{kind=link}
课下测试ch02
- 1.假设下面位串是基于IEEE格式的5位浮点表示,一个符号位,2个阶码位,两个小数位。下面正确的是(AD)
A .
3.5的表示是[01011]
B .
-1.0的表示[01111]
C .
0.5的表示是[00011]
D .
1.5的表示是[00110]
解析:
1. IEEE浮点表示:
- 符号:s通过其值1负和0正决定V的正负,对于V=0另作解释。
- 尾数:M是一个二进制小数,它的范围是1 – 2-ε,或者0 – 1-ε
- 阶码:E的作用是对浮点数加权,权重是2的E次幂(可能是负数)
2. 通过将浮点数的位划分为3个字段,分别进行编码,类似科学计数法。 - 1.1个单独的符号位s,直接编码符号s
- 2.k位的阶码字段,exp=ek-1···e0,编码解码E
- 3.n位的小数字段,frac=fn-1···f0,编码尾数M,但是该值依赖于E是否为0
3.5的表示是 01011
-1.0的表示是 11111
0.5的表示是 00001
1.5的表示是 00110 - 2.下面可以用二进制精确表示的数有(ACD)
A .
1/2
B .
1/3
C .
1/4
D .
3/8
E .
5/7
解析:假定我们仅考虑有限长度的编码,呢么十进制表示法不能准确的表达像1/3和5/7这样的数。类似,小数的二进制表示法只能表示那些能够被写成
x*2^y 的数
- 3.对于int x; float f; double d;下面正确的是(ACD)
A .
x == (int)(double)x
B .
x==(int)(float)x
C .
f == -(-f)
D .
1.0/2 == 1/2.0
E .
(f+d)-f == d
解析:浮点数和整数之间的转化:
- 从int ---> float可能会发生舍入,但是不会发生溢出
- 从int --> double,如果Int的值是在53位以下的(包括53位),会得到一个精确的转换。
- 从float --> double, 我们会得到一个精确的转换因为double的精度远远大于float的精度
从float, double -- > int,这样的转化可能会有问题,一个是从单精度浮点数到Int,由于阶码的存在,要调整尾数的尾数,所以在移位操作的时候可能会丢掉一些低有效位。并且这样的转化会按照向0舍入的操作去进行处理数据。另一个问题是浮点数可能会远远大于或者小于整型能够表示范围,因此我们把两种类型的浮点数的比整型最小值还要小的变为Tmin,并且一些在浮点数中特殊的值,我们会将它们都转化为Tmin或者Tmax。
4.有关二进制小数的表述,正确的是(AD)
A .
0.125表示为[0.001]
B .
0.125表示为[0.0001]
C .
3.1875表示为[11.00111]
D .
3.1875表示为[11.0011]
解析:进位计数制的要素:
①、数码:用来表示进制数的元素。比如二进制数的数码为:0,1。十进制数的数码为:0,1,2,3,4,5,6,7,8,9。十六进制数的数码为:0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F
②、基数:数码的个数。比如二进制数的基数为2。十进制数的基数为10。十六进制数的基数为 16.
③、位权:数制中每一固定位置对应的单位值称为位权。例如十进制第2位的位权为101即10,第3位的位权为102即100;而二进制第1位的位权为20即1,第3位的位权为4,对于 N进制数,整数部分第 i位的位权为N(i-1),而小数部分第j位的位权为N-j。
那么我们可以说:每个数码所表示的数值=该数码值 * 所处位置的位权。
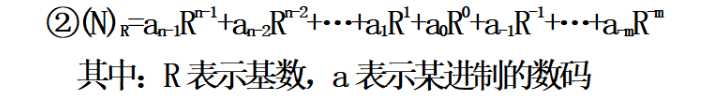
从上面的二进制公式我们可以看出,小数点向左移动一位,则相当于 (∑ 2i * bi)/2。因为每一位的位权都*2-1;反过来,小数点向右移动一位,则相当于该数乘以2。
注意:二进制小数不像整数一样,只要位数足够,它就可以表示所有整数。假设我们仅考虑有限长度的编码,那么二进制小数无法精确的表示任意小数,比如十进制小数0.2,我们并不能将其准确的表示为一个二进制数,只能增加二进制长度提高表示的精度。
- 5.有关三位数x,y的乘积x*y截断为四位,下面说法正确的是(AC)
A .
无符号的[100]*[101]结果为4
B .
无符号的[100]*[101]结果为-4
C .
有符号的[100]*[101]结果为-4
D .
有符号的[100]*[101]结果为4
解析:对于一个 w 位的无符号二进制整数[xw-1 , xw-2 , … , x2 , x1 , x0],其值大小满足 0 <= x <= 2w-1.
