通过来源审查,访问错误,不支持直接访问:

更改头信息,重新定义 user-agent,模拟浏览器(Mozilla/5.0浏览器标识字段,页面信息不全,可以成功访问):
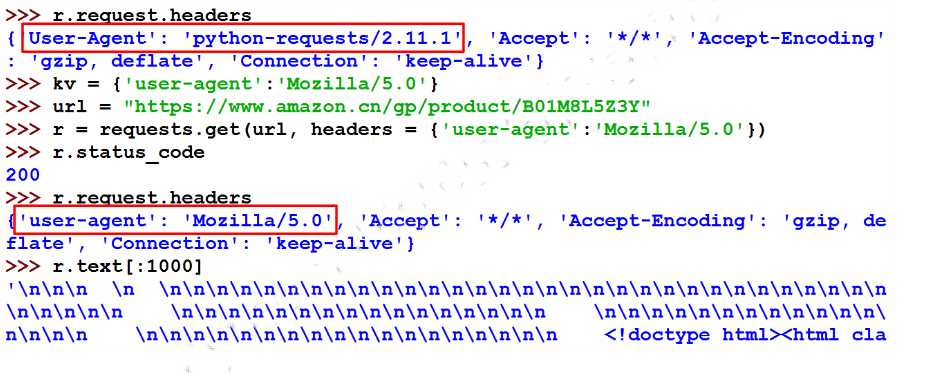
全代码:

import requests
url="https://www.amazon.cn/?tag=baidu250-23&hvadid={creative}&ref=pz_ic_22fvxh4dwf_e"
try:
kv={‘user-agent‘:‘Mozilla/5.0‘}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败!")