转自:WOM 编码与一次写入型存储器的重复使用 (很有趣的算法设计)——来自 Matrix67: The Aha Moments 大神
计算机历史上,很多存储器的写入操作都是一次性的。 Wikipedia 的 write once read many 词条里提到了两个最经典的例子,一个是大家熟悉的 CD-R 和 DVD-R ,另一个则是更早的打孔卡片和打孔纸带。在介绍后者时,文章里说:“虽然第一次打孔之后,没有孔的区域还能继续打孔,但这么做几乎没有任何实际用处。”因此,打孔卡片和打孔纸带通常也被看成是只能写入一次的存储设备。
事实上真的是这样吗? 1982 年, Ronald Rivest 和 Adi Shamir 发表了一篇题为《怎样重复使用一次写入型存储器》(How to Reuse a “Write-Once” Memory)的论文,提出了一个很有意思的想法。大家有觉得 Ronald Rivest 和 Adi Shamir 这两个人名都很眼熟吗?没错,这两个人之前曾经和 Leonard Adleman 一道,共同建立了 RSA 公钥加密系统。其中, Ronald Rivest 就是 RSA 中的那个 R , Adi Shamir 就是 RSA 中的那个 S 。
在这篇论文的开头, Ronald Rivest 和 Adi Shamir 举了一个非常简单的例子。假设初始时存储器里的所有 bit 全是 0 。存储器的写入操作是单向的,它只能把 0 变成 1 ,却不能把 1 变成 0 。我们可以把存储器里的每 3 个 bit 分为一组,每一组都只表达 2 个 bit 的值,其中 000 和 111 都表示 00 , 100 和 011 都表示 01 , 010 和 101 都表示 10 , 001 和 110 都表示 11 。好了,假设某一天,你想用这 3 个 bit 表示出 01 ,你就可以把这 3 个 bit 从 000 改为 100 ;假设过了几天,你想再用这 3 个 bit 表示出 10 ,你就可以把这 3 个 bit 从 100 改为 101 。事实上,容易验证,对于 {00, 01, 10, 11} 中的任意两个不同的元素 a 、 b ,我们都能找到两个 3 位 01 串,使得前者表示的是 a ,后者表示的是 b ,并且前者能仅仅通过变 0 为 1 而得到后者。因此,每组里的 bit 都能使用两遍,整个存储器也就具备了“写完还能再改一次”的功能。
不可思议的是,两次表达出 {00, 01, 10, 11} 中的元素,其信息量足足有 4 个 bit ,这却只用 3 个 bit 的空间就解决了。这乍看上去似乎有些矛盾,但仔细一想你就会发现,这并没有什么问题。在写第二遍数据的时候,我们会把第一遍数据抹掉,因此总的信息量不能按照 4 个 bit 来算。利用这种技术,我们便能在 300KB 的一次写入型存储器里写入 200 KB 的内容,再把这 200KB 的内容改写成另外 200KB 的内容。这听上去似乎是神乎其神的“黑科技”,然而原理却异常简单。
由于“一次写入型存储器”(write-once memory)的首字母缩写为 WOM ,因此重复多次使用一次写入型存储器的编码方案也就叫做 WOM 编码了。上面展示的编码系统就是一个 WOM 编码,它可以重复 2 次利用 3 个 bit 的空间,每次都能写入 2 个 bit 的数据。 Ronald Rivest 和 Adi Shamir 把这个 WOM 编码扩展为了一系列更大的 WOM 编码,使得我们能重复 2k – 2 + 1 次利用 2k – 1 个 bit 的空间,每次都能写入 k 个 bit 的数据。不妨让我们以 k = 5 为例,对此做一个简单的介绍吧。
所以,我们现在要说明的就是,如何重复 9 次利用 31 个 bit 的空间,每次都能写入 5 个 bit 的数据。首先,把这 31 个 bit 的位置分别编号为 00001, 00010, 00011, …, 11110, 11111 。然后我们规定,一个 31 位 01 串究竟表示哪 5 个 bit ,就看数字 1 的位置编号全都合在一起,各个位置上究竟有奇数个 1 还是偶数个 1 。假设某个 31 位 01 串的第 1 位、第 3 位和第 31 位是 1 ,其余的地方都是 0 。把这 3 个位置的编号列出来,就得到 00001, 00011, 11111 。在这 3 个编号中,左起第 1 位上的数字 1 共有 1 个,左起第 2 位上的数字 1 共有 1 个,左起第 3 位上 1 个,左起第 4 位上 2 个,左起第 5 位上 3 个。其中,左起第 1 、 2 、 3 、 5 位上都是奇数个 1 ,左起第 4 位上共有偶数个 1 。因此,这个 31 位 01 串最终表达的值就是 11101 。
我们将会说明,只要这个 31 位 01 串里还有至少 16 个数字 0 ,我们都能把最多两个 0 改成 1 ,使得整个 31 位 01 串转而表达任意一个我们想要的新的值。不妨假设这个 31 位 01 串当前表达的是 11101 ,而我们现在想让它表达 10110 。显然,如果在这个 31 位 01 串中,编号 01011 对应位置上的是数字 0 ,我们把它改成数字 1 就行了。如果在这个 31 位 01 串中,编号 01011 对应位置上的是数字 1 ,这又该怎么办呢?我们可以按照“同-异-同-异-异”的原则,把除了 01011 以外的 30 个编号分成 15 组:
| (00001, 01010) | (00010, 01001) | (00011, 01000) | (00100, 01111) | (00101, 01110) |
