Kafka使用背景
在我们大量使用分布式数据库、分布式计算集群的时候,是否会遇到这样一些问题:
我想分析一下用户行为(pageviews),以便我能设计出更好的广告位;
我想对用户的搜索关键词进行统计,分析出前的流行趋势;
有些数据,存数据库浪费,直接存硬盘操作效率又低; 这个时候,就可以用消息系统了,尤其是分布式消息系统
kafka的定义
是一个分布式消息系统,由LinkedIn使用Scala编写,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础,具有高水平扩展和高吞吐量
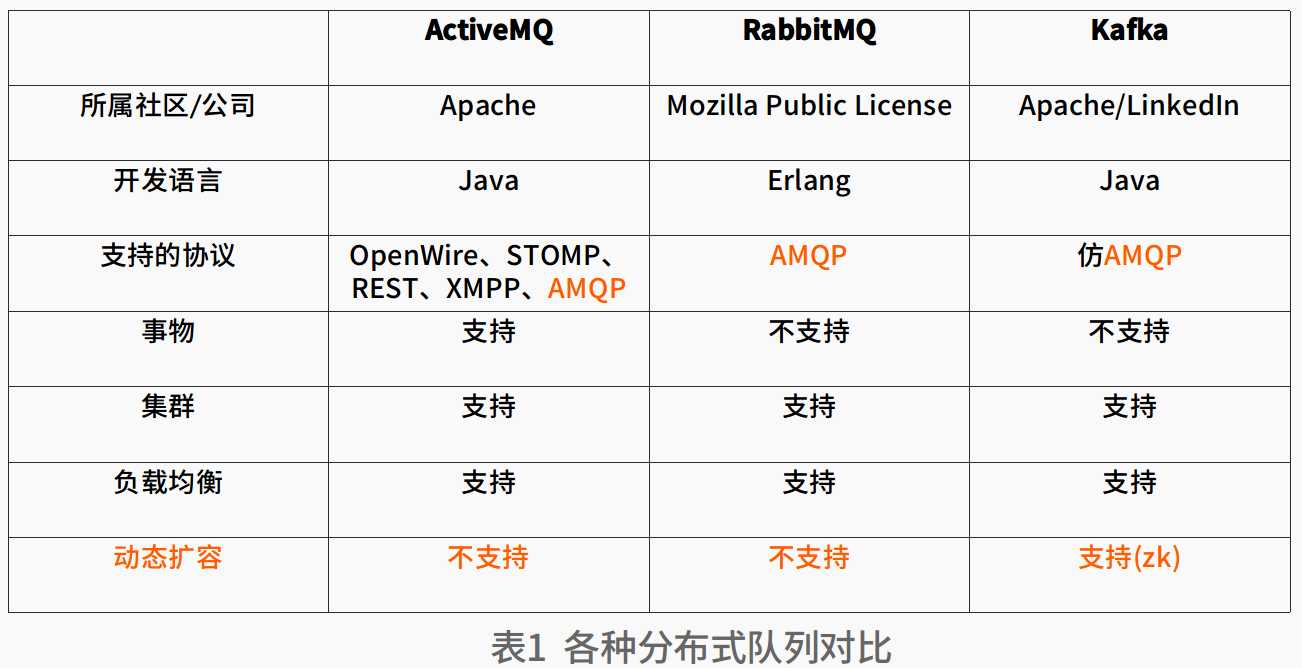
AMQP协议
一些基本的概念:
消费者(Consumer):从消息队列中请求消息的客户端应用程序;
生产者(Producer):向broker发布消息的客户端应用程序;
AMQP服务器端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列;
kafka支持的客户端语言
Kafka 客户端支持当前大部分主流语言,包括: C、C++、Erlang、Java、.net、perl、PHP、Python、Ruby、Go、Javascript。
可以使用以上任何一种语言和kafka服务器进行通信(即编写自己的consumer和producer程序)
kafka架构
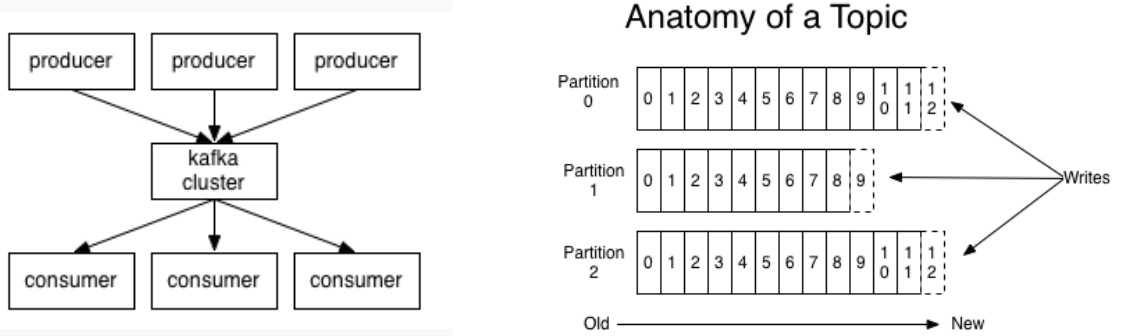
一些基本的概念:
主题(Topic):一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题;
分区(Partition):一个topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看做是一个FIFO的队列;
kafka集群搭建
| c1.heboan.com | 192.168.88.1 | |
| c2.heboan.com | 192.168.88.2 | |
| c3.heboan.com | 192.168.88.3 |
搭建kafka集群至少需要两台机器,而且需要搭建好zookeeper集群(可参考我的另一篇博文),这里我使用上面三台机器,并且已经搭建好了zookeeper集群
以下操作:从下载安装到启动,三台机器都一样,只有配置文件有差异,已经在配置中有说明
下载kafka
wget https://archive.apache.org/dist/kafka/0.8.2.1/kafka_2.9.2-0.8.2.1.tgz tar zxf kafka_2.9.2-0.8.2.1.tgz -C /opt/ ln -s kafka_2.9.2-0.8.2.1 kafka mkdir /data/kafaLogs -p #创建消息持久化存放的目录
修改配置
# cd /opt/kafka/config/ # vim server.properties ... broker.id=0 #88.1设置为0,88.2设置为1,88.3设置为3 port=9092 host.name=192.168.88.1 #改为本机的ip ## Log Basics ### log.dirs=/data/kafkaLogs #指定消息持久化存放的目录 ### Log Retention Policy #### message.max.byte=5048576 #配置每条消息容纳的最大大小,这里设置成5M default.replication.factor=2 #保存消息的副本数 replica.fetch.max.bytes=5048576 #取消息的最大字节数,设置为5M ### Zookeeper ###### zookeeper.connect=192.168.88.1:2181,192.168.88.2:2181,192.168.88.3:2181
配置详解
