这些年,云计算、大数据的发展如火如荼,从早期的以MapReduce为代表的基于文件系统的离线数据计算,到以Spark为代表的内存计算,以及以Storm为代表的实时计算,还有图计算等等。只要数据规模到了一定的程度,都需要依赖分布式计算来实时或者离线做出决策。虽然本人并未从事相关工作,但是了解一下还是好的。
MapReduce这个词一度是分布式计算的代名词,至少代表了离线计算这一大类大数据编程范式。当提到这个词,可能是指google的论文,或者hadoop的mr实现,也或者是这种编程范式。在本文中,除非特别说明,都是指Google 2004年的论文《MapReduce: Simplified Data Processing on Large Clusters》,这篇论文非常通俗易懂,也没有复杂的概念和算法,值得一读。
在论文中,MapReduce既是一种分布式编程模型(programming model);又是该模型的运行时环境,该环境是为这种编程模型所量身定做的。
MapReduce is a programming model and an associated implementation for processing and generating large data sets.
MapReduce编程模型
前面说MapReduce论文比较容易读懂,原因就是MapReduce的思想很简单。MapReduce分为两个阶段:Map, Reduce。 Map就是把问题划分成独立的组成部分,每一个Map(计算过程)处理独立的一部分数据,分而治之,逐个击破; Reduce就是对Map的结果做一个聚合。
程序员学习每一门语言都是从Hello World开始,分布式计算也有“Hello World”, 那就是WordCount。WordCount就是统计一段文本中每个单词的出现次数,具体计算过程就是先把文本分成M份数据,通过M个并行的map function计算出每一份数据中每个单词的次数,生成结果是一个<key, value>对,key是单词,value是该单词的数量;而reduce function将所有map function的结果按照key进行聚合(相加),结果就是整个文本中每个单词的数目。
我觉得下面这个图更加形象(来源见水印):
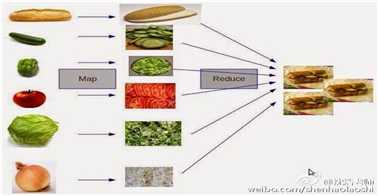
在论文中提到,MapReduce来自函数式编程(如Lisp)的两个算子:map、reduce。函数式编程是与面向对象编程并列的一种编程范式,函数式编程中,函数是一等公民,且支持高阶函数,即以函数作为另一个函数的参数。即使是面向对象的编程语言,也提供函数式编程机制,比如C++中的std::for_each,而对于笔者比较熟悉的Python,也有两个同名、同含义的函数map reduce。下面是python代码
>>> lst = [1, 2, 3, 5, 6]
>>> new_lst = map(lambda e: 2 * e, lst)
>>> new_lst
[2, 4, 6, 10, 12]
>>>
>>> reduced = reduce(lambda total, e : total + e, lst, 0)
>>> reduced
17
指的一提的是,函数式编程的无状态特性,即函数的运行结果只依赖于输入,且不会对外界的环境产生引用,只有输入相同,输出就是确定的,这个特性非常重要,因为在MapReduce编程模型中,会有同一份数据的重复计算,后面会提到。
还有,从对map过程的介绍不难理解,MapReduce只适合线性可并行的计算任务,子任务之间不能有依赖关系,只有这样的计算任务,才能进行拆分,然后通过map并行计算,最终通过reduce进行结果的叠加。主要满足这个条件,都适合用mapreduce模型来计算,如论文中提到的:
- word counting:统计文本中每个单词的数量
- distributed grep:分布式grep
- Count of URL Access Frequency:统计每个url的访问频率
- Reverse Web-Link Graph: 引用关系图
- Inverted Index: 倒排索引
不管是WordCount问题,还是上面“做菜”的例子,大家一看都很简单,完全可以串行执行。但是当数据量到了TB、PB级别,用单台计算机的话得计算到猴年马月,分布式就是要解决单台计算机无法完成的计算任务,每台计算机算一点(map过程),然后将结果汇总起来(reduce过程),这就是分布式计算。
MapReduce运行时环境
前面提到,尽管MapReduce编程模型简单直观,但是由于数据量巨大的问题,必须要使用大量机器进行分布式计算,而分布式本事又是一个复杂且困难的问题。因此,运行时环境(框架)的作用就在于将程序员从分布式的繁枝缛节中解放出来,程序员只需关注本质的问题:数据的计算问题,而不用关心数据是在哪台机器上计算的、怎么计算的。而且由于MapReduce编程模型的普适性,只要将运行环境与计算公式隔离开,就可以复用运行环境,大大提高生产力。
运行时环境是提供给需要进行大量数据计算的程序员使用的,后文统称使用运行时环境的程序员为运行时环境的用户
以Google实现的MapReduce·运行环境为例,运行时环境负责输出数据的拆分、将计算任务在一组节点(计算机)上调度执行、处理节点的故障、以及节点之间的RPC通信。用户只需要提供两个最基本的算子,map function,reduce function即可。
The run-time system takes care of the details of partitioning the input data, scheduling the program‘s execution across a set of machines, handling machine failures, and managing the required inter-machine communication.This allows programmers without any experience with parallel and distributed systems to easily utilize the resources of a large distributed system.