| (00110, 01101) | (00111, 01100) | (10000, 11011) | (10001, 11010) | (10010, 11001) |
| (10011, 11000) | (10100, 11111) | (10101, 11110) | (10110, 11101) | (10111, 11100) |
于是,每一组里的两个编号都满足,左起第 1 位一共有 0 个或 2 个数字 1 ,左起第 2 位一共有恰好 1 个数字 1 ,左起第 3 位一共有 0 个或 2 个数字 1 ,左起第 4 位一共有恰好 1 个数字 1 ,左起第 5 位一共有恰好 1 个数字 1 。其实, 01011 本来应该和 00000 配对,但 00000 并不在我们的编号范围里。所以, 01011 也就没在上面的列表里出现。
但别忘了,这个 31 位 01 串里至少有 16 个数字 0 。由于编号 01011 所对应的是数字 1 ,因此所有的数字 0 都落在了上面 30 个编号上,其中必然会有两个数字 0 落到了同一组里。把这两个 0 都改成 1 ,整个 31 位 01 串所表达的值就能从 11101 变为 10110 了。
初始时,这个 31 位 01 串为 000…00 。只要里面还有至少 16 个数字 0 ,我们就可以对数据进行改写。第一次改写显然只需要把一个 0 变成 1 即可,今后的每次改写也最多只会把两个 0 变成 1 。因此,这个 31 位 01 串可以被我们重复使用 9 次。根据同样的道理,一个 2k – 1 位 01 串就能被我们重复使用 2k – 2 + 1 次,每次写入的都是 k 个 bit 的数据。这正是由 Ronald Rivest 和 Adi Shamir 扩展出来的 WOM 编码,它对于一切大于等于 2 的整数 k 都适用。之前那个把 300KB 当两个 200KB 用的“黑科技”,其实不过是 k = 2 时的一个特例罢了。
随着 k 值的增加,这个科技是“越来越黑”呢,还是“越来越不黑”呢?在这类 WOM 编码中,我们可以把每 2k – 1 个 bit 当作 k · (2k – 2 + 1) 个 bit 来用,其比值为 k · (2k – 2 + 1) / (2k – 1) 。这个比值越高,就代表每个 bit 的利用率越高。当 k = 2 时,这个比值只有 1.333… ;当 k = 5 时,这个比值为 1.4516… ;当 k = 10 时,这个比值增加到了 2.51222… 。可见,这个科技是“越来越黑”的。事实上,我们有 (2k – 2 + 1) / (2k – 1) > 2k – 2 / 2k = 1 / 4 ,因此不管 k 是多少,整个比值都大于 k / 4 了。这立即证明了,在 WOM 编码中,单个 bit 的利用率可以达到任意大。
不过, k / 4 虽然成为了一个下界,但同时也成为了一个“槛”。当 k = 20 时,单个 bit 的利用率为 5.00002384… ;当 k = 50 时,单个 bit 的利用率为 12.5000000000000555… 。随着 k 的增加,单个 bit 的利用率最终稳定在了 k / 4 的水平。单个 bit 的利用率能超越 k / 4 的水平吗?能!
我们可以让每个编号下都有多个 bit 。例如,我们干脆用 3100 个 bit 的存储空间来表示 5 个 bit 的值,其中前 100 位的编号都是 00001 ,下 100 位的编号都是 00010 ,等等。为了确定出这个 3100 位 01 串究竟表达了哪 5 个 bit 的值,我们就要先找出哪些编号所对应的 100 位 01 串里含有奇数个数字 1 ,再把这些编号全都合在一起,看看各个位置上究竟有奇数个 1 还是偶数个 1 。编码过程也就变得更简单了。刚开始,这个 3100 位 01 串全是 0 ,代表的值也就是 00000 。如果你想写入数据 00010 ,即对左起第 4 位取反,你就把编号为 00010 的那 100 个 bit 中的其中一个 0 改成 1 ;如果你想把它改写成 01101 ,即对左起第 2 位、第 3 位、第 4 位、第 5 位都取反,你就把编号为 01111 的那 100 个 bit 中的其中一个 0 改成 1 ;如果你想再把它改写成 01111 ,即再次对左起第 4 位取反,你就从编号为 00010 的那 100 个 bit 中再选一个 0 ,并把它改成 1 ……但是,这种新的 WOM 编码方案没什么实质性的意义,重复写入次数成倍增加了的同时,所用的存储空间也成倍增加了,单个 bit 的利用率仍然没有提高。这里面有个原因:频繁用到某个编号,对应的数字 0 将会很快用光。为了解决这个问题,我们再出奇招:允许用户根据需要给某个编号里再“充”一些的 0 。把这些想法结合起来,我们就得到了一类更加“黑”的“表格式 WOM 编码”。
我们列一个大表格,表格里一共有 100 行,每一行都是 105 个 bit ,其中前 5 个 bit 表示编号,后 100 个 bit 则用于标记这个编号是否被选中,有奇数个数字 1 代表该编号要选,有偶数个数字 1 代表该编号不选。所有选中的编号里,各个位置上究竟有奇数个 1 还是偶数个 1 ,就决定了这 10500 个 bit 的存储空间究竟表达了哪 5 个 bit 的值。每次改写本质上都是选中某个没选中的编号,或者取消掉某个选中了的编号。如果这个编号所在的行里还有空余的 0 ,我们只需要把其中一个 0 改成 1 即可;如果这个编号所在的行都满了,或者整个表格里根本还没出现这个编号(比如初始时),我们就把新的一行的前 5 个 bit 设为这个编号,再把它后面的某个 0 改成 1 。注意到,所有可能的编号也就只有 00001, 00010, …, 11111 共 31 种,并且每种编号都是用满一行才会再开一行。这说明,我们每次都能顺利完成改写操作,直到表格中没填满的行不足 31 行为止。在此之前,我们已经成功改写了 (100 – 31) × 100 = 6900 次。总共 10500 个 bit 的存储空间,竟能 6900 次写入 5 个 bit 的数据,可见单个 bit 的利用率为 5 × 6900 / 10500 = 3.2857… 。