如果两个无符号数相乘,那么其结果应该是 0 <= x*y <=(2w-1)2=22w-2w+1+1。很显然表示这个范围的数可能需要 2w 位来表示。也就是 2w 位的整数乘积的低 w 位表示的值。根据我们前面讲的截断原理:可以看做是计算乘积模2w,即:
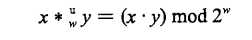
- 6.我们用一个十六进制的数表示长度w=4的位模式,把数字解释为补码,关于其加法逆元的论述正确的是(ABDE)
A .
0x8的加法逆元是-8
B .
0x8的加法逆元是0x8
C .
0x8的加法逆元是8
D .
0xD的加法逆元是3
E .
0xD的加法逆元是0x3
解析:
对于补码加法运算,因为补码编码是表示有符号的整数。
对于一个 w 位的补码二进制整数[xw-1 , xw-2 , … , x2 , x1 , x0],其值大小满足 -2w-1 <= x <= 2w-1-1。那么 -2w <= x+y <=2w-1
想要表示上面的两个数相加和的范围,那么可能需要 w+1 来表示。这里我们也需要截取。
与无符号加法运算不同,补码加法会出现三种情况:正溢出、正常、负溢出。定义如下:
范围在 -2w-1 <= x,y <= 2w-1-1 做加法运算时,满足:
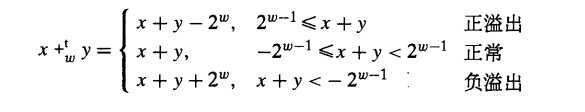
简单来说:补码加法运算就是先按照无符号加法进行运算,而后在进行无符号和有符号的转换。
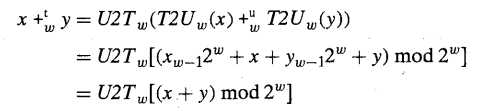
- 7.大多数计算机使用同样的机器指令来执行无符号和有符号加法。(A)
A .
正确
B .
错误
C .
不确定
解析:两个数的w位补码之和与无符号之和有完全相同的位级表示。实际上,大多数计算机使用相同的机器指令来执行无符号或有符号加法。
- 8.我们用一个十六进制的数表示长度w=4的位模式,对于数字的无符号加法逆元的位的表示正确的是(ACD)
A .
0x8的无符号加法逆元是0x8
B .
0xD的无符号加法逆元是0xD
C .
0xF的无符号加法逆元是0x1
D .
0xF的无符号加法逆元是1
解析:
对于补码加法运算,因为补码编码是表示有符号的整数。
对于一个 w 位的补码二进制整数[xw-1 , xw-2 , … , x2 , x1 , x0],其值大小满足 -2w-1 <= x <= 2w-1-1。那么 -2w <= x+y <=2w-1
想要表示上面的两个数相加和的范围,那么可能需要 w+1 来表示。这里我们也需要截取。
与无符号加法运算不同,补码加法会出现三种情况:正溢出、正常、负溢出。定义如下:
范围在 -2w-1 <= x,y <= 2w-1-1 做加法运算时,满足:
简单来说:补码加法运算就是先按照无符号加法进行运算,而后在进行无符号和有符号的转换。
- 9.0<=x,y<2^w, 则(F)
A .
x+y的最大值是2^w
B .
x+y的最大值是2^w-1
C .
x+y的最大值是2^w-2
D .
x+y的最大值是2^(w+1)
E .
x+y的最大值是2^(w+1)-1
F .
x+y的最大值是2^(w+1)-2
解析:对于一个 w 位的无符号二进制整数[xw-1 , xw-2 , … , x2 , x1 , x0],其值大小满足 0 <= x <= 2w-1.
如果两个无符号数相加,那么其结果应该是 0 <= x+y <=2w+1-2。很显然表示这个范围的数必须要 w+1 位二进制。
当我们对无符号数做加法运算的时候,如果结果超过了 2w-1,那么这个结果就会失真。
- 10.计算机中x<y 和x-y<0总是等价的。(A)
A .
错误
B .
正确
C .
不确定
解析:比较表达式x<y和x-y<0时会产生不同的结果,比如,数的类型决定了数的大小范围,当X很大,y为一个很小的负数。。溢出
- C语言数据类型转化时,先改变大小,还是先改变无符号和有符号对程序的结构没有影响。(A)
A .
错误
B .
正确
C .