下面是mapreduce框架
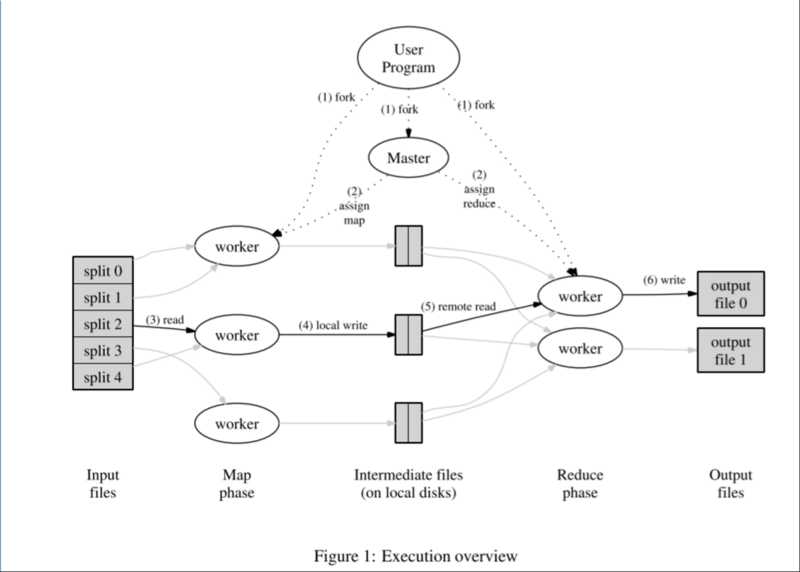
框架中有两类节点(也可以说是进程),Master和Worker,当用户提交一个计算作业(Job)的时候,会启动Job唯一对应的Master进程,Master进程负责整个Job的调度,包括分配worker的角色(map或者reduce)、worker计算的数据,以及向用户返回结果等等。而Worker负责的具体计算称之为task,在MapReduce框架下,worker按照计算的阶段又分为map worker和reduce worker,worker在master获取计算任务,然后在文件系统读取数据进行运算,并将结果写入到临时文件或者持久化文件系统。
一个Job的流程是这样的
- MapReduce将待运算的数据分为M份,每一份的大小为16M或者64M(这个跟默认使用的分布式文件系统GFS有关),每一份数据称之为一个split
- 启动M个map worker,读取相应的split,然后调用用户的Map function,对数据进行运算
- map worker周期性将计算结果(称之为中间结果)写入到R份本地文件中的其中一份,R是reduce worker的数量,具体写入哪一个临时文件 规则由Partitioning function指定
- 当一个map worker计算任务完成的时候,将R份中间结果的位置通知master,master通知对应的reduce worker
- reduce worker根据中间结果的位置,通过rpc从map worker上获取与自己对应的中间结果,进行计算,并将计算结果写入到持久化分布式文件系统,
- 当所有map reduce worker的计算任务结束之后,通知用户计算结果
当然,一个mapreduce的结果并不一定直接给用户,很有可能是一个链式(chain)计算,即将一个mapreduce的输出当做另一个mapreduce的输入
MapReduce优缺点
google MapReduce以及hadoop的开源实现mapreduce(简称hadoop mr1)都是十余年前的产物,虽然已经不能满足现在的很多运算需求,但是还是有很多很好的设计值得学习借鉴。
data locality,即计算离需要的数据存储越近越好,以尽量避免网络传输
fault tolerance,分布式系统中,节点故障是常态,运行环境需要对用户透明地监控、处理故障。由于mapreduce编程模型的线性无状态特性,对于某一个worker的故障,只需将计算任务给其他worker负责就行