进一步增加行数和列数,可以进一步增加单个 bit 的利用率。如果整个表格一共有 r 行,每一行里都有 5 + s 个 bit ,我们就能重复使用至少 (r – 31) · s 次,每次都能写入 5 个 bit 的数据。因此,单个 bit 的利用率就是 5 · (r – 31) · s / (r · (5 + s)) 。当 r 和 s 足够大时, (r – 31) / r 会非常接近 1 , s / (5 + s) 也会非常接近 1 ,因而整个分数就会非常接近 5 。类似地,如果把 5 换成更大的 k ,单个 bit 的利用率也就能跟着上升为 k ,这优于之前的那个 k / 4 。
但是,如此高的 bit 利用率,是由极其庞大的存储空间以及极其庞大的重写次数来支撑的,这很难有什么实际用途。在生活中,我们可能更关心的是:为了写入 t 次数据,每次数据量都是 k 个 bit ,至少需要几个 bit 的空间?这个问题分析起来就非常困难了。不妨让我们先从一些最简单的情形出发,一点一点开始探究。为了重复 2 次写入 2 个 bit 的数据,我们可以只用 3 个 bit 的空间(即本文最开始讲到的 WOM 编码);那么,同样是每次写入 2 个 bit 的数据,为了把写入次数从 2 次提升到 3 次,我们需要几个 bit 的空间呢?我们先给出一个下界: 4 个 bit 的空间是不够的。事实上,我们将会证明,当 t ≥ 3 时,要想重复 t 次写入 2 个 bit 的数据,只用 t + 1 个 bit 的空间是办不到的。
首次写入的数据有 00 、 01 、 10 、 11 共四种可能,初始时的 01 串 000…00 最多只能表达其中一种可能,其他情况下我们都必须要往存储器里写数字 1 。不妨假设首次写入数据 a 和数据 b 时,我们必须要往存储器里写数字 1 ,其中 a 和 b 是 {00, 01, 10, 11} 中的两个不同的元素。在这段文字和下段文字中,我们假设,首次写入的总是 a 和 b 之一。那么,下一步改写时写入的有可能是什么呢?首次写入 a 后,接下来我们可以把它改写成 b 、 c 、 d ;首次写入 b 后,接下来我们可以把它改写成 a 、 c 、 d 。这里, c 、 d 是 {00, 01, 10, 11} 中的另外两个不同的元素。这意味着,下一步改写时写什么都有可能。容易看出,今后每次改写时更是写什么的都有了。由于每次改写都会把至少一个 0 改成 1 ,因此这就说明了,不管第 t – 1 次写入的是 {00, 01, 10, 11} 中的哪个元素,存储器里都有至少 t – 1 个 1 。
为了给最后一次改写留下足够的空间,此时存储器里还得有至少两个 0 。如果存储器一共只有 t + 1 个 bit 的空间的话,你会发现这一切都抵得非常死:不管第 t – 1 次写入的是什么,存储器里都只能有恰好 t – 1 个 1 ,并且在最后一次改写时,把其中一个 0 改成 1 ,把另外一个 0 改成 1 ,以及把剩下的两个 0 都改成 1 ,必须正好对应三种可能的改写值。这说明,如果第 t – 1 次写入的是 a ,把剩下的两个 0 都改成 1 就会得到一个与 a 不同的值;如果第 t – 1 次写入的是 b ,把剩下的两个 0 都改成 1 就会得到一个与 b 不同的值;对于 c 和 d 也是同理。因而,当存储器里写满了 1 时,它所表达的值既不能是 a ,也不能是 b ,也不能是 c 和 d 。这个矛盾就表明,存储器里只有 t + 1 个 bit 的空间的话是不够的。
别忘了我们正在探究的问题:同样是每次写入 2 个 bit 的数据,为了把写入次数从 2 次提升到 3 次,我们需要几个 bit 的空间?现在我们知道了, 4 个 bit 的空间是不够的。那么, 5 个 bit 的空间够不够呢?答案是肯定的。我们可以把这 5 个 bit 分成两部分,前面一部分有 2 个 bit ,后面一部分有 3 个 bit 。注意到,利用 2 个 bit 的空间可以写入 1 次 2 个 bit 的数据,利用 3 个 bit 的空间可以写入 2 次 2 个 bit 的数据,按照下面给出的方法把两者结合起来,我们就能利用 5 个 bit 的空间写入 1 + 2 = 3 次数据了。下面,我们将会说明,假设每次所写的数据量都相同,如果重写 t1 次可以用 r 个 bit 的空间办到,重写 t2 次可以用 s 个 bit 的空间办到,那么重写 t1 + t2 次一定可以用 r + s 个 bit 的空间办到。
这看起来似乎非常简单:把 r 个 bit 和 s 个 bit 并排放置,先在前 r 个 bit 里使用前一种子编码系统,把 t1 次重写用光了之后,再在后 s 个 bit 里使用后一种子编码系统,直到把 t2 次重写用光。解码时,我们就视情况只看前 r 个 bit 或者只看后 s 个 bit :如果后 s 个 bit 为空,则解码结果完全以前 r 个 bit 为准;如果后 s 个 bit 里有东西,则解码结果完全以后 s 个 bit 为准。太简单了,不是吗?只可惜,这个办法有个问题。如果在后一种子编码系统中, 000…00 正好对应了某个值(正如本文最开始讲到的 WOM 编码一样, 000 表示 00 ),那么首次往后 s 个 bit 里写数据时就有可能让后 s 个 bit 仍然为空,解码也就出错了。当然,我们可以额外用一个 bit ,专门用来表示刚才是在哪边写的数据。但是,这样我们就用了 r + s + 1 个 bit 的空间了。
