标签:详细信息 ica 预测算法 随机 工具 span 理解 structure 产生
本部分简要分析条件随机场的发展路线,特别是在结构化预测(structured prediction)方面。除此之外,还将分析条件随机场与神经网络和最大熵马尔可夫模型(MEMMs)的关系。最后列出了几个未来研究的开放领域。
分类方法提供了强大的工具来对离散的输出进行预测。但是在本文所考虑的一些问题中,我们希望预测的是更复杂的目标,如自然语言处理中的分析树[38,144]、不同语言句子间的对齐(alignments)[145]、移动机器人路线规划[112]等。其中每个复杂目标都有着自己的内部结构,如分析树的树状结构,我们应当能够利用这些结构以实现更有效的预测。这类问题称为结构化预测(structured prediction)。正如条件随机场是逻辑回归在预测任意结构上的拓展,结构化预测领域也将分类问题拓展至结构化预测目标。
结构化预测方法本质上是分类问题和图模型的结合,它将多元数据的简洁建模能力与利用输入数据大量特征进行预测的能力相结合。条件随机场是解决这类问题的方法之一,它对逻辑回归进行了拓展。同样,其他标准分类方法也可以拓展至结构化预测。关于结构化预测的详细信息,请参考文献[5]。本节,我们仅列出其中的几个方法。
为了更正式的解释什么是“结构”,我们简要回顾一般的分类问题。很多分类方法都可以看作要学习一个判别函数\(F(y,\mathbf x)\),其输出为有限集\(y\in \mathcal Y\),例如\(\mathcal Y = \{1,2,\dots, C\}\)。给定测试输入\(\mathbf x\),预测一个输出\(y^*=\arg\max_y F(y,\mathbf x)\)。例如,很多判别函数具有线性特征,即\(F(y,\mathbf x) =\theta^T_y \phi(\mathbf x)\),\(\theta_y\)为权值向量。
结构化预测问题与分类问题相似,但有一个本质的不同之处。在结构化预测中,可能的输出集\(\mathcal Y\)非常大,例如,将句中的词标记为命名实体的方法,如2.6.1节所示。很明显,在这种情况下每个\(y\in \mathcal Y\)(或者说标记一个序列的每种方法)都有一个离散的参数向量\(\theta_y\)是不可能的。因此,在结构化预测方法中,我们添加了判别函数根据输出结构进行分解的约束条件。正式地,在结构化预测中我们将输出作为一个随机向量\(\mathbf y = (y_1, y_2, \dots , y_T)\),将判别函数根据个各个_部分_(parts)\(Y_a\)进行分解,每个部分都是\(\mathbf y\)中变量的子集。【这正是结构化预测中“结构”这个词的来源】。我们为每个部分指定个索引\(a\in \{ 1, 2,\dots, A\}\)。于是,主要假设是将判别函数分解为
\[
F(\mathbf y, \mathbf x) = \sum_{a=1}^A F_a(\mathbf y_a, \mathbf x).
\tag{6.1}
\]
有了我们在前文中所分析的无向的任意结构条件随机场,对上述讨论应当比较熟悉。例如,任意结构条件随机场的对数概率就可以写为这种形式,因为在预测的时候我们可以忽略\(Z(\mathbf{x})\)。结构化预测方法所共有的性质是,判别函数根据“部分”进行分解。这些方法的区别在于,如何利用数据估计判别函数的参数。
结构化预测算法有很多种。条件随机场的似然基于所有输出上的求和,来计算配分函数\(Z(\mathbf x)\)和边缘分布\(p(y_i|\mathbf x)\)。其他大部分结构化预测方法基于最大化而非求和。例如,最大分离的方法(maximum-margin methods)在单变量分类上非常成功,已被扩展至结构化数据,成为结构化SVM[2,147]和最大分离马尔可夫网络[143]。感知机更新也被拓展成为结构化模型[25]。该算法特别吸引人,因为它要比选择\(\mathbf y^*\)算法在实现上要困难一些。在线感知识更新也考虑进最大分离的目标,于是得到MIRA算法[28]。
另外一类结构化方法是基于搜索的方法[31,32],这类算法利用启发式的方法对输出进行搜索,并且学习分类器用于预测下一个搜索步。其优点在于能够很好地适应于许多复杂的需要执行搜索的问题。它还可以在预测中考虑任意损失函数(不同于判别函数的分解方法)。最后,LeCun等[68]基于energy-based方法对很多预测方法进行了扩展,包括上面列出的方法。
最大化方法和基于搜索的方法的一个优势是不必在所有配置上求和以计算配分函数了边缘分布。在一些组合问题中,例如配匹和网络流问题,找到最优的配置是可行的,但是在配置上求和不可行,例如Taskar等[145]。对于更复杂的问题,不论求和还是最大化都不可行,这种优势就变得非常重要,不过即便是在这种情况下,最大化的方法也使得应用近似搜索更容易,例如定向搜索和剪枝(beam search and pruning)。例如,Pal等[102]即是一个试图简单地在条件随机场训练中引入定向搜索而带来困难的例子。
值得注意的是,尽管基于最大化的训练方法在参数估的时候没有使用似然,但其得到的参数依旧可以使用因子分解的条件概率分布\(p(\mathbf y |\mathbf x)\),即定义2.3中的条件随机场。
