标签:接受 目录 进入 .com model 出版社 书籍 book alt
首先来看下如何查询。我们在网页中增加书名的查询链接

后端的查询处理代码:这里由于authors是manytomanyfiled,因此我们这里用r.authors.all().first()来查询符合条件的第一个
def books_inquery_result(request):
ret=[]
if request.method == ‘POST‘:
bookname=request.POST[‘bookname‘]
result=Book.objects.filter(title=bookname)
for r in result:
ret.append(r.authors.all().first())
return HttpResponse(ret)
但是当输入书名flask1的时候,我们查出来的确实下面这些代码。这是为什么呢。

我们回头看下之前添加books的操作:
ret3.publisher=Publisher.objects.all()[1]
ret3.publish_date=publish_date
ret3.save()
ret3.authors.add(Author.objects.all()[1])
我们查询对应的Author.objects.all()[1]发现也是同样的结果。
def result2(request):
result=Author.objects.all()[1]
return HttpResponse(result)
但是我们想要到的是书的作者和在网页上输入的对象关联起来。那么我们添加的代码就需要更新如下:这样就把之前的输入给加了进来
ret3=Book()
ret3.title=title
ret3.publisher=Publisher.objects.get(name=publish)
ret3.publish_date=publish_date
ret3.save()
ret3.authors.add(Author.objects.get(email=email))
此时再进行查询,就可以得到正确的结果了。而且我们还可以通过
r.authors.all().first().email
r.authors.all().first().first_name
r.authors.all().first().last_name
接下来看下如何查询出版商的信息,出版商是ForeignKey的关系。因此查询也很简单,通过下面的方式就可以查出出版商的信息。
r.publisher.address
r.publisher. name
r.publisher. city
r.publisher. state_province
r.publisher. country
r.publisher. website
select_related查询优化,首先我们在setting.py的末尾加上下面的配置:
LOGGING = {
‘version‘: 1,
‘disable_existing_loggers‘: False,
‘handlers‘: {
‘console‘:{
‘level‘:‘DEBUG‘,
‘class‘:‘logging.StreamHandler‘,
},
},
‘loggers‘: {
‘django.db.backends‘: {
‘handlers‘: [‘console‘],
‘propagate‘: True,
‘level‘:‘DEBUG‘,
},
}
}
这个logging的配置作用是在终端查询的时候自动打印出sql语句,这样我们就能很直观的看到查询的方式。比如前面的Book查询。我们来看下
Python manage.py shell
In [1]: from site_prj.models import Publisher,Book,Author
In [2]: books=Book.objects().all
In [4]: b1=books[0]
(0.002) SELECT "site_prj_book"."id", "site_prj_book"."title", "site_prj_book"."publisher_id", "site_prj_book"."publish_date" FROM "site_prj_book" LIMIT 1; args=()
In [6]: b1.title
Out[6]: u‘flask‘
In [7]: b1.publisher
(0.000) SELECT "site_prj_publisher"."id", "site_prj_publisher"."name", "site_prj_publisher"."address", "site_prj_publisher"."city", "site_prj_publisher"."state_province", "site_prj_publisher"."country", "site_prj_
publisher"."website" FROM "site_prj_publisher" WHERE "site_prj_publisher"."id" = 2; args=(2,)
Out[7]: <Publisher: ?
我们看到在查询publisher的时候又调用了sql语句,原因在于Book中publisher 和Book的关系是ForeignKey的关系,也就是多对一的关系。可能一本书有多个出版商都在出版,那么我们能不能在查询的时候将这些出版商全都查出来呢。这就需要用到select_related的方法了。
ret2=Book.objects.all().select_related(‘publisher‘) #得到所有的文章
r2=ret2[10] #选择第10篇
return HttpResponse(r2.publisher.state_province) #得到出版次文章的所有出版商的省份
In [9]: book2=Book.objects.all().select_related(‘publisher‘)
In [10]: b2=book2[2]
(0.000) SELECT "site_prj_book"."id", "site_prj_book"."title", "site_prj_book"."publisher_id", "site_prj_book"."publish_date", "site_prj_publisher"."id", "site_prj_publisher"."name", "site_prj_publisher"."address",
"site_prj_publisher"."city", "site_prj_publisher"."state_province", "site_prj_publisher"."country", "site_prj_publisher"."website" FROM "site_prj_book" INNER JOIN "site_prj_publisher" ON ("site_prj_book"."publish
er_id" = "site_prj_publisher"."id") LIMIT 1 OFFSET 2; args=()
In [11]: b2.publisher.name
Out[11]: u‘\xe6\x88\x90\xe9\x83\xbd\xe6\x97\xa5\xe6\x8a\xa5‘
从下面的调试可以看到,没有再进行SQL查询。
那么我们现在来看下发现查询。什么是反向查询呢,之前的查询是引用方查询被引用方
比如在Book中publisher 和Book的关系是ForeignKey的关系,也就是多对一的关系.如果我想查出这本书的作者还写了哪些书。就需要用到反向查询。
代码如下:
author=Author.objects.filter(first_name=first,last_name=second)
for a in author:
ret.append(a.book_set.all().first())
得到每个作者的对象后用author.book_set.all().first()得到该作者写过的所有书。
同样的通过输入出版商也可以查出该出版商的所有书籍。
publish=Publisher.objects.filter(name=publishname)
for p in publish:
ret_publish.append(a.book_set.all().first())
下面介绍下Values获取字典形式的结果。
def result3(request):
ret=[]
result=Book.objects.values(‘title‘,‘authors‘,‘publisher‘,‘publish_date‘)
for r in result:
ret.append(r)
return HttpResponse(ret)
这样能将所有的查询结果以字典的形式呈现出来。我们看到其中publisher和authro都是数字。而不是具体的名称。