那怎么办呢?之前那些奇数个 1 偶数个 1 之类的思路,现在就又派上用场了。我们仍然像刚才那样,前 t1 次都在前 r 个 bit 里写,后 t2 次都在后 s 个 bit 里写,但解码的方法有所变化:假设前 r 个 bit 表示的值为 a ,假设后 s 个 bit 表示的值为 b ,那么所有 r + s 个 bit 表示什么值,就看 a 和 b 的各个位置上的数字 1 的总数的奇偶性。举个例子吧:假如在前一个子编码系统中, 1101 表示的值是 10 ;假设在后一个子编码系统中, 001 表示的值是 11 ;由于 10 和 11 的左起第 1 位上一共有偶数个 1 ,左起第 2 位上一共有奇数个 1 ,因此在整个编码系统中, 1101001 就表示 01 。在编码时,不管是往哪边写东西,我们都只消写入要表达的值和另一边当前表达出的值在哪些位置上有差即可。
由于仅写 1 次 2 个 bit 的数据只需要 2 个 bit 的空间,重复 2 次写入 2 个 bit 的数据只需要 3 个 bit 的空间,因此重复 3 次写入 2 个 bit 的数据就只需要 2 + 3 = 5 个 bit 的空间了。
我们还可以把这种“合成式编码”继续用于 t 值更大的情况。重复 4 次写入 2 个 bit 的数据需要多少个 bit 的空间呢?我们可以把这 4 次拆成 1 次加上 3 次,也可以把这 4 次拆成 2 次加上 2 次,从而得到两种不同的 WOM 编码。前一种需要 2 + 5 = 7 个 bit 的空间,后一种需要 3 + 3 = 6 个 bit 的空间,因而后者更优。类似地,重复 5 次写入 2 个 bit 的数据可以用 2 + 6 = 8 个 bit 的空间办到,也可以用 3 + 5 = 8 个 bit 的空间办到,两者的效果相同。
我们来总结一下目前的发现。不妨用 f(t) 来表示,为了重复 t 次写入 2 个 bit 的数据,目前已知的最优方案用了多少 bit 的空间。当 t = 1, 2, 3, 4, 5 时, f(t) 的值分别为:
| t | 1 | 2 | 3 | 4 | 5 |
| f(t) | 2 | 3 | 5 | 6 | 8 |
仅写 1 次 2 个 bit 的数据,显然 1 个 bit 的空间是不够的,我们至少要用 2 个 bit 的空间。为了重复 2 次写入 2 个 bit 的数据,显然 2 个 bit 的空间是不够的,我们至少要用 3 个 bit 的空间。回想我们之前证明过的结论:当 t ≥ 3 时,要想重复 t 次写入 2 个 bit 的数据,只用 t + 1 个 bit 的空间是办不到的,我们至少需要 t + 2 个 bit 的空间。不妨用 g(t) 来表示,为了重复 t 次写入 2 个 bit 的数据,目前已知的理论最少所需空间是多少 bit 。当 t = 1, 2, 3, 4, 5 时, g(t) 的值分别为:
| t | 1 | 2 | 3 | 4 | 5 |
| g(t) | 2 | 3 | 5 | 6 | 7 |
容易看出,当 t = 1, 2, 3, 4 时,上界与下界是一致的,对应的最优化问题也就有了圆满的回答。但是, t = 5 时的情形就不尽人意了:我们有了一种只使用 8 个 bit 的方案,但只证明了 7 个 bit 是必需的。那么,究竟是我们给出的方案还不够好,还是我们证明的结论还不够强呢?
Ronald Rivest 和 Adi Shamir 给出了 t = 5 时的一种只需要 7 个 bit 的编码方案,从而把 t = 5 时的情形也完美地解决了。
为了说明这种新的编码是怎么工作的,我们不妨先讲一下它的解码过程。我们把这 7 个 bit 看作一个 7 位 01 串,假设它是 abcdefg 。如果这个 01 串中,数字 1 的个数小于等于 4 ,则按照下述过程确定整个 01 串所表达的值。
- 初始值为 00 。
- 如果 ab 为 10 ,则左边那一位取反。
- 如果 ab 为 11 ,并且 cd 或 ef 之一为 01 ,则左边那一位取反。
- 如果 cd 为 10 ,则右边那一位取反。
- 如果 cd 为 11 ,并且 ab 或 ef 之一为 01 ,则右边那一位取反。
- 如果 ef 为 10 ,则左右两位都取反。
- 如果 ef 为 11 ,并且 ab 或 cd 之一为 01 ,则左右两位都取反。
如果数字 1 的个数大于 4 ,则按照下述过程确定整个 01 串所表达的值。
- 如果 a 、 c 、 e 、 g 中有偶数个 1 ,则左边那一位为 0 。
- 如果 a 、 c 、 e 、 g 中有奇数个 1 ,则左边那一位为 1 。
- 如果 b 、 d 、 f 、 g 中有偶数个 1 ,则右边那一位为 0 。
- 如果 b 、 d 、 f 、 g 中有奇数个 1 ,则右边那一位为 1 。
然后我们再来叙述一下,如何利用这个 7 位 01 串, 5 次得出任何我们想要表达的值。首先注意到,最开始 abcdefg = 0000000 所表达的值就是 00 。表达一个新的值,本质上就是对当前的值进行下述三种操作之一:左边那一位取反,右边那一位取反,左右两位都取反。接下来我们就来说明,我们可以连续五次实现任何一种取反操作。
