标签:绑定 获得 堆栈 gdb 别人 导出 定位 内存 判断
前言:在调试多流拥塞调度下载的过程中,出现了下载一半时卡住的现象,几经查看,在看遍了不同的现象后,在周末时发现是模拟的终端(一个板子上用DPDK实现)网卡发送包错误,当打开DPDK调试日志后,出现了更扑朔迷离的现象,就此展开本文。
接着终端网卡发送失败说起,在发送失败后,打开了各个库以及驱动的调试信息:
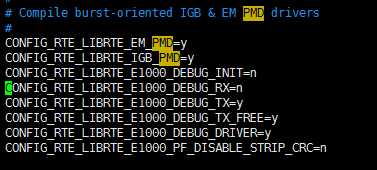
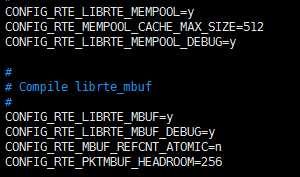
在打开这些日志时,直接在运行了一会儿后进程直接退出了,然后查看DPDK日志,看到了另一个狐疑的现象:
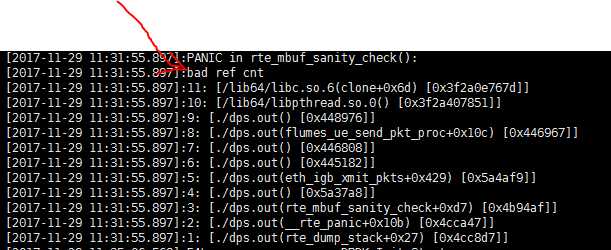
-_-|| 这可倒好,网卡发送失败的信息还没看到,就开了个日志进程还退出了,在测试了几次之后,确定这个问题是必现的。(此时心中有无数只马,之前的版本明明跑得好好的),虽然在此处已经明确看到ref cnt错误,但是抱着一线希望编译了老的版本再测试,结果,现象一模一样,这时问题就麻烦了。
看上面的结果就会产生疑惑了,一个是以前的事实,一个是如今的事实,截然相反。不禁会怀疑现在,也会怀疑以前,但更多的是现在。疑惑1:
疑惑1:为什么相同的版本在我们以前的测试中没有问题,在这个新的环境下,出现这个问题呢?
很自然,就会先想到是不是环境不同导致的。之前测试的板子是一个8核的、使用千兆网卡的环境,现在使用的是9700板卡搭载万兆网卡的环境,莫非是DPDK在某些细节处有不同的适配?所以接下来roadmap->
此时当然最快的办法就是使用以前的环境再跑一次试试看,然而以前的环境已经没有了,重新获得可用环境并非易事。再进一步判断的话,是在发送驱动出错的,谨慎的排除CPU的干扰,而把环境差异定位在网卡上(其实也没办法了,没有旧环境咯)。
所以DPDK绑定的网卡不使用万兆卡,而使用板子上的千兆卡(幸亏有2个)。姑且认为这样就和旧的环境一致了。测试结果是:现象是一模一样。这样,两种网卡的驱动都表现出一致的结果,可以排除环境的问题。
在排除了环境的干扰后,暂且放下第一个疑问,准备重点看一下这个bad ref cnt错误。 根据日志中的堆栈,找到了这个错误的地方:
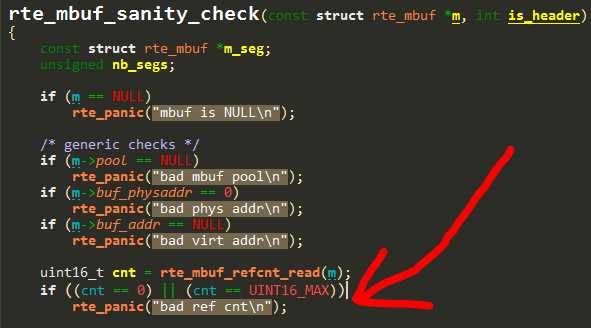
也就是说mbuf的引用计数出错了。根据我们的了解,mbuf引用计数在释放的时候为0很可能是重复释放导致的。
这个时候怀疑我们在代码中的某个异常处理流程存在问题,然后又仔细梳理了一下所有释放的地址,并没有找到存在可疑的地方(对于隐藏的BUG,有时能看出来,然鹅多数时候都看不出来 -_-)。
这个时候的逻辑会受困于两个方向:
在代码逻辑梳理了几遍仍然没发现重大嫌疑后,决定往第二个方向试试。
