标签:returns access code java nbsp 产生 就是 容量 原理
HashMap中的数据结构是数组+单链表的组合,以键值对(key-value)的形式存储元素的,通过put()和get()方法储存和获取对象。
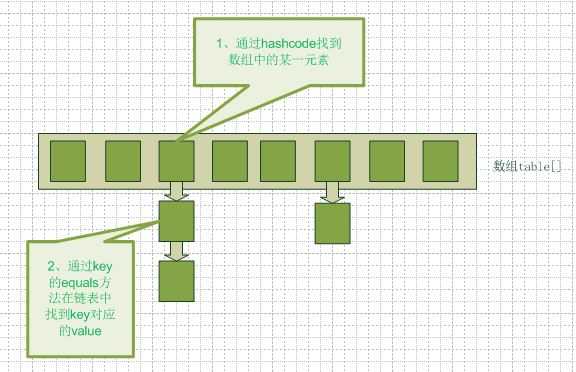
(方块表示Entry对象,横排表示数组table[],纵排表示哈希桶bucket【实际上是一个由Entry组成的链表,新加入的Entry放在链头,最先加入的放在链尾】,)
put()源码分析:
public V put(K key, V value) { // 若“key为null”,则将该键值对添加到table[0]中 if (key == null) return putForNullKey(value); // 若“key不为null”,则计算该key的哈希值 int hash = hash(key); // 搜索指定hash值在对应table中的索引 int i = indexFor(hash, table.length); // 循环遍历table数组上的Entry对象,判断该位置上key是否已存在 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; // 哈希值相同并且对象相同 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { // 如果这个key对应的键值对已经存在,就用新的value代替老的value,然后退出! V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } // 修改次数+1 modCount++; // table数组中没有key对应的键值对,就将key-value添加到table[i]处 addEntry(hash, key, value, i); return null; }
可以看到,当我们给put()方法传递键和值时,HashMap会由key来调用hashCode()方法,返回键的hash值,计算Index后用于找到bucket(哈希桶)来储存Entry对象。
put()时,如果两个对象key的hashcode相同,那么它们的bucket位置也相同,‘碰撞’会发生,HashMap使用链表来解决碰撞问题。HashMap会先遍历table数组,用equals()和hash值判断数组中是否存在key对应的键值对, 如果这个key对应的键值对在Entry数组中已经存在,就用新的value代替老的value。如果不存在,就将键值对添加到table[ i ]处。
如果该table[ i ]已经存在其他元素,但是equals()并不相同,那么新元素将会储存在bucket链表的表头,通过next指向原有的元素,形成链表结构。
Entry数据结构源码如下(HashMap内部类):
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; /** 指向下一个节点 */ Entry<K,V> next; int hash; /** * 构造方法为Entry赋值 */ Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } ... ... }
形成单链表的核心代码如下:
/** * 将Entry添加到数组bucketIndex位置对应的哈希桶中 */ void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); } /** * 在链表中添加一个新的Entry对象在链表的表头 */ void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
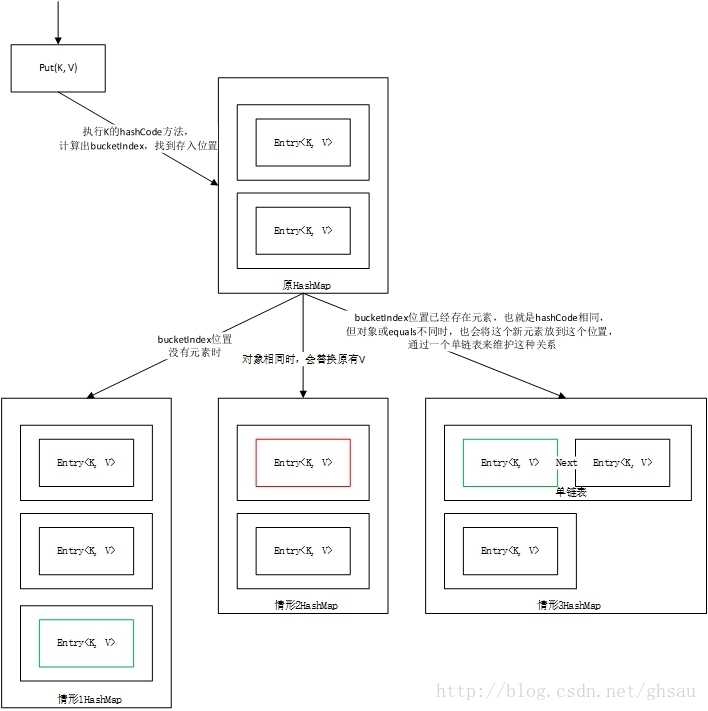
(put方法执行过程)
如果两个不同的key的hashcode相同,两个值对象储存在同一个bucket位置,要获取value,我们调用get()方法,HashMap会使用key的hashcode找到bucket位置,因为HashMap在链表中存储的是Entry键值对,所以找到bucket位置之后,会调用key的equals()方法,按顺序遍历链表的每个 Entry,直到找到想获取的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那HashMap必须循环到最后才能找到该元素。
get()方法源码如下:
public V get(Object key) { // 若key为null,取table[0]返回 if (key == null) { return getForNullKey(); } // 获取key的hash值 int hash = hash(key.hashCode()); // 在“该hash值对应的链表”上查找“键值等于key”的元素 for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; // 哈希码相同并且对象相同 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { return e.value; } } return null; }
我们可以看到在HashMap中要找到某个元素,需要根据key的hash值来求得对应数组中的位置。如何计算这个位置就是hash算法。前面说过HashMap的数据结构是数组和链表的结合,所以我们当然希望这个HashMap里面的元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表。
源码分析:
/** * Returns index for hash code h. */ static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }
HashMap有两个参数影响其性能:初始容量和加载因子。默认初始容量是16(必须为2的幂),解释一下,当数组长度为2的n次幂的时候,不同的key通过indexFor()方法算得的数组位置相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,get()的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
加载因子是0.75,极限容量是2的30次方。容量是HashMap中bucket哈希桶(Entry的链表)的数量,初始容量只是HashMap在创建时的容量。加载因子是HashMap在其容量自动增加之前可以达到多满的一种尺度。
当HashMapde的长度超出了加载因子与当前容量的乘积(默认16*0.75=12)时,通过调用rehash方法重新创建一个原来HashMap大小的两倍的Entry数组,并将原来的bucket桶放入新的Entry数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } // 重新创建一个Entry数组 Entry[] newTable = new Entry[newCapacity]; // 用来将原先table的元素全部移到newTable里面 transfer(newTable, initHashSeedAsNeeded(newCapacity)); // 再将newTable赋值给table table = newTable; // 重新计算临界值 threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
重新调整HashMap大小,当多线程的情况下可能产生条件竞争。因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。
HashMap是线程不安全的,在多线程情况下直接使用HashMap会出现一些莫名其妙不可预知的问题。在多线程下使用HashMap,有几种方案:
A.在外部包装HashMap,实现同步机制
B.使用Map m = Collections.synchronizedMap(new HashMap(...));实现同步,这里就是对HashMap做了一次包装
D.使用java.util.HashTable,效率最低
E.使用java.util.concurrent.ConcurrentHashMap,相对安全,效率较高
注意一个小问题,HashMap所有集合类视图所返回迭代器都是快速失败的(fail-fast),在迭代器创建之后,如果从结构上对映射进行修改,除非通过迭代器自身的 remove 或 add 方法,其他任何时间任何方式的修改,迭代器都将抛出 ConcurrentModificationException。。因此,面对并发的修改,迭代器很快就会完全失败。
标签:returns access code java nbsp 产生 就是 容量 原理
原文地址:http://www.cnblogs.com/dijia478/p/8006713.html