我们来看下对应的sql语句:可以看到在sql语句中就是选用的是Publisher和Author的id作为查询条件且使用的是左链接的方式。
SELECT "site_prj_book"."title", "site_prj_book_authors"."author_id", "site_prj_book"."publisher_id", "site_prj_book"."publish_date" FROM "site_prj_book" LEFT OUTER JOIN "site_prj_book_authors" ON ("site_prj_book"."id" = "site_prj_book_authors"."book_id"); args=()
如果不想看字典的形式,而只是想看列表的方式,可以用values_list的方式
result=Book.objects.values_list(‘title‘,‘authors‘,‘publisher‘,‘publish_date‘)

Annotate进行聚合,计数,平均数,求和等
下面首先来计算作者的个数:
首先引入模块:django.db.models里面包含所有的计算函数
from django.db.models import *
def result2(request):
result=Author.objects.all().values(‘email‘).annotate(count=Count(‘email‘)).values(‘email‘,‘count‘)
return HttpResponse(result)
这个函数的作用是统计作者中的email使用总次数。计每个作者的email出现的次数。Annotate代表以某个元素进行聚类的意思。这里是以每个名字的次数进行聚类。返回结果如下。
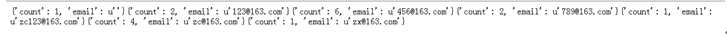
我们还可以通过聚类求平均,但是目前的表中没有整数字段。我们在Author中添加一个age的字段。添加方法如下,进入python manage.py shell执行如下的语句。
In [1]: from django.db import connection
In [2]: cursor=connection.cursor()
In [3]: cursor.execute(‘Alter TABLE Authro add age Integer‘)
In [8]: cursor.execute(‘Alter TABLE site_prj_Author add age Integer‘)
(0.014) Alter TABLE site_prj_Author add age Integer; args=None
Out[8]: <django.db.backends.sqlite3.base.SQLiteCursorWrapper at 0x3050a80>
In [3]: print Author.objects.all().query
SELECT "site_prj_author"."id", "site_prj_author"."first_name", "site_prj_author"."last_name", "site_prj_author"."email", "site_prj_author"."age" FROM "site_prj_author"
添加后我们就可以通过下面的方式进行作者平均年龄的计算了
result=Author.objects.all().values(‘age‘).annotate(average=Avg(‘age‘)).values(‘age‘,‘average‘)
对应的SQL语句:
SELECT "site_prj_author"."age", AVG("site_prj_author"."age") AS "average" FROM "site_prj_author" GROUP BY "site_prj_author"."age"; args=()
链式查询:
过滤成都日报出版且城市是成都的出版商
result=Publisher.objects.filter(name=‘成都日报‘).filter(city=‘成都‘)
过滤成都出版社且城市不是成都出版商
result=Publisher.objects.filter(name=‘成都日报‘).exclude(city=‘成都‘)
对应的SQL语句:
SELECT "site_prj_publisher"."id", "site_prj_publisher"."name", "site_prj_publisher"."address", "site_prj_publisher"."city", "site_prj_publisher"."state_province", "site_prj_publisher"."country", "site_prj_publisher"."website" FROM "site_prj_publisher" WHERE (NOT ("site_prj_publisher"."name" = ‘成都日报‘) AND "site_prj_publisher"."city" = ‘成都‘);
Defer排除不需要的字段:有些模型的字段太多,我们只想看其中几种可以用defer来排查某些字段
result=Author.objects.all().defer(‘age‘).query
对应的SQL:可以看到没有查询age字段
SELECT "site_prj_author"."id", "site_prj_author"."first_name", "site_prj_author"."last_name", "site_prj_author"."email" FROM "site_prj_author"
相对应的only就是选择需要的字段。
result=Author.objects.all().only(‘age‘).query
对应的SQL:
SELECT "site_prj_author"."id", "site_prj_author"."age" FROM "site_prj_author"
最后补充model的所有类型描述:
auto_now:当对象被保存时,自动将该字段的值设置为当前时间.通常用于表示 “last-modified” 时间戳;
auto_now_add:当对象首次被创建时,自动将该字段的值设置为当前时间.通常用于表示对象创建时间。
path:必需参数,一个目录的绝对文件系统路径。 FilePathField 据此得到可选项目。 Example: “/home/images”;
match:可选参数, 一个正则表达式, 作为一个字符串, FilePathField 将使用它过滤文件名。
注意这个正则表达式只会应用到 base filename 而不是路径全名。
Example: “foo。*\。txt^”, 将匹配文件 foo23.txt 却不匹配 bar.txt 或 foo23.gif;
recursive:可选参数, 是否包括 path 下全部子目录,True 或 False,默认值为
False。
max_digits:总位数(不包括小数点和符号)
decimal_places:小数位数。如:要保存最大值为 999 (小数点后保存2位),你要这样定义字段:models.FloatField(…,max_digits=5, decimal_places=2),要保存最大值一百万(小数点后保存10位)的话,你要这样定义:models.FloatField(…,max_digits=19, decimal_places=10)
正小整型字段,类似 PositiveIntegerField, 取值范围较小(数据库相关)SlugField“Slug” 是一个报纸术语。 slug 是某个东西的小小标记(短签), 只包含字母,数字,下划线和连字符。它们通常用于URLs。 若你使用 Django 开发版本,你可以指定 maxlength。 若 maxlength 未指定, Django 会使用默认长度: 50,它接受一个额外的参数:
schema_path:校验文本的 RelaxNG schema 的文件系统路径。
标签:接受 目录 进入 .com model 出版社 书籍 book alt
原文地址:http://www.cnblogs.com/zhanghongfeng/p/7976355.html