在数字 1 的个数小于等于 4 的时候, ab 、 cd 、 ef 各对应一种取反操作。刚开始, ab 、 cd 、 ef 都为 00 。如果把其中一个 00 变为 10 ,就相当于执行了对应的取反操作;如果再把这个 10 变成 11 ,则相当于第二次执行该取反操作(即消除第一次取反的效果);如果再把剩下的某个 00 变成 01 ,则相当于第三次执行该取反操作;如果再把这个 01 也变成 11 ,则相当于第四次执行该取反操作(即消除第三次取反的效果)。注意,取反的标记是 10 ,让别人再次取反的标记是 01 ,我们很容易把两者区分开来。另外, ab 、 cd 、 ef 当中一定是先出现 11 再出现 01 ,并且不会出现两个 11 一个 01 的情况(否则数字 1 的个数就超过 4 个了)。这说明, 01 作为一种辅助性的标记,将会恰好只为一个 11 服务,因而使用时不会产生什么连带的影响。
所以,如果前面四次取反操作中,每种操作最多出现两次,我们只需要相应地做某些 00 → 10 或者 00 → 10 → 11 的修改就行了。如果前面四次取反操作全是同一种操作,我们只需要对相应的 00 做 00 → 10 → 11 的修改,再选一个剩下的 00 做 00 → 01 → 11 的修改。如果前面四次取反操作中,有一种操作出现了三次,另一种操作出现了一次,我们就用 00 → 10 实现那次单独的操作,用 00 → 10 → 11 实现前两次的重复操作,最后一定还剩有一个 00 ,把它变为 01 便能实现第三次的重复操作了。举例来说,假如前面四次取反操作分别是左位取反、两位都取反、左位取反、左位取反,那么我们就把 abcdefg 按照 0000000 → 1000000 → 1000100 → 1100100 → 1101100 的方式修改即可。
不管是哪种情况,前面四次取反操作都各只改变 abcdefg 中的一位。此时, abcdefg 里一共将会有 4 个数字 1 , abcdef 中还有两位是 0 ,而且 g 一定是 0 。在此基础上,任意改动其中一位,都会让 abcdefg 中数字 1 的个数增加到 5 个或 5 个以上,解码方法就变了:解码结果的左位为 0 ,当且仅当 a 、 c 、 e 、 g 中有偶数个 1 ;解码结果的右位为 0 ,当且仅当 b 、 d 、 f 、 g 中有偶数个 1 。现在,我们需要再把某一个或某一些 0 改成 1 ,让整个 7 位 01 串最后一次表达出任意一个我们想要的值。
假设 abcdef 当中,有一个 0 在 a 、 c 、 e 当中,有一个 0 在 b 、 d 、 f 中。无妨假设 a 和 b 都是 0 。那么,不管现在 a 、 c 、 e 、 g 中数字 1 的个数是奇是偶,也不管现在 b 、 d 、 f 、 g 中数字 1 的个数是奇是偶,把 a 改成 1 就能改变前者的奇偶性,把 b 改成 1 就能改变后者的奇偶性,把 g 改成 1 就能同时改变两者的奇偶性,把 a 、 b 、 g 都改成 1 则能保持两者的奇偶性都不变。
假设 abcdef 当中,两个 0 都在 b 、 d 、 f 当中。无妨假设 b 和 d 都是 0 。那么,不管现在 a 、 c 、 e 、 g 中数字 1 的个数是奇是偶,也不管现在 b 、 d 、 f 、 g 中数字 1 的个数是奇是偶,把 b 和 g 都改成 1 就能改变前者的奇偶性,只把 b 改成 1 就能改变后者的奇偶性,把 g 改成 1 就能同时改变两者的奇偶性,把 b 、 d 都改成 1 则能保持两者的奇偶性都不变。当然,如果两个 0 都在 a 、 c 、 e 当中,处理方法也是类似的(其实,两个 0 都在 a 、 c 、 e 当中,这种情况根本不会出现)。
这套 WOM 编码太完美了,对吗?其实,刚才的编码流程里有一个巨大的漏洞,不知道你发现了没有:万一前面四次取反操作中,有一种操作出现了三次,另一种操作出现了一次,并且出现了一次的操作是最后才出现的,那该怎么办呢?举例来说,假如前面四次取反操作分别是左位取反、左位取反、左位取反、两位都取反,那么我们应该怎么做呢?我们可以先把 0000000 变为 1000000 ,再把 1000000 变为 1100000 。接下来,我们应该把某个 00 变为 01 。麻烦的地方来了:我们应该把哪个 00 变为 01 呢?当然,你应该把 cd 从 00 变为 01 ,从而为下一步的“两位都取反”留下空间。但是,你事先怎么知道,下一步是“两位都取反”呢?在不知道这一点的情况下,你有可能不小心把 ef 改为 01 ,此时 7 位 01 串变成了 1100010 ;接下来,你会发现发现下一步是“两位都取反”,需要把 ef 改为 10 ,然后就彻底傻眼了。这该怎么办呢?遇到这种情况时, a 、 c 、 e 当中一定有正好一个 1 , b 、 d 、 f 中一定有正好两个 1 ,并且最后的 g 一定为 0 。我们可以按照下面的指示,把 abcdefg 中的其中两个 0 改为 1 ,从而让整个 7 位 01 串提前进入数字 1 的个数大于 4 的状态,并表达出任何一个我们想要表达的值。
- 如果把 a 、 c 、 e 当中剩下的两个 0 都改成 1 ,整个 7 位 01 串表达的值就是 10 。此时, b 、 d 、 f 当中还有一个 0 ,另外 g 也仍然是 0 ,利用它们就能再表达一个新的值了。不管你是想要左位取反,还是想要右位取反,还是想要两位都取反,都可以通过把其中一个 0 改成 1 或者把两个 0 都改成 1 来实现。
- 如果把 a 、 c 、 e 当中剩下的某一个 0 改成 1 ,再把 b 、 d 、 f 当中剩下的那个 0 改成 1 ,整个 7 位 01 串表达的值就是 01 。此时, a 、 c 、 e 当中还有一个 0 ,另外 g 也仍然是 0 ,利用它们就能再表达一个新的值了。不管你是想要左位取反,还是想要右位取反,还是想要两位都取反,都可以通过把其中一个 0 改成 1 或者把两个 0 都改成 1 来实现。
