题。
表3-1的数据包含5个海洋动物,特征包括:不浮出水面是否可以生存,以及是否有脚蹼。将动物分为两类:鱼类和非鱼类。现在要决定依据哪个特征划分数据。回答这个问题前,必须采用量化方法判断如何划分数据。

3.1.1信息增益
划分数据的大原则是:将无序的数据变得更加有序。组织杂乱无章数据的一种方法就是使用信息论度量信息,信息论是量化处理信息的分支科学。可以在划分数据前用信息论量化度量信息的内容。
在划分数据之前之后信息发生的变化称为信息增益。知道如何计算信息增益,就可以计算每个特征值划分数据集获得信息增益,获得信息增益最高的特征就是最好的选择。
熵定义为信息的期望值。如果待分类的事物划分在多个分类中,则符号xi的信息定义为
l(xi) = -log2p(xi)
其中p(xi)是选择该分类的概率。
标签:量化 分割 适用于 包含 分布 分数 内容 无法 过程
原文地址:http://www.cnblogs.com/keye/p/7912550.html