释放报文只有两种途径,一种是我们自己的逻辑代码释放,另一种是驱动发送完数据后释放。所以我们封装了驱动的释放函数,在发送时,记录信息。
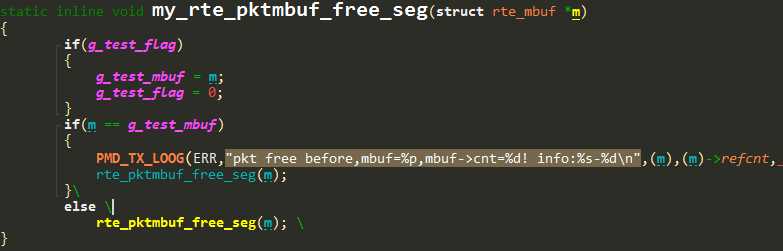
这样在驱动发送时,会打印mbuf的地址和引用计数。当进程又退出时,导出日志,发现释放mbuf出错的地址和第一个释放的地址相同。
PMD: ixgbe_xmit_pkts(): pkt free before,mbuf=0x7f2c49f79c40,mbuf->cnt=1! info:ixgbe_xmit_pkts-813
PMD: ixgbe_xmit_pkts(): pkt free before,mbuf=0x7f2c49f79c40,mbuf->cnt=0! info:ixgbe_xmit_pkts-813 注意到第二次mbuf被驱动释放,其引用计数已经变成0了。按照网卡发送的过程,第二次释放必定又有新的包需要被发送。第一次驱动释放却是正常的,所以,做了这样的假设:
如果沿着这个假设,也就是说这个mbuf如果被重用,肯定是应该看到被重新申请出来的。查看日志,GDB断点,无论如何,我们没有看到这个mbuf被重新分配出来过。出现了疑惑2:
疑惑2:为什么一个mbuf被驱动释放了两次,但是却只有被分配了一次?如果没有第二次分配,驱动为什么会有第二次释放?
又假设网卡释放函数第一次没能成功的把报文释放掉,导致网卡发送描述符重用时再次释放这个报文,在查看了网卡驱动的发送过程后,这个想法也被推翻了。因为在第一次释放后,txe->mbuf地址就已经变成了带发送的报文。
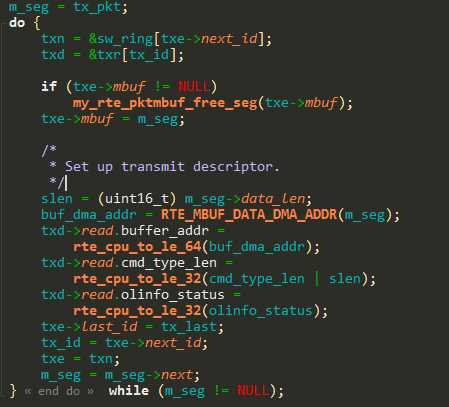
接下来卡住了。没有别的路子了。把发送驱动的函数又看了看,仔细了解了实现。鉴于已经知道第一次释放的那个报文在第二次释放时会出错,那么直接GDB断点在mbuf的驱动释放处,一步步跟踪释放过程:
在释放中,进入了rte_lcore_id()函数,获取该线程运行的逻辑核,发现获取的为0xffffffff,也就说这个线程不是EAL线程,而是内核线程。
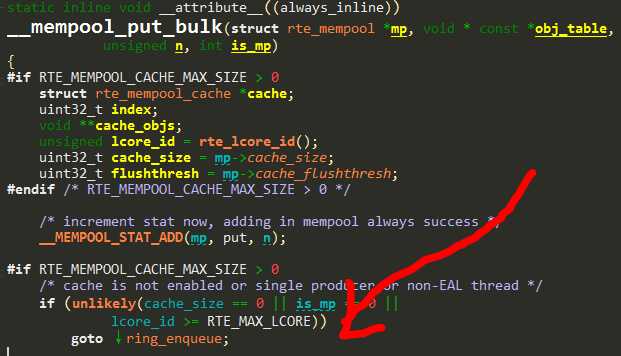
接下来错误看成了如果不是EAL线程就会导致mbuf不能入队,实际上是goto ring_enqueue。
错误的以为在此处会导致不能被正确释放,而后引起了第二次释放时的问题。于是乎,查看了这个报文的发送堆栈,找到了这个线程后。把它改为了EAL线程。
g_current_no_use_cpu_logic_id = rte_get_next_lcore(g_current_no_use_cpu_logic_id, 1, 0);