- 如果把 a 、 c 、 e 当中剩下的某一个 0 改成 1 ,再把 g 从 0 改成 1 ,整个 7 位 01 串表达的值就是 11 。此时, a 、 c 、 e 当中还有一个 0 , b 、 d 、 f 当中也还有一个 0 ,利用它们就能再表达一个新的值了。不管你是想要左位取反,还是想要右位取反,还是想要两位都取反,都可以通过把其中一个 0 改成 1 或者把两个 0 都改成 1 来实现。
- 如果把 b 、 d 、 f 当中剩下的那个 0 改成 1 ,再把 g 从 0 改成 1 ,整个 7 位 01 串表达的值就是 00 。此时, a 、 c 、 e 当中还有两个 0 ,其他地方都没有 0 了。这不足以让我们表达出所有可能的新的值。这可怎么办呢?幸运的是,如果前面四次取反操作中,有一种操作出现了三次,另一种操作出现了一次,所得的值不可能是 00 。这意味着,我们根本就不会碰到要表达出 00 的情况,自然也就不会碰到刚才的难题了。
前面这些杂乱无章的内容,已经唰唰唰地用掉了一万多字。如果你能一字一句地读到这里,那我真的很佩服你。刚才讲过的东西太多了,我们有必要整理一下线索。
不妨用符号 k × t / n 来表示每次写入的数据量为 k 个 bit ,总的写入次数为 t ,存储器空间为 n 个 bit 的 WOM 编码(注意到,这个符号作为一个算术表达式,算出来正好等于该 WOM 编码的单个 bit 利用率)。我们最开始给出了一种 2 × 2 / 3 的 WOM 编码,紧接着把它扩展为了一类 k × (2k – 2 + 1) / (2k – 1) 的 WOM 编码,其中 k 是任意大于等于 2 的正整数。随后,我们进一步把它扩展为了一类 k × ((r – (2k – 1)) · s) / (r · (k + s)) 的 WOM 编码。但我们旋即指出,这样的扩展虽然会带来更高的空间利用率,却因为过于庞大而难以用于实际。
所以,我们转而开始研究另一类更具实际意义,同时也更加困难的问题。不妨用 w(k, t) 来表示所有可行的 k × t / n 当中最小的 n 。那么,当各种正整数 k 和各种正整数 t 组合在一起时, w(k, t) 的值各是多少呢?首先, 2 × 2 / 3 的可行性说明了 w(2, 2) ≤ 3 。紧接着,我们证明了,当 t ≥ 3 时, w(2, t) ≥ t + 2 。随后,我们构造性地证明了 w(k, t1 + t2) ≤ w(k, t1) + w(k, t2) 。利用 w(2, 1) ≤ 2 以及 w(2, 2) ≤ 3 ,我们得出了 w(2, 3) ≤ 5, w(2, 4) ≤ 6, w(2, 5) ≤ 8 。另外,我们不加证明地给出了两个显然成立的结论: w(2, 1) ≥ 2 ,以及 w(2, 2) ≥ 3 。综合所有这些信息,我们得到:
- w(2, 1) = 2
- w(2, 2) = 3
- w(2, 3) = 5
- w(2, 4) = 6
- w(2, 5) = 7 或 8
最后,我们给出了一种 2 × 5 / 7 的 WOM 编码,从而证明了 w(2, 5) = 7 。
寻找 w(k, t) 的精确值果然不是一件易事。我们费了好大的劲儿,结果不但完全没动 k > 2 的情况,就连 k = 2 的情况也只搞出了 5 个准确值。当然,所有的 w(1, t) 显然都等于 t ,所有的 w(k, 1) 显然都等于 k ,因为它们太平凡了,我们一直没提。除此之外,我们能不能再搞出几个新的准确值来呢?
由于 w(3, 1) = 3 ,这说明,要想写入 1 次 3 个 bit 的数据,存储器里至少需要留有 3 个数字 0 。据此容易得出, w(3, 2) ≥ 5 。这是因为,如果存储器里只有 4 个 bit 的话,为了给第 2 次写入数据留下足够的空间,不管第 1 次写入的是什么,我们都最多只能使用 4 个 0 中的 1 个 0 。然而, C(4, 0) + C(4, 1) = 5 < 23 ,这说明,最多只用 4 个 0 中的 1 个 0 ,无法表达出 23种不同的值。因此, w(3, 2) 至少是 5 。
另一方面,只需要简单地把 k1 × t / n1 和 k2 × t / n2 连接起来使用,我们便能得到 (k1 + k2) × t / (n1 + n2) 。这说明, w(k1 + k2, t) ≤ w(k1 , t) + w(k2, t) 。(注意,这和之前的 w(k, t1 + t2) ≤ w(k, t1) + w(k, t2) 是两个不同的结论。)由于 w(1, 2) = 2 , w(2, 2) = 3 ,因而 w(3, 2) ≤ 5 。结合上一段的结论,我们就得到了, w(3, 2) = 5 。
类似地,由于 C(5, 0) + C(5, 1) = 6 < 24 ,这说明 w(4, 2) ≥ 6 ;另一方面, w(4, 2) = w(2 + 2, 2) ≤ w(2, 2) + w(2, 2) = 3 + 3 = 6 。因此, w(4, 2) = 6 。
我们还能继续把 w(5, 2) 的准确值给搞出来吗?试试看吧。由于 C(6, 0) + C(6, 1) = 7 < 25 ,这说明 w(5, 2) ≥ 7 。事实上,由于 C(7, 0) + C(7, 1) + C(7, 2) = 29 < 25 ,这说明 w(5, 2) ≥ 8 。另一方面, w(5, 2) = w(2 + 3, 2) ≤ w(2, 2) + w(3, 2) = 3 + 5 = 8 。因此, w(5, 2) = 8 。
这条路还能走多远?让我们继续。由于 C(8, 0) + C(8, 1) + C(8, 2) = 37 < 26 ,这说明 w(6, 2) ≥ 9 。另一方面, w(6, 2) = w(2 + 4, 2) ≤ w(2, 2) + w(4, 2) = 3 + 6 = 9 。因此, w(6, 2) = 9 。