不确定
解析:C语言中提供了很多整数类型(整型),主要区别在于它们取值范围的大小。int代表有符号的整数,也就是说,用int声明的变量可以是正数也可以是负数,也可以是零,但是只能是整数。
比如:int a = 3; int b = 0; int c = -5;
以上这些都是合法的。
int的取值范围因机器而异,一般而言,在较旧的PC上,int值在内存中一般是按2个字节(16位)进行存储的,在较新的PC以及工作站和大型机上,int值在内存中一般是按照4个字节(32位)进行存储的。
C语言中将基本数据类型划分为signed(有符号)和unsigned(无符号)两大类。
例如,初始化变量int a = -3;其实它等价于signed int a = -3;关键字signed在这里可以省略,因为C语言默认就是有符号类型的,如果要定义无符号类型的数(也就是0和正整数)可以这样定义,unsigned int b = 5;
为了说明清楚signed和unsigned的区别,首先需要了解数据在内存中是如何存储的,在计算机中所有的数据都是按照二进制进行存储的(以下假设在字长为2个字节的机器上来表示)。
举个例子来说,unsigned int a = 1; 变量a在内存中就是以00000000 00000001来存储的,用图表的形式表示:
因为这里是unsigned int,它是无符号整型,所以的它的16位全部用来表示数据。
所以有无符号对于程序结构有很大的影响
- 12.short sx=-12345;
int x = sx;
unsigned ux = sx;
(ACD)
A .
sx,x,ux的十六进制表示中的最后两个字节是0xcfc7
B .
ux == 0xffffcfc7
C .
ux == 0x0000cfc7
D .
x == 0xffffcfc7
E .
x == 0x0000cfc7
解析:扩展一个数字的位,简单来说就是在不同字长的整数之间转换,而这种转换我们可以需要保持前后数值不变。当然将一个数据转换为字长更小的数据类型的时候,它的值肯定会发生变化。那么我们只能将较小的数据类型转换为较大的数据类型。比如将短整型short int 转换为整型 int。,那该怎么办呢?
①、零扩展
将一个无符号数转换为一个更大的数据类型,我们只需要简单的在二进制序列前面添加 0 即可。
②、符号位扩展
将一个补码数字转换为一个更大的数据类型,我们需要在开头添加符号位。
由上面两条我们可以总结:如果我们原始位为[xw-1 , xw-2 , … , x2 , x1 , x0],那么扩展后就可以表示为:[xw-1 ,xw-1 ,...,xw-1 , xw-2 , … , x2 , x1 , x0]。
即我们想证明:
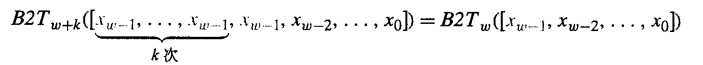
在表达式的左边,我们增加了 k 位的xw-1副本。如果我们证明符号位扩展一位,即 k=1,而值是保持不变的。那么对于任意的k都能保持这种属性。那么等式变为:
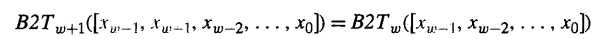
由于无符号的,添加0,这很好理解,前后数值不变。那么我们证明有符号的补码编码:
由于:
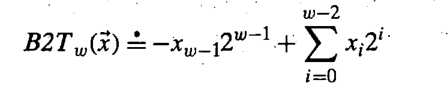
将上面的补码编码替换等式右边,即:
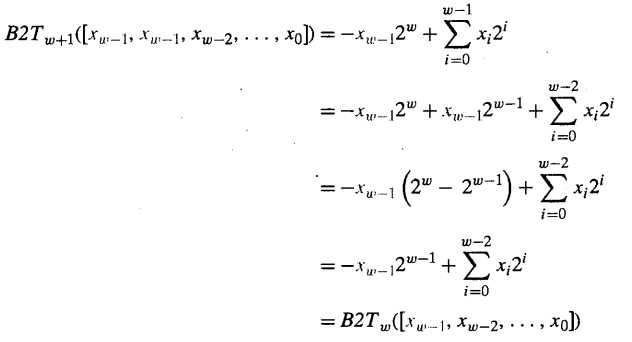
上面的证明我们只需要知道:2w-2w-1=2w-1 即很好理解了。
- 13.在采用补码运算的32位机器上,下列表达式的结果为0的是(C)
A .
-2147483647-1 == 2147483647U
B .
-2147483647-1 < 2147483647
C .
-2147483647-1U < 2147483647
D .