rte_eal_remote_launch(tun_recv_thread, NULL, g_current_no_use_cpu_logic_id);于是乎,没有再报错了,下载成功了,以为自此皆大欢喜了。
看错的代码最终会被重新审视。
当发现那段释放mbuf的代码逻辑并没有问题时,当发现仍然不能解释那么多现象时,一定还有未曾见光的理由。
疑惑3:为什么看错了代码,改成了EAL线程下载反而能成功了?歪打正着了什么?
一个伶俐(无奈)的想法出现了:重新checkout DPDK,重新编译,重新编译应用程序。结果是这样的:没有报错,下载成功,一切OK。终于和老版本老环境的结果一样了。
对比了新checkout出的DPDK和之前调整过的版本。发现调整过的DPDK在config中开了个调试开关---RTE_LIBRTE_MBUF_DEBUG。原来是这样:老的应用程序编译时没有打开调试信息,所以尽管在第二次释放时出错了,但没有调试检查,进程并没有退出,而是掩盖了错误。这就解释了疑惑1。
那么问题终归还是又回到为什么第二次释放出错上。
重新GDB,断点在驱动发送第一个报文的地方,查看网卡的第一个描述符中存的到底是什么。在这里有了个重要发现:
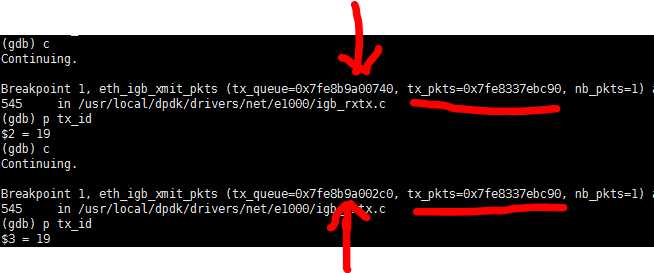
当断到第二次时,发送发送的队列的地址不一样,我们只使用了一个发送队列,那么这一定是不同网卡的!通过堆栈确认了这个。那么不同的网卡为啥会发送同一个mbuf呢!!!到这里,我想第二个疑惑已经解答了。这说明这个报文被发送到了两张网卡上,但是在报文的发送地方,报文并没有被复制成两份。最终找到了这个地方:
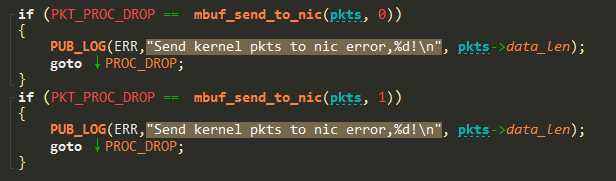
最终梳理过程是这样的:
1.mbuf被发送到了两张网卡,mbuf被放到两个网卡的发送队列的第一个位置,环形发送队列的长度是512个报文。
2.两张网卡分流调度,发送的包速度为eth0:eth1=9:1。所以eth0的网卡的队列先被用满,然后从头(第一个位置)重用,重用的时候会释放上次占用这个位置的mbuf。第一次释放没问题。
3.等到eth1的网卡队列也用满的时候,重用第一个位置,这时候,mbuf已经在eth0被释放过了,所以再次释放就会出现问题。引用计数为0,退出进程。
为了验证上述的过程,粗略计算一下:
当eth1队列满的时候,共发送了512个报文,那么根据9:1的比例,此时,eth0应该发送512*9=4608个报文。那么终端此时共发送了5120个报文。因为是使用wget的下载过程,所以终端发送的大部分报文都是ack包,根据抓包看,稳定后,服务器发送2个数据包,终端给1个ack包
所以,服务器大致发送了5120*2=10240个报文。每个报文的长度是1454字节。共发送了14,888,960字节(文件共98M, 11%左右)。