backup task,按照木桶定律,即一只水桶能装多少水取决于它最短的那块木板,在mapreduce中,运行最为缓慢的worker会成为整个Job的短板。运行环境需要监控到异常缓慢的worker,主动将其上的task重新调度到其他worker上,以便在合理的时间结束整个Job,提高系统的吞吐。
partitioning function & combiner function,这是用户可以提供的另外两个算子,实时上也是非常有用的。map worker的中间结果,通过partitioning function分发到R(R为reducer的数目)位本地文件,默认为“hash(key) mod R”。而Combiner function是对每一个map worker的结果先进行一次合并(partial merge),然后再写入本地文件,以减少数据传输,较少reduce worker的计算任务。
local execution:本地执行,会提供一个最小化的本地运行环境,以便用户调试、分析自己的代码。这个功能笔者神深有感触,多年前实习的时候使用MapReduce进行数据分析,由于需要排队且自己的优先级比较低,所以一个Job要等个一天才有结果,如果因为一个拼写错误就要重新跑的话简直要崩溃。这个时候就可以先在本地环境用少量数据进行调试,验证。
在google 论文中,也有不足或者没有考虑到的点。
第一:master是单点,故障恢复依赖于周期性的checkpoint,不保证可靠性,因此发生故障的时候会通知用户,用户自行决定是否重新计算。
第二:没有提到作业(Job)的调度策略,运行时环境肯定是有大量的Job并发的,因此多样且高效的调度策略是非常重要的,比如按优先级、按群组
第三:并没有提到资源(CPU、内存、网络)的调度,或者说并不区分作业调度与资源调度。
第四:没有提到资源隔离与安全性,大量Job并发的时候,如何保证单个Job不占用过多的资源,如何保证用户的程序对系统而言是安全的,在论文中并没有提及
第五:计算数据来源于文件系统,效率不是很高,不过本来就是用于离线任务,这个也不是什么大问题
yarn & fuxi
上一章节的最后提到了mapreduce的一些缺陷,包括master单点,资源调度与任务调度职责不明确,只使用与离线数据处理等。随着大数据分析的蓬勃发展,就需要更加多样性的分布式编程范式,比如实时数据处理、内存计算、图计算等等。编程范式的多样化对运行时环境提出了更大的挑战,即运行时环境需要更通用,以支持不同的编程模型,而不是像mapreduce框架那样只支持mapreduce这种编程范式。不同的编程范式,或者说不同的计算任务,对资源(如CPU、内存)的需求是不同的,因此需要优秀的调度策略,在满足应用的特殊需求的情况下,最大化利用资源,同时也需要做好任务之间的隔离,避免相互影响。