或许概率方法的主要优点是能够自然地通过边缘化引入隐变量。这很有用,例如,在协作分类( collective classification)方法中[142]。更多隐变量结构化模型的例子,请参考Quattoni等[109]和McCallum等[84]。一个特别有说服力的例子是Bayesian方法,其中模型参数本身被integrated out(第6.2.1节)。最近的研究中已经提出了将潜在变量引入到SVM和结构化SVM中的方法[36,159]。
各种结构化预测方法的精度还没有得到很好的理解。目前,很少有对不领域的结构化预测方法进行比较的研究,尽管Keerthi和Sundararajan[53]给出了一些实验研究。我们认为,不同的结构预测方法之间的相似性比差异更重要。与结构化预测算法本身相比,特征选择对性能的影响更大。
神经网络与条件随机场之间有着紧密的关系,它们都可被看作判别式训练的概率模型。神经网络最知名的是在分类问题上的应用,但是它们也可用于多输出问题的预测。例如,例用共享隐变量[18]的方法,或直接构建输出结果之间依赖关系的模型[67]。尽管神经网络一般使用梯度下降(5.2节)训练,但理论上来说也可以使用任何其他能用于条件随机场的方法。主要的区别在于,神经网络利用共享隐变量表示输入变量间的依赖关系,而结构化方法则直接将输出变量之间的这种关系作为一个函数来学习。
由于这个原因,很容易错认为条件随机场是凸的而神经网络不是。这是不准确的。没有隐含层的神经网络是一个线性分类器,有很多种方法可以有效的进行训练,而具有隐变量的条件随机场则具有非凸的似然函数(2.4节)。正确的理解是,在完全观测的模型中,似然函数是凸的,若有隐变量,则是非凸的。
因此,关于神经网络与结构化预测模型对比主要的新见解是:如果在输出层节点之间添加了连接,或者如果有一个好的特征集,那么不要隐含层也可能获得良好的模型。如果可以不要隐含层的话,那么实际中就可以避免局部极小问题。不过,对于较为困难的任务,尽便是在有输出层结构的情况下,隐含层的存在也会带来一些优势。一旦模型中引入了隐状态,不管是神经网络还是结构化模型,貌似非凸性不可避免(至少目前对机器学习的理解是这样的)。
条件随机场在另一个方面与神经网络也很相似。具体地,考虑一个序列长度为2的线性链条件随机场。该条件随机场是一个线性模型,对于任意两个标记取值\(\mathbf y =(y_1,y_2)\)和\(\mathbf y‘=(y_1‘,y_2‘)\),对数机率\(\log\big(p(\mathbf y|\mathbf x)/p(\mathbf y‘|\mathbf x)\big)\)是参数的线性函数。不过,边缘分布不是线性的。或者说,\(\log\big(p(y_1|\mathbf x)/p(y_1‘|\mathbf x)\big)\)不是参数的线性函数。原因在于,计算\(y_1\)的边缘分布时,变量\(y_2\)起了与隐变量类似的作用。这种观点已被用于利用per-position分类器及扩展的特征集构建近似条件随机场[71]。
线性链条件随机场最初是最大熵马尔可夫模型(maximum-entropy Markov model)的一种改进[85],它本质上是一个马尔可夫模型,其转移概率由逻辑回归方法给出。正式地,MEMM的定义:
\[
\begin{align}
p_\text{MEMM}(\mathbf y|\mathbf x) &= \prod_{t=1}^T p(y_t,|y_{t-1}, \mathbf x) \tag{6.2}\p(y_t|y_{t-1},\mathbf{x}) &= \frac{1}{Z_t(y_{t-1},\mathbf x)} \exp\left\{ \sum_{k=1}^K \theta_k f_k(y_t,y_{t-1}, \mathbf x_t) \right\} \tag{6.3} \Z_t(y_{t-1},\mathbf x) &= \sum_{y‘}\exp\left\{ \sum_{k=1}^K \theta_kf_k(y‘,y_{t-1},\mathbf x_t) \right\}. \tag{6.4}
\end{align}
\]
类似的思路也可以用在一般的有向图中,其中分布\(p(\mathbf y|\mathbf x)\)用贝叶斯网络表示,每个局部条件分布都是输入为\(\mathbf x\)的逻辑回归模型[117]。
在线性链情况下,MEMM与线性链CRF(式5.3)具有相同的形式,区别在于CRF中\(Z(\mathbf x)\)对序列求和,而MEMM中对应的项为\(\prod_{t=1}^T Z_t(y_{t-1}, \mathbf x)\)。这种区别造成了非常不同的结果。与CRF不是,MEMM的极大似然训练不要求进行推断,因为\(Z_t\)是简单地对单一位置的标记进行求和,不必在整个序列上的标记上求和。这是有向模型的训练计算量小于无向模型这种常见现象的一个例子。
不过MEMM模型存在理论缺陷,就是所谓的标记偏置(label bias)问题[63]。偏置标记本质上是未来的观测不能影响前期状态的后验分布。为了理解偏置标记问题,考虑后向迭代(式4.9)。在MEMM中为
\[
\beta_t(i) = \sum_{j\in S} p(y_{t+1}=j| y_t = i, x_{t+1}) \beta_{t+1}(j).