观察到下载每次都是到12%左右(12,980,468字节)时出现问题。所以从量上是能对的上的。
似乎还有一个疑惑没解开:创建EAL线程为什么没报错而下载成功了呢?
关键就在EAL线程和内核线程在释放报文时的不同。EAL线程在创建时关联了逻辑核ID,而内核线程则没有。DPDK在内存池的管理上使用了cache机制,申请的内存池单元放在ring中,为了避免频繁的入队出队操作,每个逻辑核都有一个cache。
#if RTE_MEMPOOL_CACHE_MAX_SIZE > 0
/** Per-lcore local cache. */
struct rte_mempool_cache local_cache[RTE_MAX_LCORE];
#endif当mbuf被释放时,就会先回到这个cache,等到了水标线时,才往ring中放。申请的时候,也是先从cache取,不够的话,才会去ring中取出来。
那么过程似乎是这样的:
1.mbuf被发送到两个网卡的队列,放到队列的第一个位置,由于发包调度发送速度eth0:eth1=9:1,所以eth0上的队列先被填充满,此时,重用队列的第一个位置,mbuf被释放。
2.EAL线程释放后,mbuf重新回到cache中,接收下一个报文申请报文空间时,又使用了这个mbuf,之后发送,这个mbuf又被重新放在了发送队列中。
3.此时eth1的队列满了,重用队列第一个位置,释放mbuf,因为此时,mbuf已经又被放入了eth0的发送队列中,所以,这个时候释放,引用计数还为1,因此能够释放,不会导致进程退出。但是释放了eth0队列上的正常报文。但注意此时mbuf报文依然是回到了同一个cache中。
4.又有新的报文需要发送,申请空间,mbuf又被拿出来了。发送时放入了eth0或者eth1的队列。
5.eth0上的那个被别人意外释放的mbuf,在eth0队列又满了再次释放时,又释放了第4步中那个包 -_-|| 。等于说,队列前面的某个位置总在释放后面的某个位置的报文,后面位置的释放更后面的。。。
而如果是内核线程的话,因为rte_lcore_id()返回0xffffffff,没有找到对应的逻辑核ID,因此释放报文的时候,将会直接进入ring,ring有多大呢?我们的是16384个报文大小。eth0发送的快,每个申请新的空间都从ring中取不同的mbuf,这样的话,根据上面的计算,eth1在发送到512个报文,eth0发送到4608个报文的时候,就会释放到同一个mbuf。这时候,ring还没有取够一个循环,eth0肯定不能再次拿到释放的第一个报文。所以,就会导致引用计数为0,进程退出。
done!
标签:绑定 获得 堆栈 gdb 别人 导出 定位 内存 判断
原文地址:http://www.cnblogs.com/yhp-smarthome/p/7932136.html