在这种需求背景下,就产生了hadoop 2.0 ,主要就是分布式资源调度器Yarn,国内的话比较出名的就是阿里的fuxi系统。二者在架构上非常类似,下面做简单介绍。
需要注意的是,yarn只是hadoop2.0的资源调度器,只负责资源的调度。由于资源调度与任务相互隔离,因此yarn支持更多的分布式计算模型,包括MapReduce,Spark,Storm等。
Yarn的架构如下:
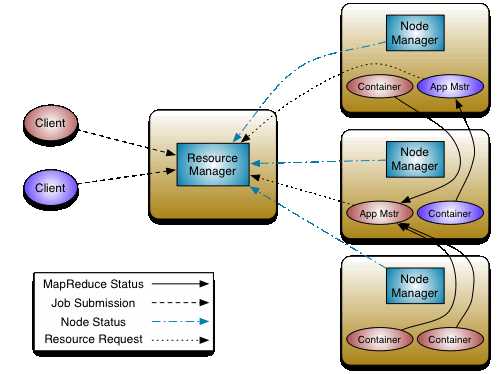
在Yarn中,有以下组件
ResourceManager:资源管理器,接收用户的请求,负载应用(application)的调度管理,启动应用对应的ApplicationMaseter,并为每一个应用分配所需的资源
NodeManager:框架agent,在每一个计算机节点上都有一个,用于本机上的Container,监控机器的资源使用情况,并向ResourceManager汇报
ApplicationMaseter(图中所有为App Mstr),每一个应用都有自己唯一的ApplicationMaseter,用于管理应用的生命周期,向ResourceMananger申请资源,监控任务对应的container
Containner:具体任务task的计算单元,是一组资源的抽象,可用于以后实现资源的隔离
其中,ResourceManager包含两个重要的组件,scheduler和ApplicationManager。scheduler负责为各种应用分配资源,支持各种调度算法,如 CapacityScheduler、 FairScheduler。ApplicationManager负责接收用于的请求,启动应用对应的ApplicationMaseter。
阿里fuxi的架构与Yarn非常类似,如图所示
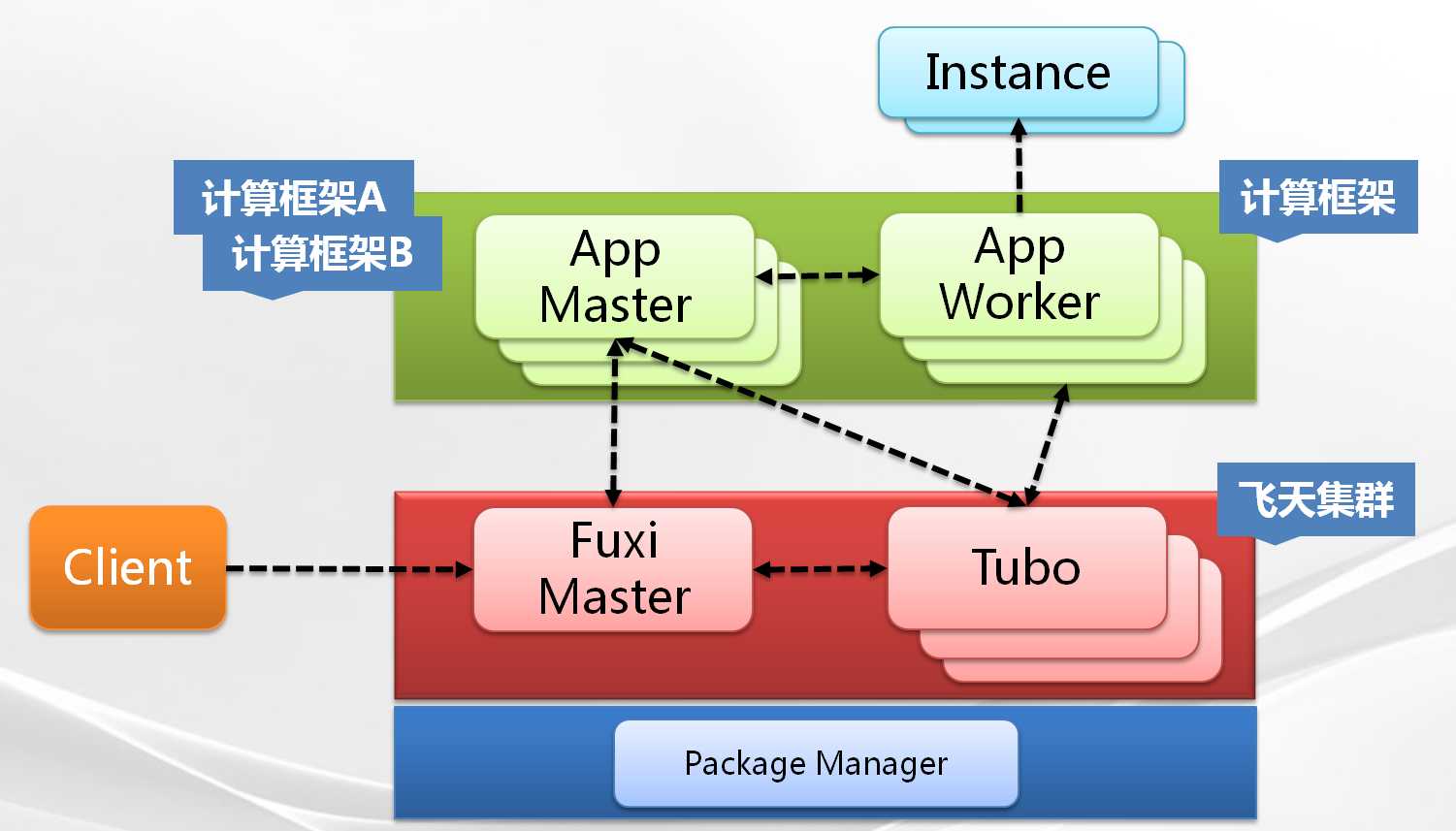
可以看到:
fuxi master对应Resourcemanager
tubo对应NodeManager
AppMaster对应ApplitionMast
AppWorker对应Container
关于阿里的fuxi分布式调度,在阿里云大学和课堂在线都有视频课程,包含了许多细节,如详细的资源调度流程,各种调度策略,容错机制,应用的隔离等,值得看一看。