难不成我们能把所有的 w(k, 2) 的准确值都搞出来?由于 w(1, 2) + w(6, 2) = w(2, 2) + w(5, 2) = w(3, 2) + w(4, 2) = 11 ,因此我们只能得出 w(7, 2) ≤ 11 。要是 C(10, 0) + C(10, 1) + C(10, 2) + C(10, 3) < 27 ,我们就能说明 10 个 bit 的空间不够, w(7, 2) 的准确值也就出来了。只可惜, C(10, 0) + C(10, 1) + C(10, 2) + C(10, 3) = 176 > 27 。刚才的那条路到这里就被堵死了。
在《怎样重复使用一次写入型存储器》中, Ronald Rivest 和 Adi Shamir 说道:“对于较小的 k 和 t ,我们能推导出 w(k, t) 的值,如下表所示。我们尚不知道表中空白处的准确值。”
| k ╲ t | 1 | 2 | 3 | 4 | 5 | 6 |
| 1 | 1 | 2 | 3 | 4 | 5 | 6 |
| 2 | 2 | 3 | 5 | 6 | 7 | |
| 3 | 3 | 5 | 7 | |||
| 4 | 4 | 6 | ||||
| 5 | 5 | 8 | ||||
| 6 | 6 | 9 | ||||
| 7 | 7 |
这个表中的每一项的来历,都是我们刚才讲过的。呃……等等……好像并不是这样…… w(3, 3) 是怎么来的?为什么 w(3, 3) = 7 ?好像就只有这一项是怎么来的我们还不太清楚。
我们首先证明 w(3, 3) ≥ 7 。由于 w(3, 2) = 5 ,这说明,要想写入 2 次 3 个 bit 的数据,存储器里至少需要留有 5 个数字 0 。如果存储器里只有 6 个 bit 的话,为了给后 2 次写入数据留下足够的空间,不管第 1 次写入的是什么,我们都最多只能使用 6 个 0 中的 1 个 0 。然而, C(6, 0) + C(6, 1) = 7 < 23 ,这说明,最多只用 6 个 0 中的 1 个 0 ,无法表达出 23 种不同的值。因此, w(3, 3) 至少是 7 。
但是,不管使用 w(k1 + k2, t) 的构造法,还是 w(k, t1 + t2) 的构造法,我们都只能得出 w(3, 3) ≤ 8 。怎么办呢?别忘了,之前我们还讲过很多其他 WOM 编码,比如一类 k × (2k – 2 + 1) / (2k – 1) 的 WOM 编码。当 k = 3 时,它就成为了一种 3 × 3 / 7 的 WOM 编码。因此,我们有 w(3, 3) ≤ 7 。结合上一段的结论,我们就得到了, w(3, 3) = 7 。 Ronald Rivest 和 Adi Shamir 列出的表格里的所有项,至此就全部解说完毕了。
显然,对 w(k, t) 的探讨远未就此结束,我们还留下了很多的未解之谜。不仅如此, w(k, t) 这个记号本身也还可以推广,比如 k 甚至不一定是整数。在实际应用中,每次写入的数据量并不总是满满的 k 个 bit 。假如我们想要用打孔卡片或者打孔纸带记录英文句子,那么每次写入的就是 26 个英文字母中的一个,数据量也就是 log226 了。容易证明,为了重复使用 2 次纸带,每次写入的都是 26 个字母之一,只用 6 个 bit 的空间是不够的。 Ronald Rivest 和 Adi Shamir 则给出了一种只用 7 个 bit 的方案。为了方便地表示出编码方案,他们把这 26 字母排成了下面这个表格:
| A | H | G | G | F | Y | L | w | E | Z | Y | r | X | f | p | n | D | W | V | z | U | d | j | o | T | w | k | e | l | t | d | u |
| C | S | R | c | Q | i | o | z | P | p | i | h | u | e | x | y | O | z | s | j | s | n | i | w | v | c | q | g | f | k | b | m |
| B | N | M | z | L | b | g | m | K | u | t | b | n | g | f | w | J | w | r | h | k | v | x | y | m | j | p | s | o | q | c | i |
| I | k | m | q | l | c | k | u | w | t | e | o | s | d | j | v | u | d | b | f | g | e | t | p | y | x | n | l | h | r | z | a |
这个表格一共有 4 行,每行的编号分别是 00, 01, 10, 11 ;这个表格一共有 32 列,每列的编号分别是 00000, 00001, 00010, …, 11110, 11111 。每个位置上的字母是什么,则对应的行号与列号相连后,所得的 7 位 01 串就对应哪个字母。其中,大写字母表示第 1 次写入,小写字母表示第 2 次写入。例如, 0011000 表示的就是字母 T ,把它的左起第 1 位、第 2 位、第 5 位改为 1 之后,就能得到 1111100 ,表示的是字母 h 。
WOM 编码是一个很有趣的课题。最后,我们再介绍两种有趣的 WOM 编码,来结束这篇两万字的长文吧。