-2147483647-1 < -2147483647
解析: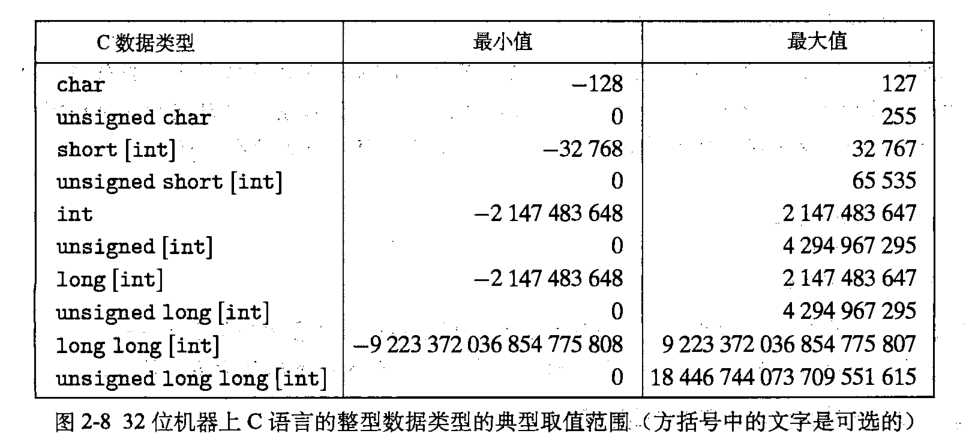
尽管 C 语言标准没有指定有符号数要采用某种编码表示,但是几乎所有的机器都使用补码。通常大多数数字是默认有符号的,比如当声明一个像12345或者0xABC这样的常量的时候,这个值就被认为是有符号的。
- 14.short int v=-12345;
unsigned short uv=(unsigned short) v;
那么(AB))
A .
v=-12345, uv=53191
B .
v=uv=0xcfc7
C .
v,uv的底层的位模式不一样
D .
v,uv的值在内存中是不一样的
解析:在 信息的存储和表示 这篇博客中我们讲过计算机在解释一个数据类型的值时主要有四个因素:位排列规则(大端或者小端)、起始位置、数据类型的字节数、数据类型的解释方式。对于特定的系统来说,前两种因素都是特定的,而对于后两种因素的改变,则可以改变一个数据类型的值的最终计算结果,这就是强制类型转换。
那么考虑相同整数类型的无符号编码和补码编码,数据类型的大小是没有任何变化的,变化的就是它们的解释方式。比如1000这个二进制序列,如果用无符号编码解释的话就是表示8,而若采用补码编码解释的话,则是表示-8。
①、有符号数强转为无符号数
前面我们说过:无论是无符号编码还是补码编码,其映射方式都是双射,因此它们都一定存在逆映射。如果我们定义U2Bw(x)为B2Uw(x)的逆映射,则对于任意一个整数x,如果0 =< x < 2w,经过U2Bw(x)的计算之后,将得到唯一一个二进制序列。同样的,如果我们定义T2Bw(x)为B2Tw(x)的逆映射,则对于任意一个整数x,如果-2w-1 =< x < 2w-1,经过T2Bw(x)的计算之后,也将得到唯一一个二进制序列。
- 15.B2T([1100])= (B)
A .
12
B .
-4
C .
3
D .
以上都不对
解析::当最高位为1,其余为全部是 0 的时候,即【1000......000】,表示补码格式的最小值:
TMinw = -2w-1
当最高位为 0,其余为全部是 1 时,即【0111......111】,表示补码格式的最大值:
TMaxw = 1 * (1 - 2w-1) / 1 - 2 = 2w-1-1
通过上面的两个公式,我们就很好理解为什么上面C语言数据类型负数的范围要比正数的范围大1。
和上面无符号编码一样,我们对于补码格式编码也可以得到一个结论:
对于任意一个w位的二进制序列,都存在唯一一个介于-2w-1 到 2w-1-1的整数,与这个二进制序列对应。反过来,对于任意介于-2w-1 到 2w-1-1的整数,存在唯一的长度为w二进制序列与其对应。
补码,取反加一
-16.B2U([1100])=( A )
A .
12
B .
3
C .
-4
D .
以上都不对
解析:对于一个无符号编码的数,由 w 位的二进制序列构成,那么它的最小值,即所有位都为 0 ,用位向量表示即:【000......000】。
UMinw = 0
最大值即所有位都为 1,用位向量表示即:【111......111】
UMaxw = 1 * (1-2w) / 1 - 2 = 2w - 1
可以得出一个结论:无符号的二进制,对于任意一个w位的二进制序列,都存在唯一一个整数介于0 到 2w-1之间,与这个二进制序列对应。反过来,在0 到 2w-1之间的每一个整数,存在唯一的二进制序列与其对应。
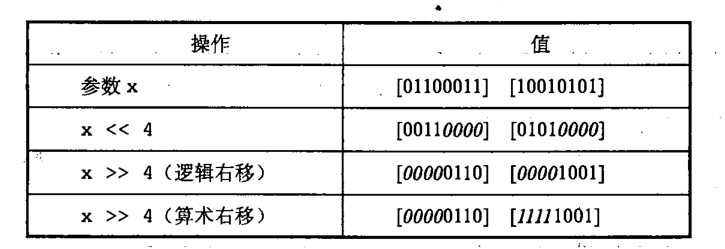
-17.int x; x的二进制为[10010101], x>>4的值为(C)
A .
