标签:ges list header xls write utf-8 auth get mat
qidian.py:
import xlwt
import requests
from lxml import etree
import time
all_info_list = []
def get_info(url):
html = requests.get(url)
selector = etree.HTML(html.text)
infos = selector.xpath(‘//ul[@class="all-img-list cf"]/li‘)
for info in infos:
title = info.xpath(‘div[2]/h4/a/text()‘)[0]
author = info.xpath(‘div[2]/p[1]/a[1]/text()‘)[0]
style_1 = info.xpath(‘div[2]/p[1]/a[2]/text()‘)[0]
style_2 = info.xpath(‘div[2]/p[1]/a[3]/text()‘)[0]
style = style_1 + ‘.‘ + style_2
complete = info.xpath(‘div[2]/p[1]/span/text()‘)[0]
introduce = info.xpath(‘div[2]/p[2]/text()‘)[0].strip()
word = info.xpath(‘div[2]/p[3]/span/text()‘)[0].strip(‘万字‘)
info_list = [title, author, style, complete, introduce, word]
all_info_list.append(info_list)
time.sleep(1)
if __name__ == ‘__main__‘:
urls = [‘http://a.qidian.com/?page={}‘.format(str(i)) for i in range(1, 5)]
for url in urls:
get_info(url)
header = [‘title‘, ‘author‘, ‘style‘, ‘complete‘, ‘introduce‘, ‘word‘]
book = xlwt.Workbook(encoding=‘utf-8‘)
sheet = book.add_sheet(‘Sheet1‘)
for h in range(len(header)):
sheet.write(0, h, header[h])
i = 1
for list in all_info_list:
j = 0
for data in list:
sheet.write(i, j, data)
j += 1
i += 1
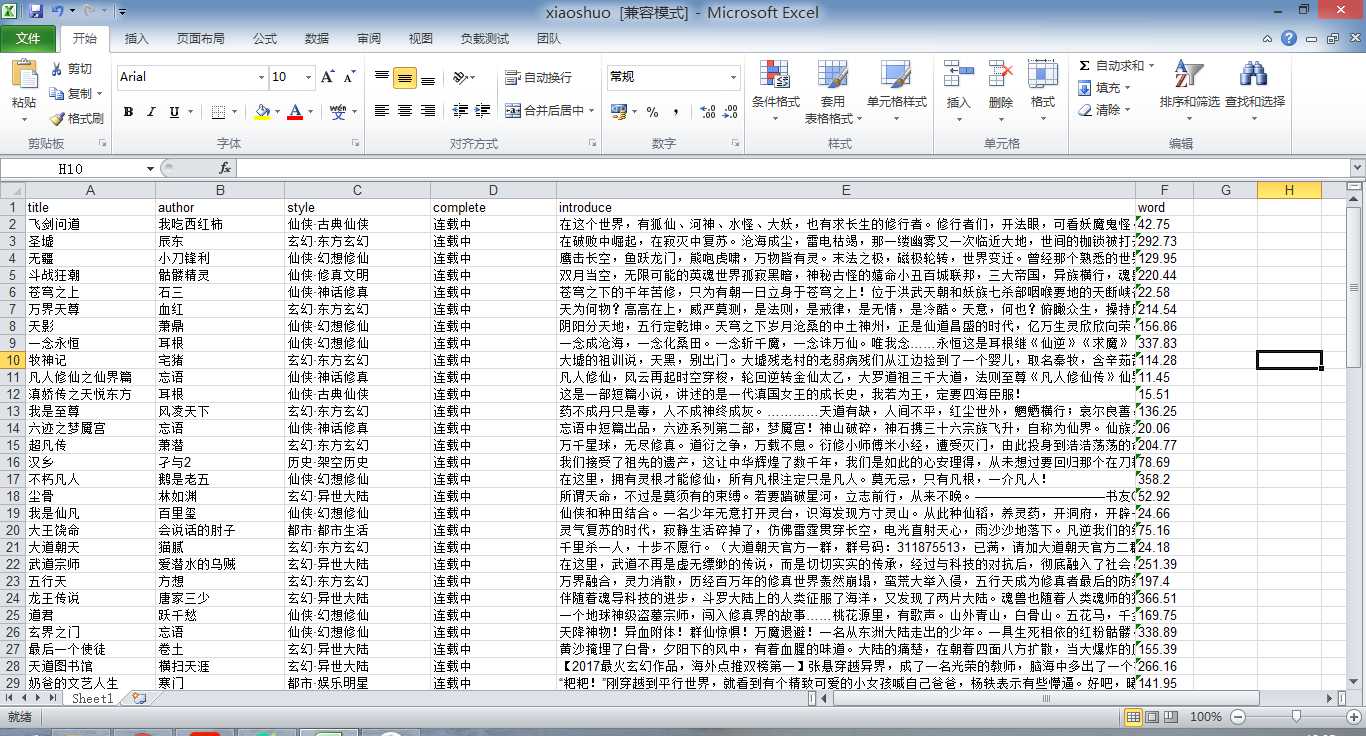
book.save(‘xiaoshuo.xls‘)
标签:ges list header xls write utf-8 auth get mat
原文地址:http://www.cnblogs.com/silverbulletcy/p/8006908.html