\tag{6.5}
\]
很不幸,不管当前标记\(i\)的值是什么,该求和结果总是1。意味着未来的观测没有为当前状态提供任何信息。为了理解这点,假设为了方便归纳,令\(\beta_{t+1}=1\ (\text{for all } j)\)。然后,很明显式(6.5)对\(j\)的求和失效,\(\beta_t(i)=1\)。
或许一种更好的理解标记偏置问题的方法是图模型的角度。考虑MEMM的图模型,如图6.1。观察该图的V形结构,我们从中可得到如下假设条件:在所有的时间步\(t\),标记\(y_t\)与未来观测\(\mathbf x_{t+1}, \mathbf x_{t+2}\)等在边缘分布上是独立的。序列数据一般不满足这种独立性假设,这也解释了条件随机场性能比MEMM模型好的原因。并且,这种独立性解释了为什么\(\beta_t(i)\)总是1。(一般而言,图结构与推理算法之间的相关性是图建模的主要概念优势之一)。作为总结,标记偏置只是解释的解果。
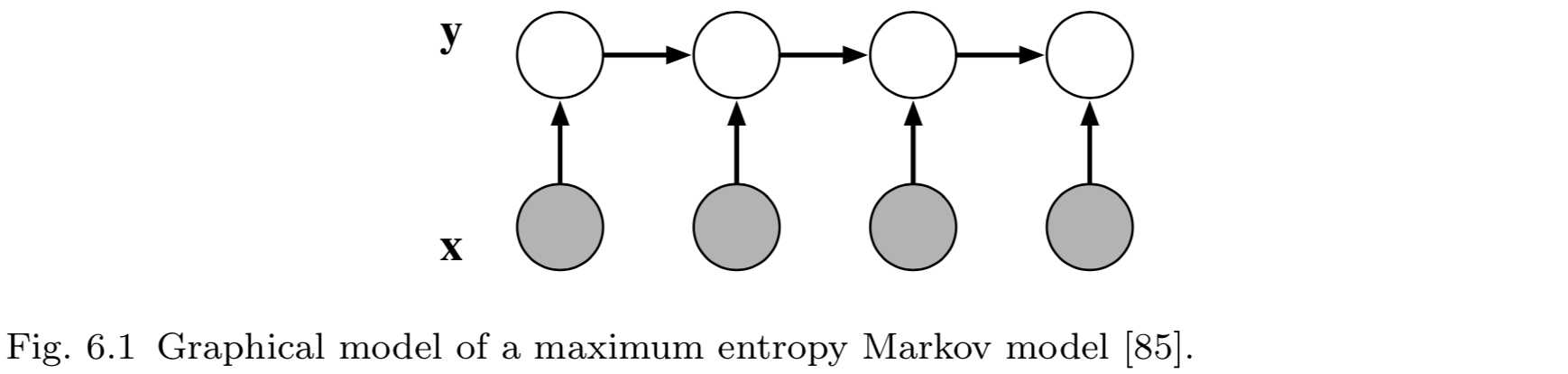
这里有一个警告:(MEMM应用中)我们总是可以从前期和未来时间步获得信息以构建特征向量\(\mathbf x_t\),而且在实践中这样做也很常见。这就产生(例如)\(\mathbf x_t\)与\(\mathbf x_{t+1}\)之添加了边的效果。这也解释了为什么MEMM和CRF在实践中的性能差已也并非像想象中的那样大。
从图模型角度分析标记偏置问题突出了一个要点。标记偏置并不是由于模型是有向还是无向造成的,而是由于MEMM所使用的这种特殊的有向模型结构。这一点被Berg-Kirkpatrick等[6]有力地证实了,该研究对多种与MEMM类似的对数线性结构无向模型进行了无监督任的实验,结果令人印象深刻。这些模型避免了标记偏置问题,因为它们具有更产生式(generative)的图结构,而不是图6.1中所示的V形结构。
最后,或许可以尝试一种将条件训练和有向模型的优点相结合的不同的方法。可以想象着定义一个有向模型\(p(\mathbf y, \mathbf x)\),可能是一个生成模型,然后通过优化条件似然\(p(\mathbf y| \mathbf x)\)来训练它。实际上,这种方法实称为最大互信息训练[4],在语音识别领域已经应用很久了。这种方法看起来提供了一种比CRF简单的训练算法,因为有向模型在训练时总是比无向模型简单。但实际上,这种方法并没不排除训练过程中运行推理。原因在于计算条件似然\(p(\mathbf y|\mathbf x)\)要求计算边缘概率\(p(\mathbf x)\),其作为也\(Z(\mathbf x)\)在条件随机场似然中的作用类似。实际上,有向模型的训练可能比无向模型还要复杂,因为模型参数被限制为概率约束——这些约束实际上增加了优化问题的难度。
最后,我们给出几个与条件随机场相关的开放研究领域。在下面的所有领域中,研究问题都是一个更大的任意结构图模型的特例,但是条件模型中特殊的附加考虑使问题更加复杂。