broker.id=0 当前主机的节点标识 port=9092 对外提供的服务端口 host.name=192.168.88.1 绑定网络接口 num.network.threads=3 网络线程数,一般不需要修改 num.io.threads=8 io线程数 socket.send.buffer.bytes=102400 设置kafka发送消息的缓冲区,先把消息保存在内存,到达一定的数量才发出去,提高性能 socket.receive.buffer.bytes=102400 设置kafka接受消息的缓冲区,当缓存区达到一定的数量的时候才序列化到磁盘 socket.request.max.bytes=104857600 kafka请求或发送消息的最大数,这个数不能超过java的堆栈大小 ### Log Basics #### log.dirs=/data/kafkaLogs #消息的持久化地方,这里可以配置多个以逗号分隔的目录 num.partitions=1 分区数 ## Log Flush Policy #### 这里没有什么需要注意的地方 ## Log Retention Policy ### log.retention.hours=168 消息存储的时间,默认是168小时,即7天,一般不需要修改 message.max.byte=5048576 每条消息容纳的最大大小,默认是1M,即每条消息最大不能超过1M,Z在某些应用中,可能小了,所以改为5M replica.fetch.max.bytes=5048576 #取消息的最大字节数,设置为5M default.replication.factor=2 保存消息的副本数,默认只有一个副本,为了安全,这里改为2 log.segment.bytes=1073741824 消息持久化文件的最大大小,当超过这个大小,就会另起一个文件 log.retention.check.interval.ms=300000 每隔多少ms检查log的失效时间 log.cleaner.enable=false 是否启用log压缩,一般不启用 ############################# Zookeeper ############################# zookeeper.connect=192.168.88.1:2181,192.168.88.2:2181,192.168.88.3:2181 连接的zookeeper集群 zookeeper.connection.timeout.ms=6000 kafka连接zookeeper集群的超时时间
启动
cd /opt/kafka/bin/ ./kafka-server-start.sh -daemon ../config/server.properties 以daemon形式启动并指定配置文件
花絮:
启动的时候,我发现启动不了,主要有一下原因:
1、因为我用的是虚拟机,所以内存设置小了。但是kafka默认设置的jvm启动是1G,导致我启动失败,所以我就修改了kafka-server-start.sh 把jvm调小了
2、因为防火墙的原因导致zookeeper集群连接不正常,也无法启动kafka
到此,集群已经配置完了,现在我们来测试
在88.1机器上
新建一个topic,名字为test
#./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 1 --topic test
列出所有的topic
# ./kafka-topics.sh --list --zookeeper localhost:2181
查看某一个topic为test的信息
# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:2 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
# ./kafka-console-producer.sh --broker-list 192.168.88.1:9092 --topic test
这里输入消息
88.2,88.3机器上
./kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning 这里可以接收到88.1生产的消息
用zookeeper客户端进入zk查看
[root@c3 bin]# cd /opt/zookeeper/bin/
[root@c3 bin]# ./zkCli.sh