David Leavitt 给出了一种 log25 × 3 / 5 的 WOM 编码,它可以重复 3 次使用 5 个 bit 的空间,每次写入的都是 5 个符号中的任意一个,其单个 bit 利用率约为 1.393 。不妨把这 5 个符号分别记作 a 、 b 、 c 、 d 、 e 。第 1 次写入时,用 10000 来表示符号 a ;第 2 次写入时,用 01001 和 00110 之一来表示符号 a ;第 3 次写入时,用 01111 、 10110 、 11001 之一来表示符号 a 。其他符号所对应的编码,则是由符号 a 的编码分别向右循环移动 1 位、 2 位、 3 位、 4 位所得。例如, 00110 表示 a ,那么 00011 就表示 b , 10001 就表示 c , 11000 就表示 d , 01100 就表示 e 。对于符号 a 的另外 5 种编码,则也是用这种方法变成其他各个符号的编码。由于 01 串的长度 5 是一个质数,因此循环移动后得到的编码不会发生重复。
| 第 1 次写入 | 第 2 次写入 | 第 3 次写入 | ||||
| a 的编码 | 10000 | 01001 | 00110 | 01111 | 10110 | 11001 |
| b 的编码 | 01000 | 10100 | 00011 | 10111 | 01011 | 11100 |
| c 的编码 | 00100 | 01010 | 10001 | 11011 | 10101 | 01110 |
| d 的编码 | 00010 | 00101 | 11000 | 11101 | 11010 | 00111 |
| e 的编码 | 00001 | 10010 | 01100 | 11110 | 01101 | 10011 |
可以验证,如果第 1 次写入的是 a ,第 2 次想把它改写成 b 、 c 、 d 、 e 都是有办法的;如果第 2 次写入的是 a (不管是哪种形式),第 3 次想把它改写成 b 、 c 、 d 、 e 都是有办法的。再考虑到所有的编码都是循环移动生成的,因此符号 a 能被顺利改写,所有符号都能被顺利改写了。
Frans Merkx 给出了一种 log27 × 4 / 7 的 WOM 编码,它可以重复 4 次使用 7 个 bit 的空间,每次写入的都是 7 个符号中的任意一个,其单个 bit 利用率约为 1.604 。不妨把这 7 个符号分别记作 a 、 b 、 c 、 d 、 e 、 f 、 g 。 Frans Merkx 把它们写成了 7 组,每组三个符号:
| (a, b, d) | (a, c, g) | (a, e, f) | (b, c, e) | (b, f, g) | (c, d, f) | (d, e, g) |
可以验证,每个符号都正好出现在了三个不同的组里,并且对于任意两个符号,都有且仅有一个组同时包含它们。接下来,我们将给大家演示,通过选中越来越多的符号,如何一次又一次地表示新的符号。
- 初始时,所有的符号都没有被选中,因此我们要表示谁就选中谁。
- 如果我们想表示一个新的符号,我们就选中唯一那个和已选中的符号以及这个新的符号共组的符号。如果我们把上一步已选中的符号记作 x ,把这一步想要表示的新符号记作 u ,那么我们这一步就选中那个唯一和 x 、 u 同组的符号 y 。
- 如果我们想再表示一个新的符号,又该怎么办呢?如果这个新的符号是 x ,那么我们就选中任意一个包含 y 但不包含 x 的组里的所有符号;如果这个新的符号是 y ,那么我们就选中任意一个包含 x 但不包含 y 的组里的所有符号;如果这个新符号是除了 x 、 y 的其他符号,那么我们就把这个新符号选中,同时选中唯一那个和 x 、 y 共组的符号(即上一步表示的符号)。不管怎么样,我们都选中了四个符号,其中三个符号形成一组,单独出来的符号就是我们要表示的符号。
- 如果我们想再表示一个新的符号,又该怎么办呢?假设上一步选中的符号是 p 、 q 、 r 、 s ,其中 p 、 q 、 r 是一组, s 是上一步表示的符号。如果我们要表示 p ,就把唯一那个和 p 、 s 同组的符号选中;如果我们要表示 q ,就把唯一那个和 q 、 s 同组的符号选中;如果我们要表示 r ,就把唯一那个和 r 、 s 同组的符号选中;如果我们要表示其他的符号,那这个符号一定没被选中,我们只需把别的符号都选中,只留下这个符号不选即可。
这 7 个符号当中,我们究竟选了哪些符号,这可以用 7 个 bit 来表示。例如, 0100100 就表示我们选中了 b 、 e 这两个符号,别的符号都没选。利用上面给出的方法,我们可以重复四次利用这 7 个 bit ,每次都可以表示 a 、 b 、 c 、 d 、 e 、 f 、 g 这 7 个符号当中任意一个与上次所表示的符号不同的符号。解码时,我们只需要看看这 7 个 bit 里有多少个数字 1 。
- 如果只有 1 个数字 1 ,它表示的就是这个数字 1 所对应的符号。
- 如果有 2 个数字 1 ,它表示的就是唯一与这两个数字 1 所对应的两个符号同组的符号。
- 如果有 4 个数字 1 ,对应的四个符号中一定有三个同组,剩下的那个符号就是它所表示的符号。
- 如果有 5 个数字 1 ,对应的五个符号一定形成了两个组,同在这两个组里的符号就是它所表示的符号。
- 如果有 6 个数字 1 ,它表示的就是唯一那个数字 0 所对应的符号。
有一种几何方法可以直观地表示出这 7 个符号之间的关系。这里,每个符号都用一个点表示,同一组符号所对应的点则都在一条线上(中间那个圆也是一条过三点的线)。
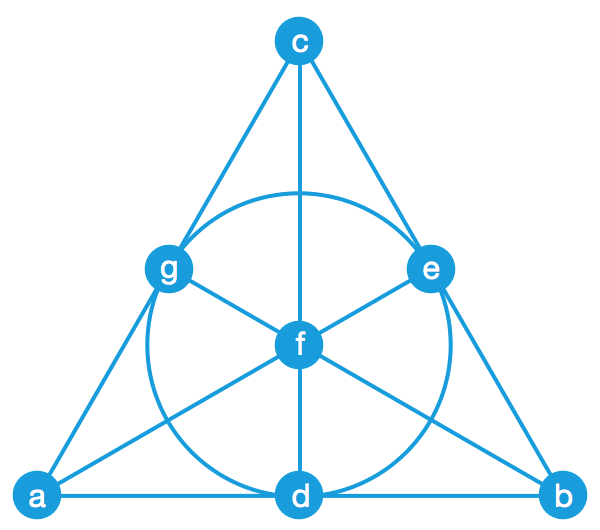
可以验证,每条线上都有三个点,每个点都引出了三条线,并且任意两点之间都有且只有一条线。由于这个结构是射影几何里的经典结构,因此 Frans Merkx 的 WOM 编码也可以看作是射影几何的妙用。