[10010101]
B .
[00001001]
C .
[11111001]
D .
[01010000]
解析:
右移:运算符是 >>。右移一般机器支持两种形式,逻辑右移和算术右移。
逻辑右移在左端补k 个0。C语言中对于无符号数据必须逻辑右移。
算术右移是在左端补 k 个最高有效位的值。
-18.a=[0010], b=[1100], a||b的值是(A)
A .
非零(TRUE)
B .
[1110]
C .
[0000]
D .
零(FALSE)
解析:C 语言中的位级运算
C 语言是支持按位布尔运算的。也就是我们上面所讲的四种布尔运算符其实也是 C 语言所使用的。在 C 语言中,这些运算符能运用到任何 “ 整型” 的数据类型。也就是声明为 char 或者 int 的数据类型,无论它们有没有 short、long或者 unsigned。下面给出对 char 数据类型表达式求值的例子:
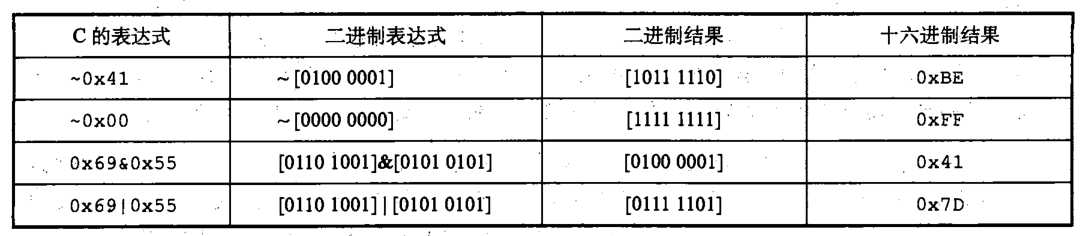
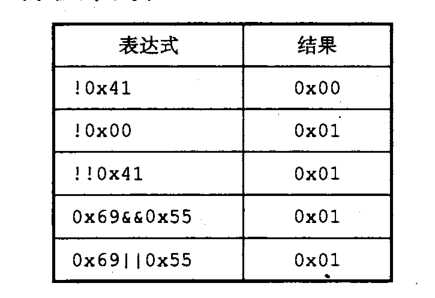
C 语言中的 逻辑运算
C 语言中的逻辑运算符 ||、&&、! ,分别对于命题逻辑中的或、与、非。注意 逻辑运算 和 位级运算 它们的功能是有很大的区别的。
①、逻辑运算认为所有非 0 的参数都表示 true,只有参数 0 表示 false。它们返回 0 或 1 ,分别表示结果 false 和 true。
②、逻辑运算 && 和 || 有短路功能。比如对于表达式 p&&q,p||q,如果p的值可以确定整个表达式的结果,那么将不会计算q的值(q可能是一个表达式)。但是对于p & q则不同,无论p表达式的值为何,都要计算q表达式的值。
-19.a=[0010], b=[1100], a|b的值是(B)
A .
非零(逻辑真)
B .
[1110]
C .
[0000]
D .
零(逻辑假)
解析C 语言中的位级运算
C 语言是支持按位布尔运算的。也就是我们上面所讲的四种布尔运算符其实也是 C 语言所使用的。在 C 语言中,这些运算符能运用到任何 “ 整型” 的数据类型。也就是声明为 char 或者 int 的数据类型,无论它们有没有 short、long或者 unsigned。下面给出对 char 数据类型表达式求值的例子:
C 语言中的 逻辑运算
C 语言中的逻辑运算符 ||、&&、! ,分别对于命题逻辑中的或、与、非。注意 逻辑运算 和 位级运算 它们的功能是有很大的区别的。
①、逻辑运算认为所有非 0 的参数都表示 true,只有参数 0 表示 false。它们返回 0 或 1 ,分别表示结果 false 和 true。
②、逻辑运算 && 和 || 有短路功能。比如对于表达式 p&&q,p||q,如果p的值可以确定整个表达式的结果,那么将不会计算q的值(q可能是一个表达式)。但是对于p & q则不同,无论p表达式的值为何,都要计算q表达式的值。
20.计算机系统的一个基本概念是,从机器角度看,程序仅仅是(B)
A .
字符序列
B .
字节序列
C .
汇编代码序列
D .
ascii码序列
解析:从机器角度看,程序仅仅是字节序列
21.C语言中"0",‘0‘,"\0",0是等价的。(B)
A .