一般情况下条件随机场的参数数量都非常大,这使模型容易过学习。标准的应对方法是规则化,如5.1.1节所示。要解决这个问题,也可以使用完全贝叶斯过程近似。也就是说,不再将测试实例\(\mathbf x\)预测为\(\mathbf y^*=\max_\mathbf{y}p(\mathbf y|\mathbf x; \hat{\theta})\) (其中\(\hat{\theta}\)为单一参数估计),在贝叶斯方法中我们使用预测性分布$\mathbf y^* = \max_\mathbf y \int p(\mathbf y|\mathbf x;\theta)p(\theta|\mathbf x^{(1)}, \mathbf y^{(1)}, \dots, \mathbf x^{(N)}, \mathbf y^{(N)})d\theta $。该积分需要近似求得,例如,可以使用MCMC。
一般情况下,构建无向模型高效的贝叶斯方法比较困难,参见文献[95,96]中的例子。有一些论文考虑了贝叶斯CRF的近似推理算法[107,154,161],但是尽管这些方法很有意思,但是对当前条件随机场的规模(表5.1)来说没什么用处。甚至对于线性链模型,贝叶斯方法也很少用于条件随机场,主要原因还在于其巨大的计算量需求。如果要利用模型平均的优势,可能简单的集成技术,如bagging,会有同样的效果[141]。不过,贝叶斯方法的确有其他的一些潜在的优势,特别是在考虑更复杂的、层次结构的先验时。
条件随机场应用的另一个困难是其需要大量的标注数据。与简单分类相比,序列数据的标注更加耗时、成本更高。正因为如此,如果能有可以仅利用少量标注数据即可获得精确结果的技术,那将会非常有用。
实现这个目标的一种方法是半监督学习,这种模型中除了一些完全标记的数据\(\{(\mathbf x^{(i)}, \mathbf y^{(i)})\}_{i=1}^N\)之外,还有大量的非标注实例\(\{ \mathbf x^{(j)} \}_{j=1}^M\),这些未标注数据只有输入。不过,与生成式模型不同,如何在条件准则中引入未标注数据并不容易,因为未标注样本来自分布\(p(\mathbf x)\),从理论上来说该分布必须与条件随机场\(p(\mathbf y|\mathbf x)\)没有关系。为了解决该问题,现有研究中提出了多种不同类型的考虑未标注数据的规则化项,包括熵规则化(entropy regularization)[46,52]、一般期望准则(generalized expectation criteria)[81]、判别方法[70]、后验规则化[39,45],以及基于度量的学习(measurement-based learning)[73]。
本文中描述的所有方法都假设模型预先已经确定。一个很自然的问题是,模型的结构是否也能通过学习确定。如更任意结构的图模型中一样,这是一个困难的问题。实际上,Bradley和Guestrin[15]指出条件模型中的一个有意思的复杂问题。对于一个生成模型\(p(\mathbf x)\),极大似然结构的学习在模型是树状结构时可以利用著名的Chow-Liu算法有效的学习。在条件模型中,当估计\(p(\mathbf y|\mathbf x)\)时类似的算法更加困难,因为它要求估计形如\(p(y_u,y_v|\mathbf x)\)的边缘分布,也就是说,需要估计输入向量在每对输出变量上的作用。而如果不知道模型的结构,就很难估计这些分布。
条件随机场介绍(6)—— An Introduction to Conditional Random Fields
标签:详细信息 ica 预测算法 随机 工具 span 理解 structure 产生
原文地址:http://www.cnblogs.com/Juworchey/p/7954487.html