标签:Lucene style blog http color io os 使用 ar
多核心说白了就是多索引库。也可以理解为多个"数据库表"
说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索,不使用多核也没问题,这样带来的问题是 indexs文件很多,而且产品的索引文件和会员信息的索引文件混在一起,备份也是个问题。 如果使用了多核,那就很轻松了,产品和会员就可使用不同的URL进行提交了,业务上也很清晰,生成的索引文件也不会混在一起,也容易备份。
????每个索引库通过相对独立的url访问。
?
还记得solr home吗,既然配置多核心,那么我们可以新建一个目录作为solr home,从零开始搭建,这样理解会更深(记得在tomcat中修改solr home路径)。
我这里使用的solr home路径为:D:\Installed Applications\SolrIndex,之后将solr解压,将solr-4.9.0\example\multicore下的所有文件copy到solr home。
可以看到里面有core0和core1两个核心,和一个solr.xml。core0和core1从名字就可以看出来是两个示例核心,文件结构非常简单,就只有两个文件,schema.xml和solrconfig.xml,所以我们可以根据需要修改或新建核心,只要根据实例核心的目录结构就好。接下来是schema.xml,这个文件相当于告诉solr,有多少核心和核心的名字及核心的位置:
结构如下:
?
?
shardHandlerFactory暂时不管,主要修改core,name是核心的名字,instanceDir是核心的路径,默认是当前目录,这个最好保持一致,即加入核心名字是core0,那么就在solr home下新建一个core0文件夹,里面放入配置文件,那么这就是一个核心。
我修改后的solr.xml配置如下:
?
目录结构如下:
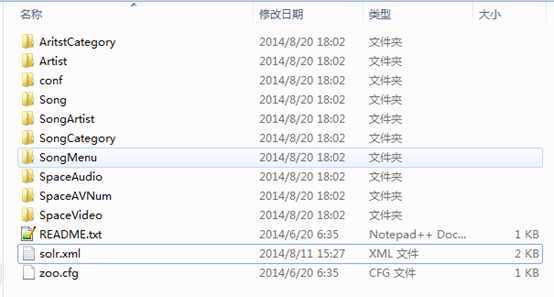
?
?
可能大家已经注意到配置有下列内容:
?
AdminPath是指url路径
Host是指主机名
defaultCoreName是指默认使用的核心(不配置也完全可以)
hostPort是指访问的端口(跟tomcat的端口保持一致)
hostContext是指主机的上下文,也就是webapps中solr的项目名
其实有点像tomcat项目的配置。
?
开启tomcat服务,访问:localhost:8983/solr
如下图所示:
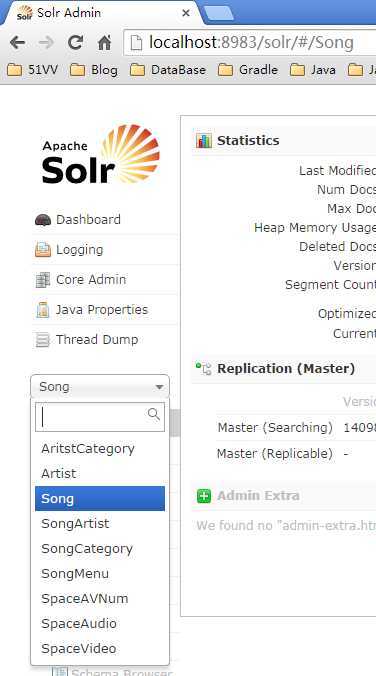
即可看到多个核心。当然也可以在url上访问不同核心库:
Localhost:8983/solr/admin/coreName
刚说的defaultCoreName也就是说,如果没指定访问的核心,默认访问哪个核心的作用。
?
?
Solr默认是没有中文分词的,其中solr默认的比较常用的数据类型有下面几种:string、long、int。详细的请看我的另外一篇博客:一、Solr综述
我用的是IK分词器,是国人做的一个开源的分词器,所以主要说下IK分词器的配置。
下载?"IK?Analyzer?2012FF_hf1.zip"包。?详见http://zhengchao730.iteye.com/blog/1833000
解压后的目录结构:
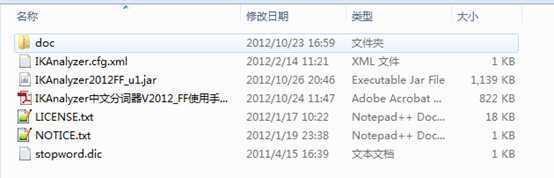
其中已经有比较详细的文档了,但是我发现文档中并没有对solr分词器的配置有详细的说明。所以请读者继续往下看。
?
步骤一:将 IKAnalyzer2012FF_u1.jar拷贝到目录"$TOMCAT_HOME \webapps\solr\WEB-INF\lib"中
步骤二:将IKAnalyzer.cfg.xml、stopword.dic拷贝到目录$TOMCAT_HOME \webapps\solr\WEB-INF\classes目录下,没有则新建classes目录。
步骤三:在每个核心中的schema.xml中配置IK分词器:
?
?
这样就可以使用ik分词器了。
其中isMaxWordLength是指分词的细粒度,可以分别制定index索引和query查询的分词细粒度,建议将index的isMaxWordLength设置为false,这样就采用最细分词,是索引更精确,查询时尽量能匹配,而将query的isMaxWordLength设置为true,采用最大分词,这样能够使查询出来的结果更符合用户的需求。
并且还有一点需要特别注意,我用的是solr4.9,所以需要把各核心schema.xml中的<schema name="example core zero" version="1.1">版本由1.1改为1.5
<schema name="example core zero" version="1.5">.
这样查询时分词才能成功,比如搜索中华人民共和国,如果不配置的话,默认是短语匹配,就只搜索文档中包含中华人民共和国的结果,但是如果配置了查询分词,那么中华、人民….都能被匹配。
之后在schema.xml中配置一个field用于测试,如下:
然后打开solr的admin页面:
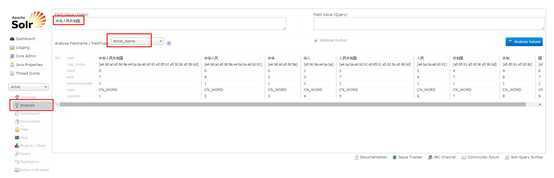
可以看到分词之后的效果。
标签:Lucene style blog http color io os 使用 ar
原文地址:http://www.cnblogs.com/edwinchen/p/3974255.html