正确
B .
错误
解析: 首先比较一下‘\0’和‘0’的区别。有一个共同点就是它们都是字符,在c语言中,字符是按其所对应的ASCII码来存储的,一个字符占一个字节.第一个ASCII码是0,对应的字符是(Null),其实就是‘\0’,即空字符。判断一个字符串是否结束的标志就是看是否遇到‘\0’,如果遇到‘\0’,则表示字符串结束。而字符‘0’对应的ASCII码是48,48对应的十六进制数就是0x30,通常我们在编程的时候,用字符转化为数字的时候经常要用到,比如要将‘8’转换为数字8,在语句中这样写就可以了,“ 8+‘0’”。这里的8就是数字。字符‘0’和数字0的区别:前者是字符常量,后者是整形常量,它们的含义和在计算机中的存储方式截然不同。但是字符常量可以像整数一样在程序中参与相关运算。
首先“0”是字符串常量,字符串常量是由一对双引号括起的字符序列。例如:“CHINA”,“I LOVE YOU”,“123”等都是合法的字符串常量。‘0’是字符常量,字符串常量和字符常量是不同的量。1:字符常量由单引号括起来;字符串常量由双引号括起来。2:字符常量只能是单个字符;字符串常量则可以含一个或多个字符。这里先介绍表达上的主要区别,在运用中还有存储空间的不同以及赋值方式的不同等等
22.C语言中,字符串被编码为一个以0结尾的字符数组。(A)
A .
正确
B .
错误
解析:在计算机中,对非数值的文字和其他符号进行处理时,要对文字和符号进行数字化,即用二进制编码来表示文字和符号。其中西文字符最常用到的编码方案有ASCII编码和EBCDIC编码。对于汉字,我国也制定的相应的编码方案,比如 GBK,GB2312等。
比如字符 ‘a’ 的 ASCII 码十进制值为 97,在计算机中用二进制表示就是 01100001, null的值是0
23.下面和代码可移植性相关的C语言属性有(ABC)
A .
define
B .
typedef
C .
sizeof()
D .
union
解析:#define可以定义宏使得变量可移植,typedef可以使得类型可移植,sizeof()使得不同类型长度可移植。
24.x=0x12345678,存放在0x200-0x203地址中,小端机器中0x201中的内容是(C)
A .
0x12
B .
0x34
C .
0x56
D .
0x78
解析:在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。
比如:假设一个类型为 int 的变量 x 地址为 0x100,也就是说地址表达式 &x 的值是 0x100,那么,x 的 4 个字节将被存储在存储器的 0x100,0x101,0x102,0x103的位置。
第一个规则解决了,那么第二个规则如何排列呢?采用如下两种方式:
小端法:按照从最低有效字节到最高有效字节的顺序存储对象,也就是最低有效字节在最前面。
大端法:和小端法相反。是按照从最高有效字节到最低有效字节的顺序存储对象,也就是最高有效字节在最前面。 小端机器“高对高,低对低”,大端相反
25.整数int x在内存中的地址是0x200,0x201,0x202,0x203,那么&x的值是(B)
A .
不同机器上(大端,小端)不一样
B .
0x200
C .
0x203
D .
0x200-0x203
解析:对于跨越多个字节的程序对象(程序对象指指令、数据或者控制信息等,是程序当中对象的统称)来说,我们需要制定两个规则:
①、这个对象的地址是什么?
②、在存储器中如何排列这些字节?
在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。
比如:假设一个类型为 int 的变量 x 地址为 0x100,也就是说地址表达式 &x 的值是 0x100,那么,x 的 4 个字节将被存储在存储器的 0x100,0x101,0x102,0x103的位置。
第一个规则解决了,那么第二个规则如何排列呢?采用如下两种方式:
小端法:按照从最低有效字节到最高有效字节的顺序存储对象,也就是最低有效字节在最前面。
大端法:和小端法相反。是按照从最高有效字节到最低有效字节的顺序存储对象,也就是最高有效字节在最前面。对象地址为所用字节中的最小地址
26.与unsigned long等价的声明是(BCD)
A .
unsigned
B .
long unsigned
C .
long unsigned int
D .
unsigned long int
`解析:对关键字的顺序以及包括还是省略可选关键字来说,C语言允许存在多种形式,比如:下面声明都是一个意思
unsigned long
long unsigned
long unsigned int
unsigned long int
27.long类型的长度(A)
A .
不同机器上(32位机,64位机)不一样
B .
固定2字节
C .
固定4字节
D .
