标签:cte 需要 alt size odi turn 输出 记录 logs
在上一章当中,写了文件的生成过程。这一章主要讲解文件格式(V3版本)的具体细节。
字典文件的作用是在存储的时候将字符串等类型转换为int类型,好处主要有两点:
1、减少存储占用空间
2、用在需要group by的字段上比较合适,可以减少计算时的shuffle的数据量。
每一个字典列都有对应的三种文件.dict, .sortindex, .dictmeta文件,输出格式都是thrift格式
字典的值每满1000就作为一个chunk输出一次,具体的类是ColumnDictionaryChunk
相关参数:
carbon.dictionary.chunk.size
把字段的值sort了一下之后,计算出每个值的sortIndex和invertedIndex,具体的类是ColumnSortInfo
1、List<SortIndex>,记录着每个字典值的surrogate,从1开始
2、List<SortInvertedIndex>,记录着每个字典surrogate在数组中的位置,从1开始
它们的关系如下:
sortIndex[i] = dictionarySortModel.getKey(); // the array index starts from 0 therefore -1 is done to avoid wastage // of 0th index in array and surrogate key starts from 1 there 1 is added to i // which is a counter starting from 0 sortIndexInverted[dictionarySortModel.getKey() - 1] = i + 1;
假设字典值是beijing,shenzhen,shanghai
| 城市 | surrogate | sortIndex | invertIndex |
| beijing | 1 | 1 | 1 |
| shenzhen | 2 | 3 | 3 |
| shanghai | 3 | 2 | 2 |
该文件主要记录字典的以下属性,具体的类是ColumnDictionaryChunkMeta
1、最小key
2、最大的key
3、开始offset
4、结束offset
5、chunk的数量
CarbonRow在sort阶段会被分成3个部分:
1、字典列(mdk,SORT_COLUMNS都是字典列)
2、非字典维度列和高基数列
3、度量值列
在写入的时候,先写入到TablePage里,TablePage会把数据拆分成4部分
// one vector to make it efficient for sorting private ColumnPage[] dictDimensionPages; private ColumnPage[] noDictDimensionPages; private ComplexColumnPage[] complexDimensionPages; private ColumnPage[] measurePages;
每个TablePage都会记录以下几个Key:
private byte[][] currentNoDictionaryKey; // MDK start key private byte[] startKey; // MDK end key private byte[] endKey; // startkey for no dictionary columns private byte[][] noDictStartKey; // endkey for no diciotn private byte[][] noDictEndKey; // startkey for no dictionary columns after packing into one column private byte[] packedNoDictStartKey; // endkey for no dictionary columns after packing into one column private byte[] packedNoDictEndKey;
数据在一行一行写到TablePage之后,最后会做一次统一的编码,详细的方法请看TablePage的encode方法。
Page的meta信息
private DataChunk2 buildPageMetadata(ColumnPage inputPage, byte[] encodedBytes) throws IOException { DataChunk2 dataChunk = new DataChunk2(); dataChunk.setData_page_length(encodedBytes.length); fillBasicFields(inputPage, dataChunk); fillNullBitSet(inputPage, dataChunk); fillEncoding(inputPage, dataChunk); fillMinMaxIndex(inputPage, dataChunk); fillLegacyFields(dataChunk); return dataChunk; }
一个blocket的阈值是64MB,一个blocket包括N个TablePage,当写满一个TablePage之后,就把blocket写入到文件当中。
carbondata的BTree索引,是一个记录着每个Blocklet的mdk的startKey和endKey,以及Blocklet当中所有TablePage的列的最大最小值
那么数据文件的详细格式,基本和官网上介绍的是一致的
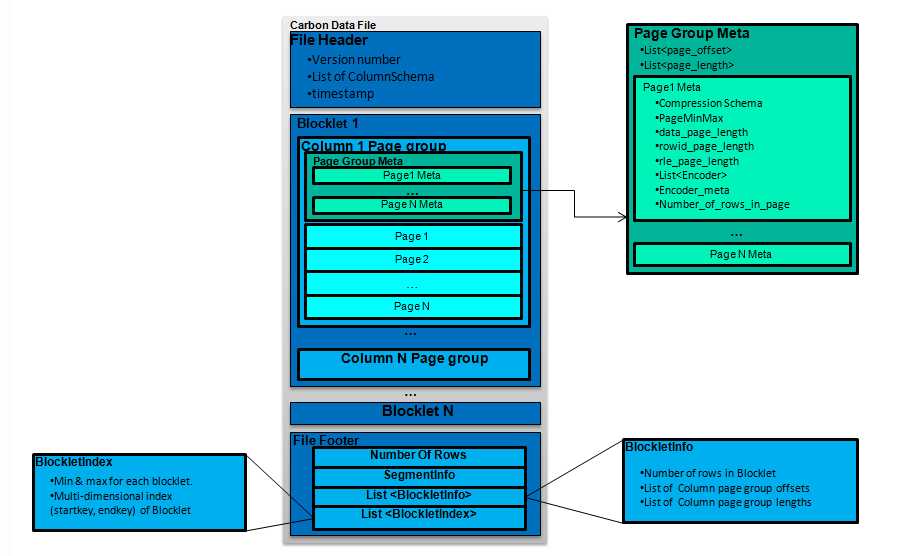
mdk和hbase的rowkey是一个性质的,详细可以看下面这张图,排序方式跟hbase没有任何区别

索引文件以.carbonindex结尾
索引文件包括三个部分:索引头,索引两部分
索引头包括:
1、文件格式版本(当前版本是V3)
2、Segment信息(有多少列,列的基数)
3、列的信息
4、bucket ID
索引信息包括以下信息:
1、Blocket的记录数
2、数据文件名
3、Blocket的meta信息offset
3、BlockletIndex (BTree索引,包含blocket的startKey、endKey,以及每一列的最大最小值,这个前面已经讲过了)
4、BlocketInfo(记录数,每个TablePage的offset,每个TablePage的长度,维度列dimension_offsets的起始位置,度量值measure_offsets的起始位置,有多少个TablePagenumber_number_of_pages)
索引文件的信息在文件的footer当中也是存在的,在carbondata1.2当中索引文件还是有很多个,感觉有点多余。
到carbondata1.3会被合并成一个文件,这样就能大大缩短启动的时候加载索引的开销。
岑玉海
转载请注明出处,谢谢!
标签:cte 需要 alt size odi turn 输出 记录 logs
原文地址:http://www.cnblogs.com/cenyuhai/p/7191291.html