固定8字节
解析:计算机和编译器支持多种不同方式编码的数字格式,比如整数和浮点数,以及其它长度的数字。而且由于计算机位数的不同,会造成计算机在各种数据类型分配的字节数不一样。下图是 C 语言在 32位机器和64 位机器上各种类型所分配的字节数对比。
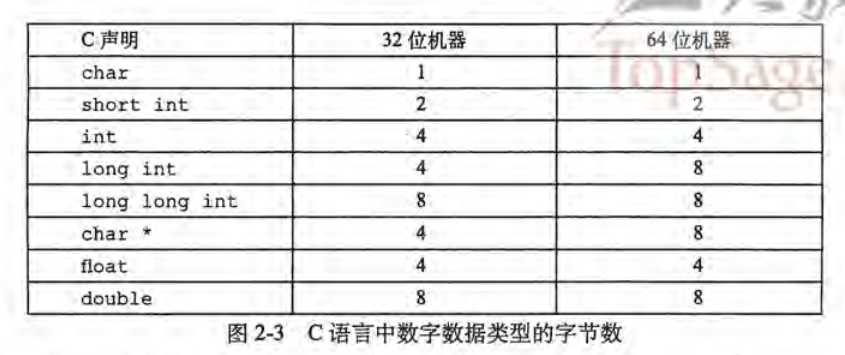
我们可以看出,对于长整形( long int)以及字符指针类型(char *)来说,在32位和64位系统下的字节数是不同的。所以在编程时,考虑到系统的移植性,这是我们必须要考虑的。
注意:对于指针类型,由于指针指向的是地址,而虚拟空间的大小是由字长决定的。所以在32位系统下,指针大小为4个字节,在64位系统下,指针大小为8个字节。
- 28.uint_32的长度是(C)
A .
不同机器上不一样
B .
固定2字节
C .
固定4字节
D .
固定8字节
解析:计算机和编译器支持多种不同方式编码的数字格式,比如整数和浮点数,以及其它长度的数字。而且由于计算机位数的不同,会造成计算机在各种数据类型分配的字节数不一样。下图是 C 语言在 32位机器和64 位机器上各种类型所分配的字节数对比。
我们可以看出,对于长整形( long int)以及字符指针类型(char *)来说,在32位和64位系统下的字节数是不同的。所以在编程时,考虑到系统的移植性,这是我们必须要考虑的。
注意:对于指针类型,由于指针指向的是地址,而虚拟空间的大小是由字长决定的。所以在32位系统下,指针大小为4个字节,在64位系统下,指针大小为8个字节。
- 29.要在64位机器上把prog.c编译出可以在32机器上运行的程序,下面正确的是(C)
A .
64位机上不能编译出32位机的程序
B .
gcc prog.c
C .
gcc -m32 prog.c
D .
gcc -m64 prog.c
解析:大多数64位机器也可以运行32位机器编译的程序,
其命令是
linux>gcc -m32 prog.c
30.字长32位的机器,虚拟地址空间范围是(C)
A .
1-32
B .
0-31
C .
0-2^32-1
D .
1-2^32
解析:字长32位的机器虚拟空间范围
31.0x503c + 64 = (B)
A .
0x50A0
B .
0x507c
C .
0x506C
D .
0x50B0
解析:64是十进制,要化成16进制0x40进行计算。
32.一个数x是2的n次方,n=i+4*j,i=2,j=8时,用16进制表示x,最高位是(B)
A .
2
B .
4
C .
8
D .
0
解析:一个字节由 8 位组成。在二进制表示法中,它的值域为 00000000——11111111;如果用十进制表示就是0——255。这两种表示法用来描述计算机中的位模式(计算机中所有二进制的0、1代码所组成的数字串)来说都不是很方便。二进制表示法太冗长,而十进制表示法与位模式的互相转化又比较麻烦。这时候 十六进制数产生了,十六进制使用数字‘0’~‘9’,以及字符 ‘A’~‘F’来表示16个可能的值。一般是 0x 或者 0X 开头。规则是:借一当十六,逢十六进一。
比如十进制数 175,我们用十六进制表示为 0xAF。
33.实现十进制数向各种进制(2,8,16)的转换,可以使用数据结构中的(B)来实现。
A .
堆
B .
栈
C .
队列
D .
树
解析:在讲进制之前,我们先看一下数制的定义:用一组固定的数字和一套统一的规则来表示数目的方法称为数制。
而数制有进位计数制与非进位计数制之分。非进位计数制的数码表示的数值大小与它在数中的位置无关,这里我们不作过多的介绍。
进位计数制的数码所表示的数值大小则与它在数中所处的位置有关,常见的有二进制、十进制、十六进制,我们这里也只介绍这三种进制的转换。
进位计数制的要素:
①、数码:用来表示进制数的元素。比如二进制数的数码为:0,1。十进制数的数码为:0,1,2,3,4,5,6,7,8,9。十六进制数的数码为:0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F
②、基数:数码的个数。比如二进制数的基数为2。十进制数的基数为10。十六进制数的基数为 16.
③、位权:数制中每一固定位置对应的单位值称为位权。例如十进制第2位的位权为10,第3位的位权为100;而二进制第2位的位权为2,第3位的位权为4,对于 N进制数,整数部分第 i位的位权为N^(i-1),而小数部分第j位的位权为N^-j。
那么我们可以说:每个数码所表示的数值=该数码值 * 所处位置的位权。
34.64位机器上,机器级程序将内存视为(A)数组,称为虚拟内存
A .
字节
B .
字(16位)
C .
双字(32位)
D .
四字(64位)
解析:什么是信息?信息是客观事物属性的反映,是经过加工处理并对人类客观行为产生影响的数据表现形式。
那么我们这里也要提一下什么是数据,数据是反应客观事物属性的记录,是信息的具体表现形式。任何事物的属性都是通过数据来表示的,数据经过加工处理后成为信息,而信息必须通过数据才能传播,才能对人类产生影响。
例如,数据2、4、6、8、10、12是一组数据,其本身是没有意义的,但对它进行分析后,就可得到一组等差数列,从而很清晰的得到后面的数字。这便对这组数据赋予了意义,称为信息,是有用的数据。
计算机内所有的信息均以二进制的形式表示,也就是由值0和值1组成的序列。大多数计算机使用8位的块,或者说字节("位(bit)"是电子计算机中最小的数据单位,每一位的状态只能是0或1。8个二进制位构成1个"字节(Byte)"),来作为最小的可寻址的存储器单位,而不是在存储器中访问单独的位。
也就是说我们访问计算机最小的单位是八个位构成的字节,而不是值0或值1的单个位。
程序会将存储器视为一个非常大的字节数组,称为虚拟存储器(virtual memory)。存储器的每一个字节都由唯一的数字来标识,也就是我们说的地址(address),所有可能地址的集合称为虚拟地址空间(virtual address space)
比如 C 语言中的一个指针的值,无论它是指向一个整数、一个结构或是某个其他程序的对象,都是某个存储块的第一个字节的虚拟地址。
编译器和系统运行时是如何将存储器空间划分为更可管理的单元,用来存放不同的程序对象。这个后面会详细介绍。
35.根据c89国际标准编译程序prog.c,下面正确的是(BC)
A .
gcc prog.c
B .
gcc -ansi prog.c
C .
gcc -std=c89 prog.c
D .
gcc -std=gnull prog.c
解析:在国际c89标准编译程序中有gcc -ansi prog.c,gcc -std=c89 prog.c两条指令完成
36.根据结合律,在大多数计算机上,(3.1415926+1e22)-1e22与3.1415926+(1e22-1e22)的值相等,都是3.1415926.(B)
A .
正确
B .
错误
解析:什么是信息?信息是客观事物属性的反映,是经过加工处理并对人类客观行为产生影响的数据表现形式。
那么我们这里也要提一下什么是数据,数据是反应客观事物属性的记录,是信息的具体表现形式。任何事物的属性都是通过数据来表示的,数据经过加工处理后成为信息,而信息必须通过数据才能传播,才能对人类产生影响。
例如,数据2、4、6、8、10、12是一组数据,其本身是没有意义的,但对它进行分析后,就可得到一组等差数列,从而很清晰的得到后面的数字。这便对这组数据赋予了意义,称为信息,是有用的数据。
计算机内所有的信息均以二进制的形式表示,也就是由值0和值1组成的序列。大多数计算机使用8位的块,或者说字节("位(bit)"是电子计算机中最小的数据单位,每一位的状态只能是0或1。8个二进制位构成1个"字节(Byte)"),来作为最小的可寻址的存储器单位,而不是在存储器中访问单独的位。
也就是说我们访问计算机最小的单位是八个位构成的字节,而不是值0或值1的单个位。
程序会将存储器视为一个非常大的字节数组,称为虚拟存储器(virtual memory)。存储器的每一个字节都由唯一的数字来标识,也就是我们说的地址(address),所有可能地址的集合称为虚拟地址空间(virtual address space)
比如 C 语言中的一个指针的值,无论它是指向一个整数、一个结构或是某个其他程序的对象,都是某个存储块的第一个字节的虚拟地址。
编译器和系统运行时是如何将存储器空间划分为更可管理的单元,用来存放不同的程序对象。这个后面会详细介绍。
37.计算机中用来表有符号整数的编码方式是(B)
A .
无符号编码
B .
补码编码
C .
有符号编码
D .
浮点数编码
解析:补码编码是表示有符号整数的最常见方式。